MMR-Bench:マルチモーダルLLMルーティングのための包括的ベンチマーク
マルチモーダル大規模言語モデル(MLLM)の急速な発展に伴い、モデルごとの能力やコストの不均一性が顕著になっているが、本研究ではクエリごとに最適なモデルを選択して精度とコストのバランスを最適化する「ルーティング」のための包括的ベンチマーク「MMR-Bench」を提案した。
TL;DR(結論)
マルチモーダル大規模言語モデル(MLLM)の急速な発展に伴い、モデルごとの能力やコストの不均一性が顕著になっているが、本研究ではクエリごとに最適なモデルを選択して精度とコストのバランスを最適化する「ルーティング」のための包括的ベンチマーク「MMR-Bench」を提案した。 テキスト情報のみに依存する従来のルーティング手法では、視覚的な複雑さが難易度を左右するマルチモーダルなタスクにおいて適切なモデル選択が困難であったが、画像信号を統合したマルチモーダルな手がかりを活用することで、最強の単一モデルと同等の精度をわずか33%程度のコストで達成できることが実証された。 このベンチマークは11,000件のデータと10種類の主要モデルを網羅したオフライン評価環境を提供し、構築されたルーティングポリシーは未知のデータセットやテキスト専用のタスクに対しても高い汎用性とゼロショット性能を示すことが確認され、効率的なMLLMの展開に向けた重要な基盤を確立した。
なぜこの問題か
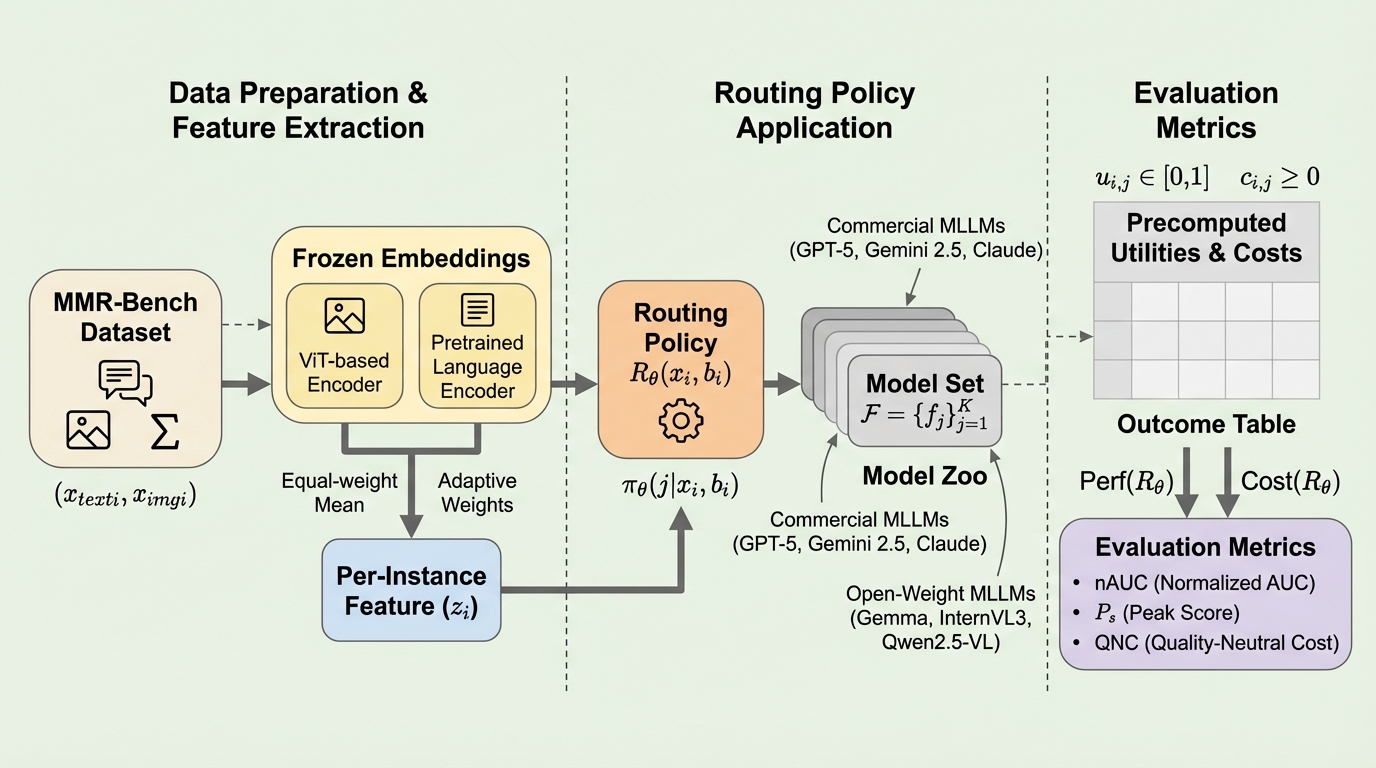
近年のマルチモーダル大規模言語モデル(MLLM)の進歩は目覚ましく、テキスト認識、画像理解、複雑な推論など多岐にわたるタスクで高い能力を発揮している。しかし、現在のMLLMのエコシステムは非常に不均一であり、モデルごとにアーキテクチャ、学習データ、モダリティの整合戦略、そして計算効率が大きく異なっている。この多様性は「MLLMズー(MLLM zoo)」とも呼べる動的な状況を作り出しているが、同時に「あらゆるタスクにおいて一様に優れた単一のモデルは存在しない」という重大な限界を浮き彫りにしている。実際の運用現場では、軽量なOCR処理から高度なマルチモーダル数学推論まで幅広いワークロードが存在するため、すべてのクエリに対して一律に高性能で高価なモデルを使用すると、簡単な問題に対して過剰な計算資源を投入することになり、逆に軽量モデルのみを使用すると困難な問題で精度を犠牲にすることになる。このような精度の維持とコスト削減のジレンマを解決する手段として、クエリ単位で適切なモデルを選択する「ルーティング」が注目されている。…
核心:何を提案したのか
本研究では、マルチモーダル・ルーティングの問題を切り出し、固定された候補モデルセットとコストモデルの下で厳密な比較を可能にする統一ベンチマーク「MMR-Bench」を提案した。このベンチマークは、モダリティを考慮した入力と可変の計算予算を備えた制御された環境を提供し、OCR、一般的な視覚的質問応答(VQA)、マルチモーダル数学推論を含む広範なビジョン・ランゲージ・タスクを網羅している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related