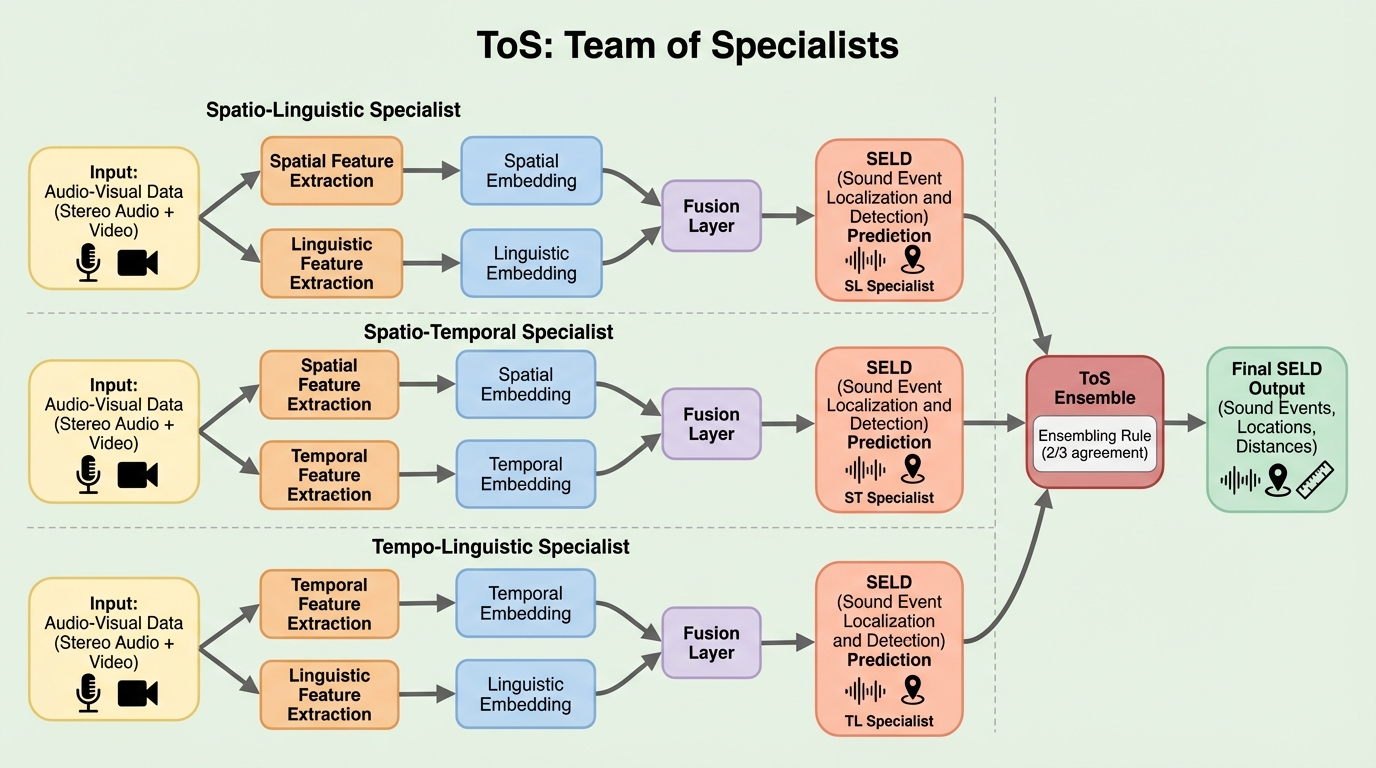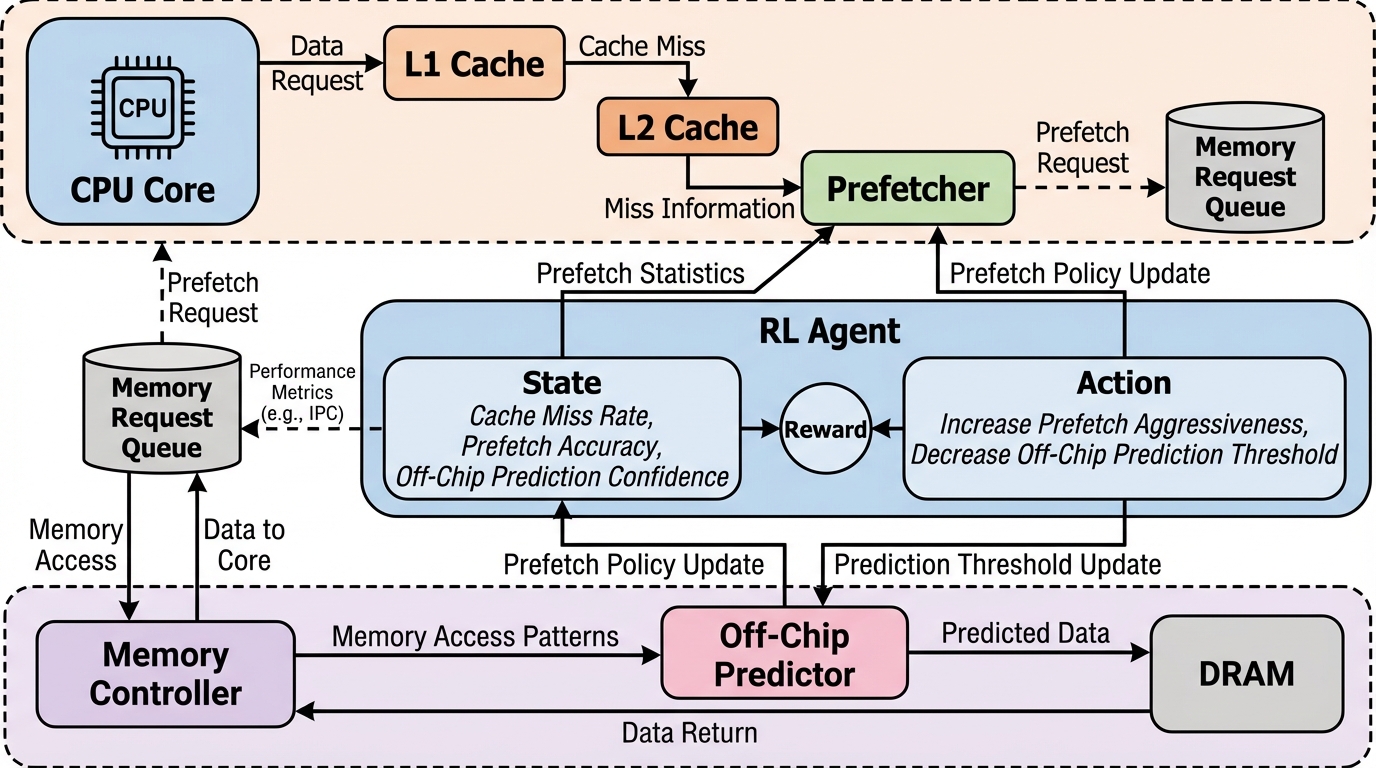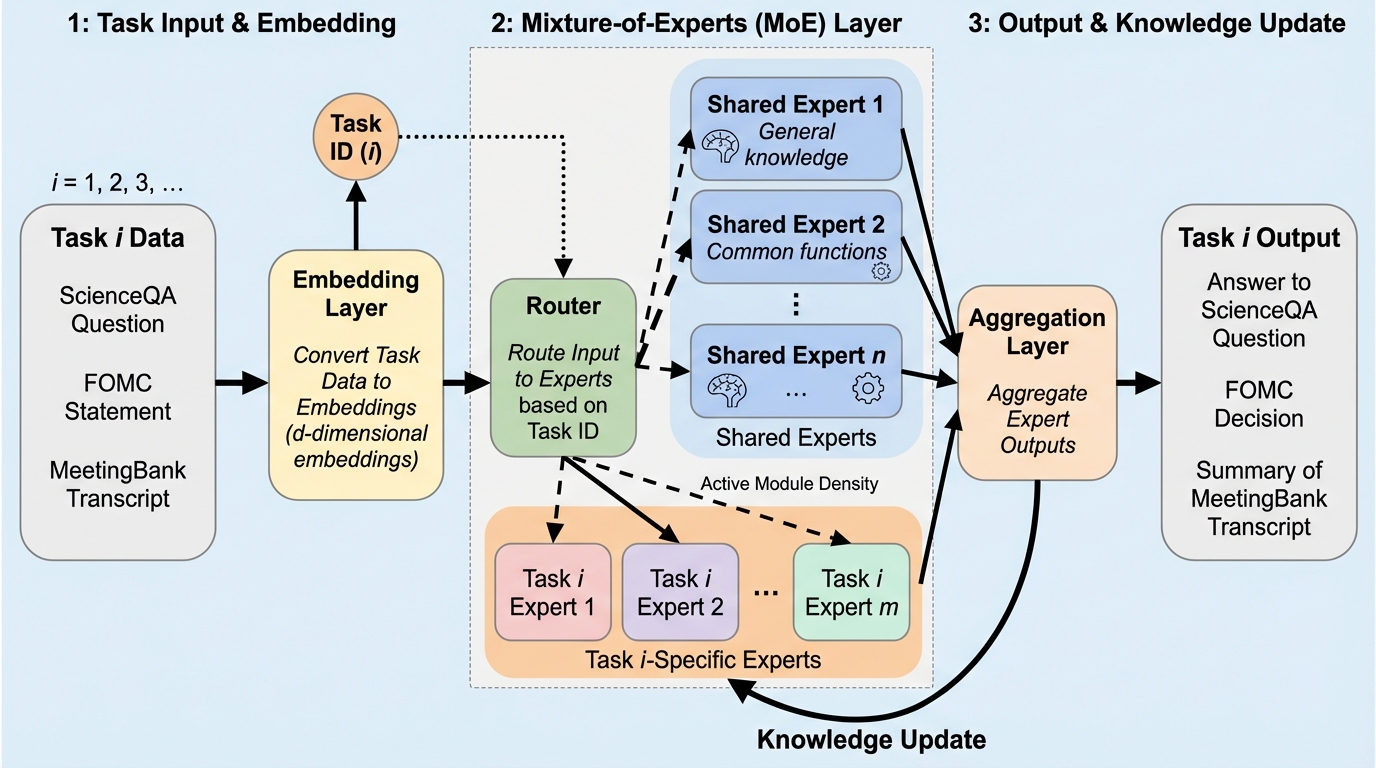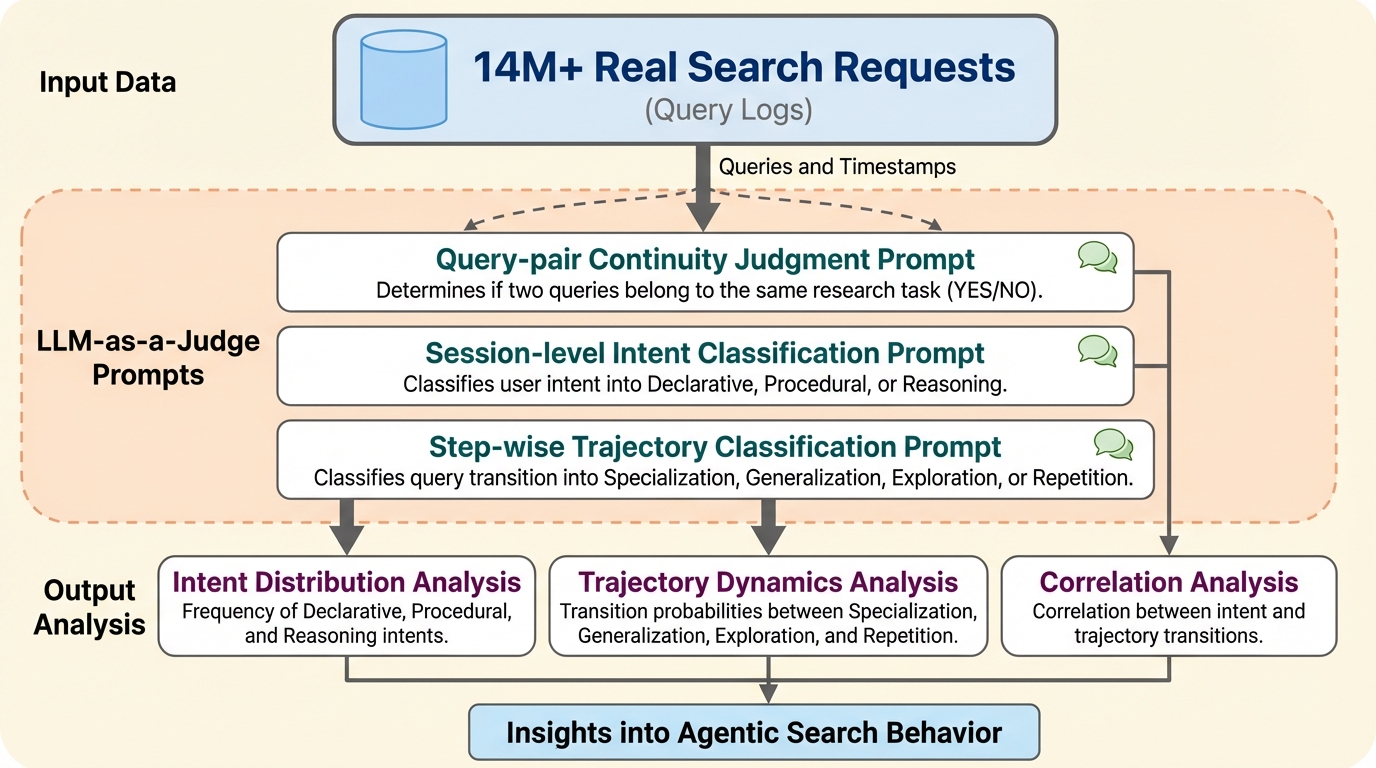
言語モデルが知っているのに言わないこと:汎化のための非生成的事前知識の抽出
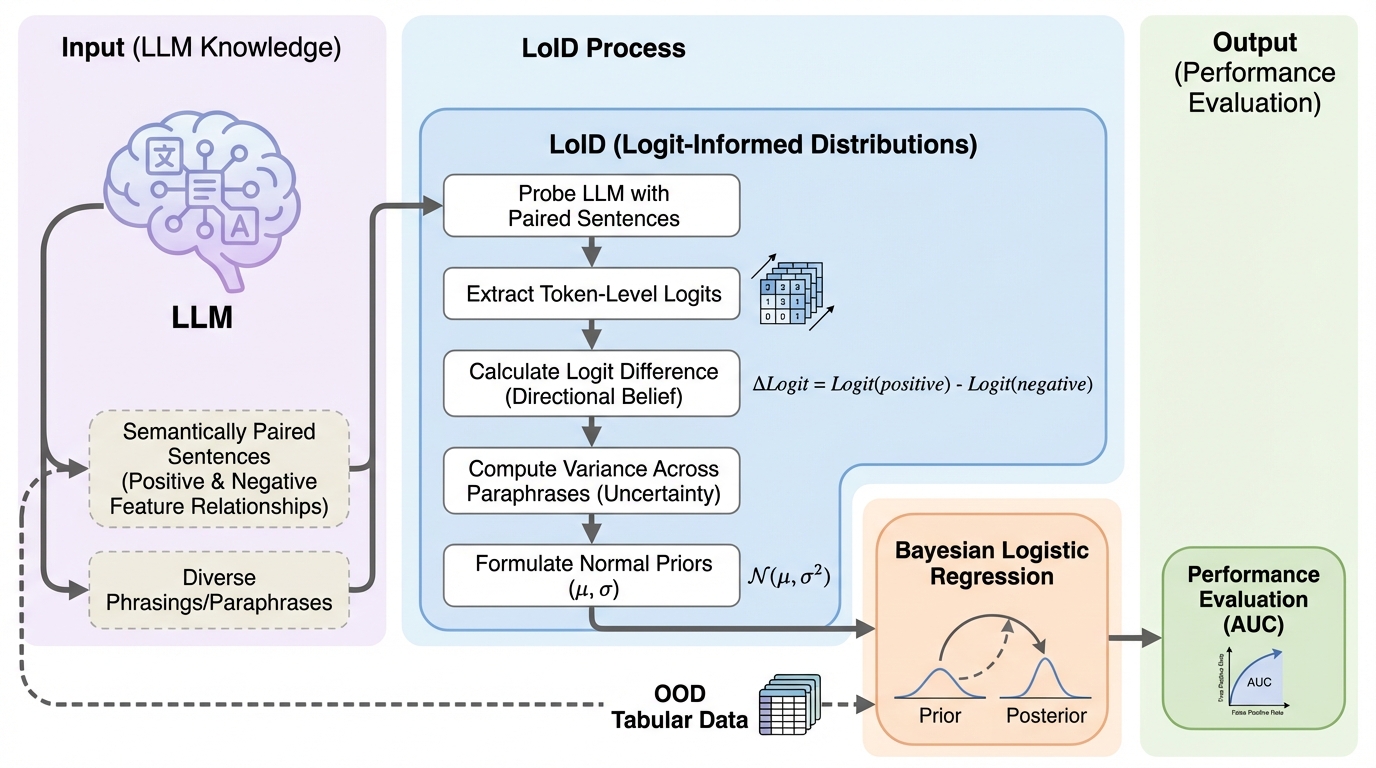
医療や金融分野ではラベル付きデータの収集が困難であり、少数の偏ったデータで学習したモデルは未知のデータ分布に対して汎化性能が著しく低下するという深刻な課題がある。 本研究が提案するLoIDは、大規模言語モデルが内部に持つ知識をテキスト生成ではなくトークン単位のロジットとして直接抽出する決定論的な手法であり、ベイズ統計学の事前分布として統合する。 10種類の公開データセットを用いた検証の結果、LoIDは既存手法を上回る精度を記録し、理想的なモデルとの性能差を最大59%回復させるなど、高い信頼性と計算効率、そして再現性を示した。