実環境におけるエージェンティック検索:1400万件以上の実検索リクエストから見る意図と軌跡のダイナミクス
本研究は、1444万件以上の実検索リクエストと397万件のセッションを含む大規模ログを分析し、自律型エージェントの検索行動を世界で初めて包括的に解明しました。 エージェントの検索意図(事実確認、手続き、推論)によって行動パターンが大きく異なり、特に事実確認では非効率な重複が発生しやすい一方で、推論では広範な探索が行われることを特定しました。 新規クエリ用語の54%が過去の検索結果に由来することを示す新指標「CTAR」を提案し、エージェントがセッション全体を通じて蓄積された文脈をクエリの洗練に活用していることを定量的に証明しました。
TL;DR(結論)
本研究は、1444万件以上の実検索リクエストと397万件のセッションを含む大規模ログを分析し、自律型エージェントの検索行動を世界で初めて包括的に解明しました。 エージェントの検索意図(事実確認、手続き、推論)によって行動パターンが大きく異なり、特に事実確認では非効率な重複が発生しやすい一方で、推論では広範な探索が行われることを特定しました。 新規クエリ用語の54%が過去の検索結果に由来することを示す新指標「CTAR」を提案し、エージェントがセッション全体を通じて蓄積された文脈をクエリの洗練に活用していることを定量的に証明しました。
なぜこの問題か
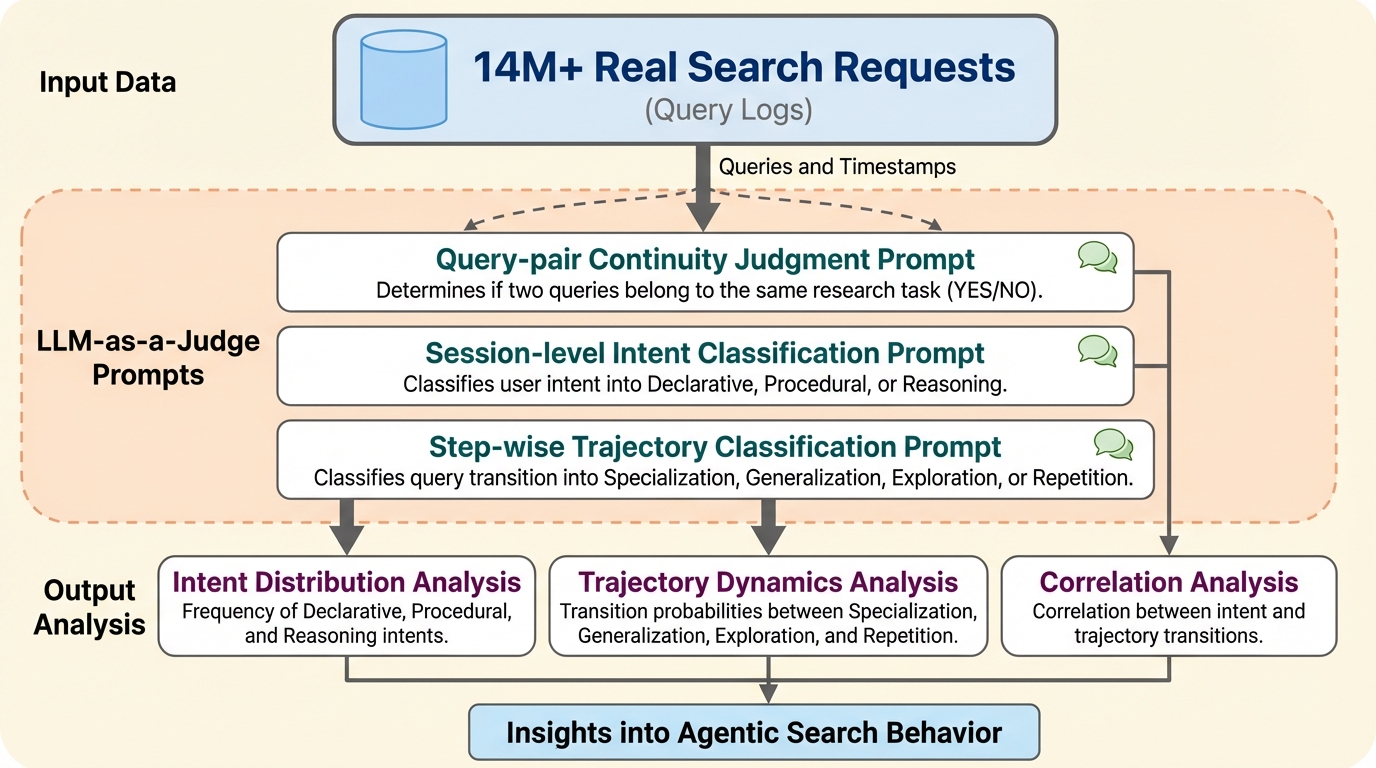
情報検索のパラダイムは、人間が直接検索を行う形態から、大規模言語モデル(LLM)を搭載したエージェントが自律的に計画を立て、複数のステップを経て情報を収集する「エージェンティック検索」へと急速に移行しています。しかし、情報検索(IR)のコミュニティにおいて、これらのエージェントが実際の環境でどのように検索セッションを展開し、取得した証拠をどのように次のアクションに反映させているのかという実証的な理解が決定的に不足していました。既存の研究やベンチマークは、制御された環境下でのスコア測定には長けていますが、エージェントのクエリがステップを追うごとにどのように進化し、検索された文脈がその後の意思決定にどう影響するかという動的なプロセスを捉えきれていません。 実用的なシステム設計の観点からは、エージェントが重複したクエリや狭すぎる検索を繰り返すことでリソースを浪費している可能性や、重要な側面を見落としている懸念があります。また、人間による検索とは異なり、エージェントはプログラムを介して結果を消費するため、従来の行動分析で用いられてきた「クリック」や「滞在時間」といった暗黙的なフィードバック信号が観察できません。…
核心:何を提案したのか
本研究の核心は、オープンソースの検索APIである「DeepResearchGym(DRGym)」から収集された1444万件の検索リクエスト(397万セッション)という、かつてない規模のログ分析を通じて、自律型エージェントの行動を多角的に定義・測定するフレームワークを提案した点にあります。具体的には、エージェントがセッション全体で何を達成しようとしているのかを示す「セッションレベルの意図」と、ステップ間でクエリをどのように変化させているかを示す「軌跡レベルのクエリ再構成」という2つの階層で行動を分類しました。 セッションレベルの意図については、事実確認を行う「宣言的(Declarative)」、方法を実行する「手続き的(Procedural)」、複雑な合成を行う「推論(Reasoning)」の3つのタクソノミーを採用しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related