UrduLM:リソース効率の高い単一言語ウルドゥー語言語モデル
ウルドゥー語は世界で2億3000万人の話者を抱える主要言語ですが、既存の多言語モデルではトークン化の非効率性や文化的な不正確さが課題となっており、専用の生成モデルや高品質なデータセットが不足していました。
TL;DR(結論)
ウルドゥー語は世界で2億3000万人の話者を抱える主要言語ですが、既存の多言語モデルではトークン化の非効率性や文化的な不正確さが課題となっており、専用の生成モデルや高品質なデータセットが不足していました。本研究では、33GBの独自コーパスと、多言語モデルと比較してトークン数を20〜30%削減するカスタムBPEトークナイザーを開発し、100Mパラメータという軽量なデコーダー専用モデル「UrduLM」を構築しました。わずか100ドル未満の予算で訓練されたこのモデルは、感情分析で66.6%の精度を達成し、自身の30倍のサイズを持つ多言語モデルに匹敵する性能を示すとともに、低リソース言語における効率的なモデル開発の枠組みを提示しました。
なぜこの問題か
現代の言語モデル開発における最大の課題の一つは、特定の主要言語、特に英語への極端な偏りです。例えば、広く普及しているLLaMA-2の訓練データにおいて、英語が占める割合は89.70%に達しています。このようなデータの不均衡は、ウルドゥー語のような低リソース言語において深刻な弊害をもたらします。具体的には、モデルが事実に基づかない情報を生成するハルシネーション(幻覚)や、文章の途中で不自然に英語が混ざるコードスイッチングが頻発する原因となります。また、数百の言語を一つのモデルで強引にサポートしようとする多言語モデルには「多言語の呪い」と呼ばれる現象が存在します。これは、モデルの限られた容量が膨大な数の言語に分散されることで、個々の言語に対する深い言語的知識や文脈の理解が希薄化し、結果としてパフォーマンスが大幅に低下するという問題です。 ウルドゥー語は世界で10番目に多く話されている言語であり、2億3000万人以上の話者が存在しますが、専用のトランスフォーマーベースの生成モデルや、精査された大規模なコーパス、標準化されたベンチマークが著しく不足していました。…
核心:何を提案したのか
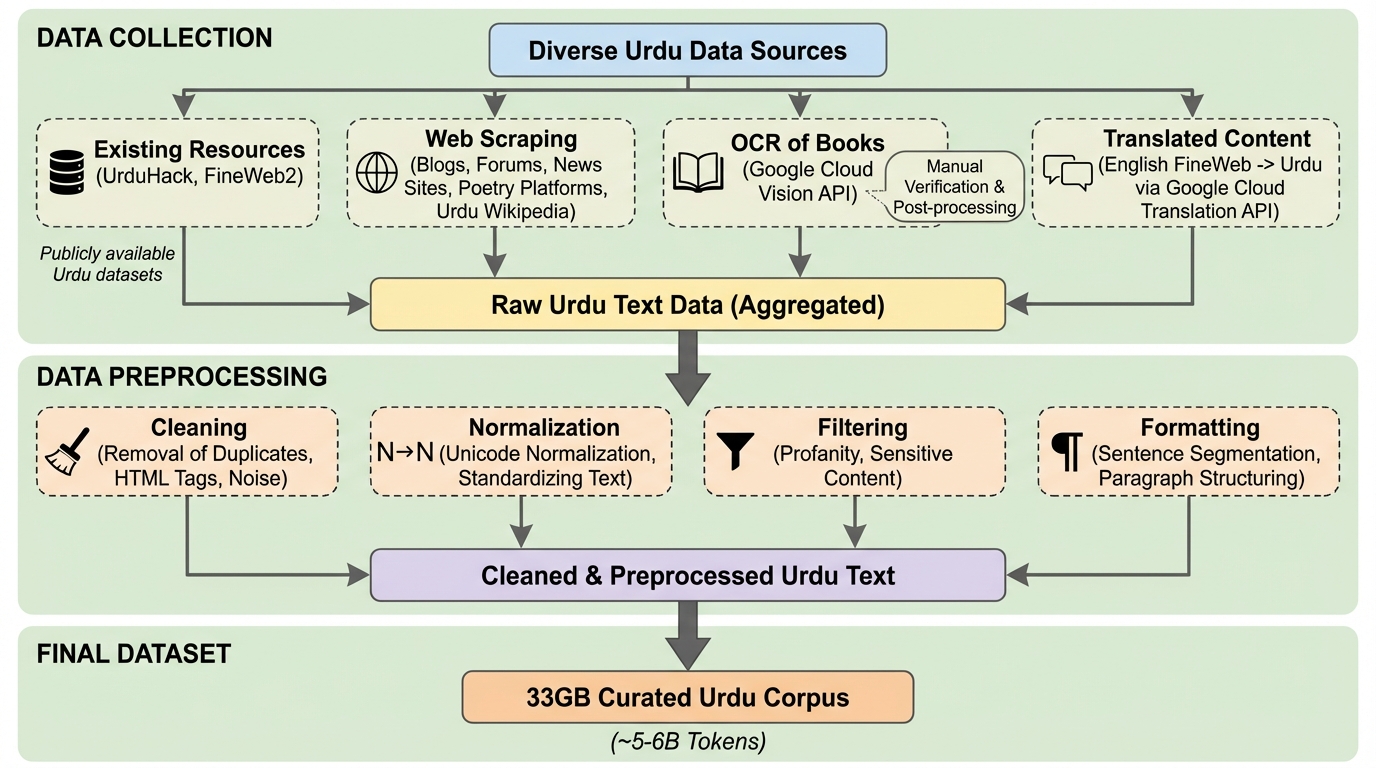
本研究の核心は、計算資源が限られた低リソース設定において、極めて効率的な単一言語LLMを開発するための体系的な手法を確立し、それを具現化した「UrduLM」を提案したことにあります。提案されたUrduLMは、100M(1億)パラメータという非常にコンパクトなデコーダー専用モデルです。このモデルは、計算資源が限られた環境でも訓練可能でありながら、特定のタスクにおいて自身の30倍のサイズを持つ多言語モデルに匹敵する性能を発揮するように設計されています。研究チームは、単にモデルを訓練するだけでなく、データ収集から評価までの一連のパイプラインを再構築しました。 この提案を実現するために、研究チームは以下の4つの主要な貢献を行いました。第一に、ニュース、文学、教育、日常会話など多岐にわたるドメインから収集した33GB(約50億〜60億トークン)の精査済みウルドゥー語コーパスを構築しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related