Split-on-Share:タスク非依存な継続学習のためのスパースな専門家混合モデル
大規模言語モデル(LLM)の継続学習において、新しい知識の習得(可塑性)と過去の知識の保持(安定性)を両立させるため、モデルをモジュール化された部分空間に分解する新フレームワーク「SETA」が提案されました。
TL;DR(結論)
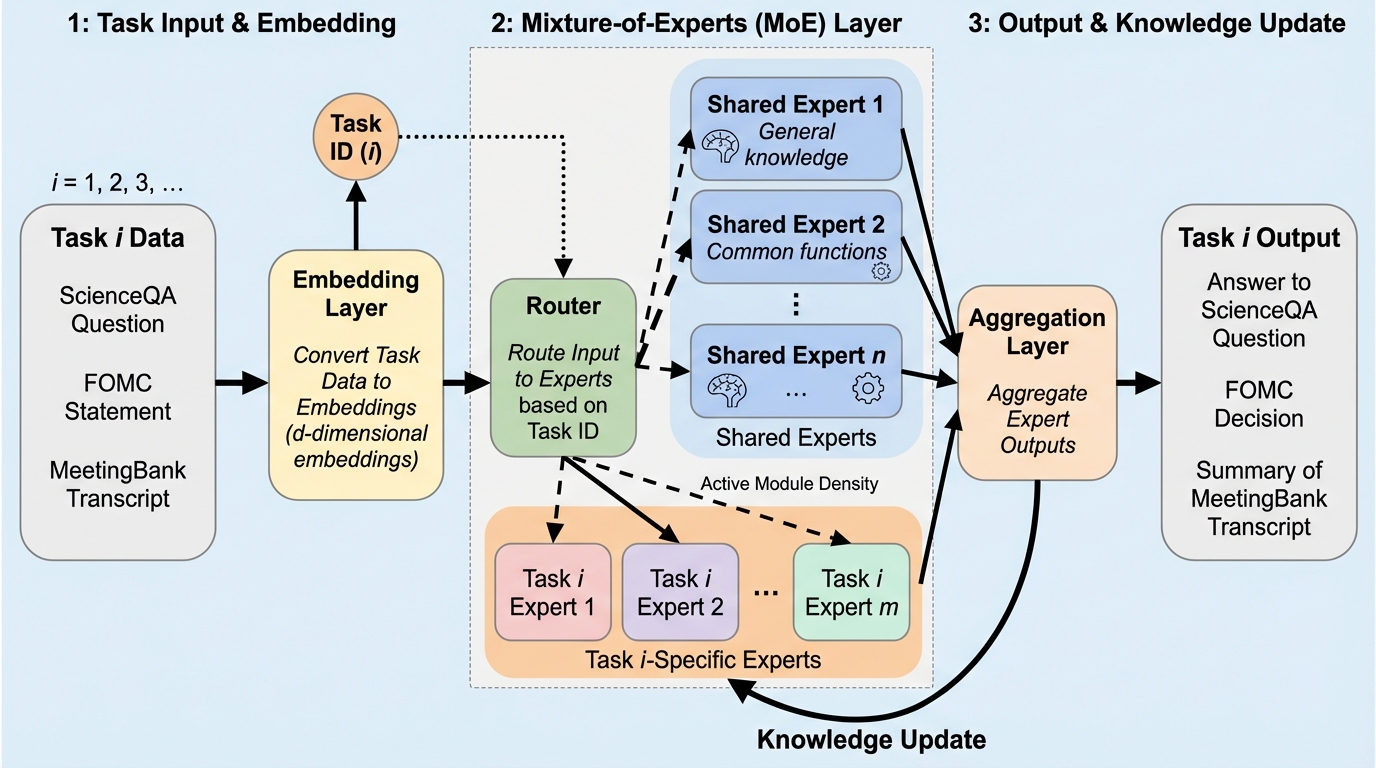
大規模言語モデル(LLM)の継続学習において、新しい知識の習得(可塑性)と過去の知識の保持(安定性)を両立させるため、モデルをモジュール化された部分空間に分解する新フレームワーク「SETA」が提案されました。 この手法は「Split-on-Share(SoS)」メカニズムにより、タスク間で重複するパラメータを「共有専門家」として安定化させ、重複しないパラメータを「固有専門家」として凍結することで、破滅的忘却を構造的に防ぐことに成功しています。 タスク識別子を必要としない適応的ゲーティングネットワークを導入しており、推論時には入力トークンに基づいて最適な専門家の組み合わせを自動的に選択することで、高度なタスク非依存の推論と長期的な学習の安定性を実現しました。
なぜこの問題か
大規模言語モデルを実用化する上で、新しいタスクを次々と学習させる継続学習は極めて重要ですが、そこには「可塑性と安定性のジレンマ」という根本的な課題が存在します。新しい知識を素早く取り込もうとすると、モデルのパラメータが大幅に更新され、以前に学習した知識が上書きされて失われる「破滅的忘却」が発生します。逆に、過去の知識を守るためにパラメータを固定しすぎると、新しいタスクに適応するための柔軟性、すなわち可塑性が失われてしまいます。このトレードオフは、モデルが大規模化し、学習すべきタスクが複雑になるほど深刻な問題となります。 既存の継続学習手法には、過去のデータを再生するリプレイ法、重要なパラメータの更新を制限する正則化法、タスクごとにモジュールを物理的に分離するパラメータ隔離法などがあります。しかし、これらの手法の多くは、パラメータをその部分空間内で一律に扱う傾向があります。そのため、タスク間で共有可能な一般的な特徴と、特定のタスクにのみ必要な固有の知識を区別できていません。この「共有部分空間のジレンマ」により、学習が進むにつれてパラメータの競合が発生し、効率的な知識の蓄積が妨げられます。…
核心:何を提案したのか
本論文では、これらの課題を解決するために「SETA(Mixture of Sparse Experts for Task-Agnostic Continual Learning)」という新しいフレームワークを提案しています。SETAの核心は、モデルの容量を「共有専門家(Shared Experts)」と「固有専門家(Unique Experts)」という二つの異なる機能セットに動的に分割する点にあります。これにより、タスク間の干渉を最小限に抑えつつ、知識の転移と保持を同時に達成します。このアプローチは、単にパラメータを節約するだけでなく、モデルの内部構造をタスクの性質に合わせて最適化するものです。 SETAの設計は、三つの主要な問い(Research Questions)に答える形で構成されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related