言語モデルが知っているのに言わないこと:汎化のための非生成的事前知識の抽出
医療や金融分野ではラベル付きデータの収集が困難であり、少数の偏ったデータで学習したモデルは未知のデータ分布に対して汎化性能が著しく低下するという深刻な課題がある。 本研究が提案するLoIDは、大規模言語モデルが内部に持つ知識をテキスト生成ではなくトークン単位のロジットとして直接抽出する決定論的な手法であり、ベイズ統計学の事前分布として統合する。 10種類の公開データセットを用いた検証の結果、LoIDは既存手法を上回る精度を記録し、理想的なモデルとの性能差を最大59%回復させるなど、高い信頼性と計算効率、そして再現性を示した。
TL;DR(結論)
医療や金融分野ではラベル付きデータの収集が困難であり、少数の偏ったデータで学習したモデルは未知のデータ分布に対して汎化性能が著しく低下するという深刻な課題がある。 本研究が提案するLoIDは、大規模言語モデルが内部に持つ知識をテキスト生成ではなくトークン単位のロジットとして直接抽出する決定論的な手法であり、ベイズ統計学の事前分布として統合する。 10種類の公開データセットを用いた検証の結果、LoIDは既存手法を上回る精度を記録し、理想的なモデルとの性能差を最大59%回復させるなど、高い信頼性と計算効率、そして再現性を示した。
なぜこの問題か
機械学習モデルが医療や金融といった極めて重要なドメインで活用される際、大規模でバランスの取れた、かつ包括的にラベル付けされたデータセットにアクセスできないことが大きな障壁となっている。例えば、臨床データセットは特定の単一の病院や特定の人口統計学的グループのみをカバーしていることが多く、またクレジットカードのリスク評価テーブルは過去の特定の貸付パターンに偏っている可能性がある。先行研究では、単一の病院の電子健康記録データセットを用いた臨床予測タスクにおいて、深層学習モデルが特定の環境に過剰適合する傾向が指摘されている。その結果、小規模で代表性の低いサンプルで訓練されたモデルは、訓練時の分布とは異なる現実世界の母集団に直面した際、汎化に失敗することが頻繁に発生する。このようなモデルの脆弱性を軽減するために、ベイズ統計学的な手法を用いて事前知識をエンコードする方法が原理的な解決策として知られているが、高品質な事前分布を大規模に手動で引き出すことは、専門家の工数やコストの面から長年の課題であった。…
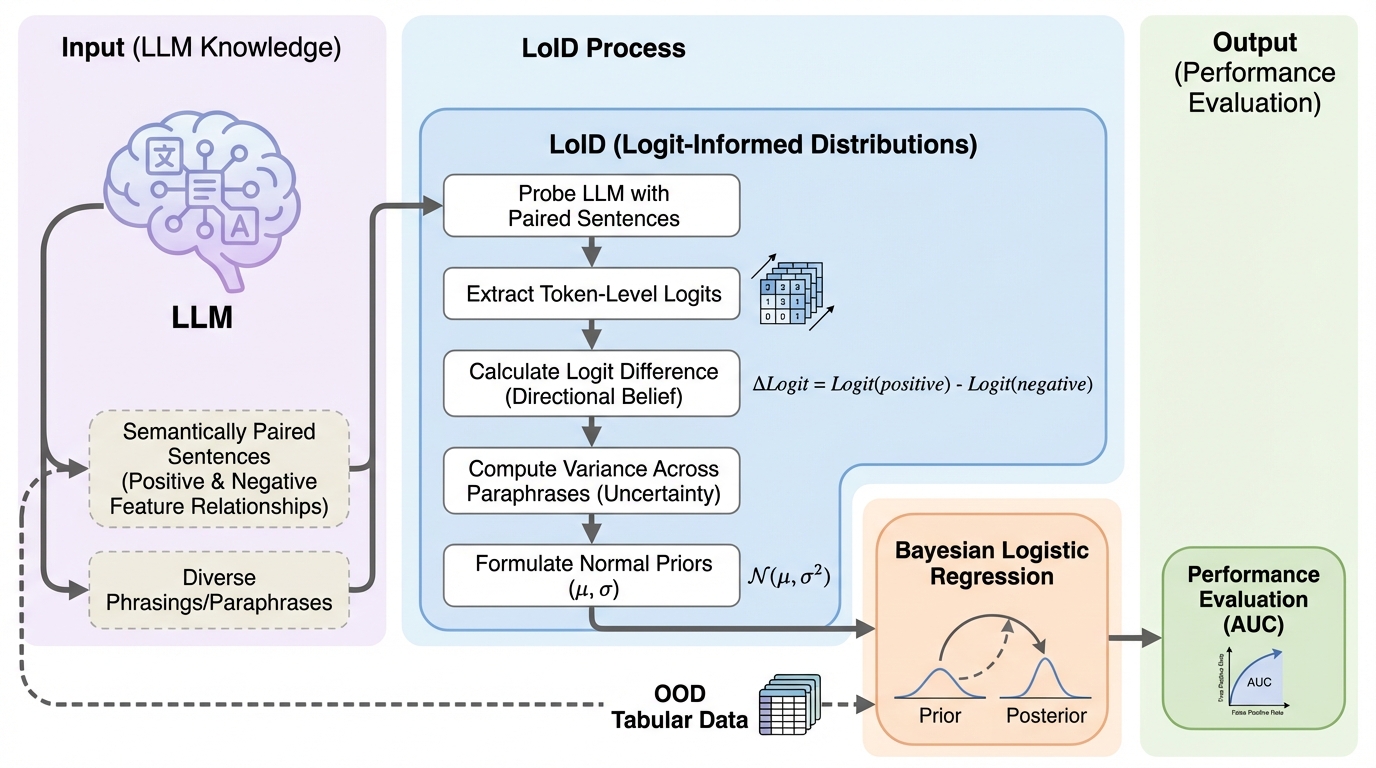
核心:何を提案したのか
本研究は、LoID(Logit-Informed Distributions)と呼ばれる決定論的なフレームワークを提案している。これは、LLMが生成するテキストのサンプルや補完機能に依存するのではなく、トークンレベルのロジット(未正規化の確率値)に直接アクセスすることで、表形式データの各特徴量に対する有益な事前分布を抽出する革新的な手法である。LoIDの核心的なアイデアは、LLMが「知っているが、あえて言葉として出力しない」潜在的な知識を、数値的な確信度として直接引き出す点にある。具体的には、ベイズロジスティック回帰のための事前分布を構築するために、LLMの内部的な予測確率を測定する。この手法は、特定のタスクに対する追加のファインチューニングや、複雑なインコンテキスト学習を一切必要としない点が大きな利点である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related