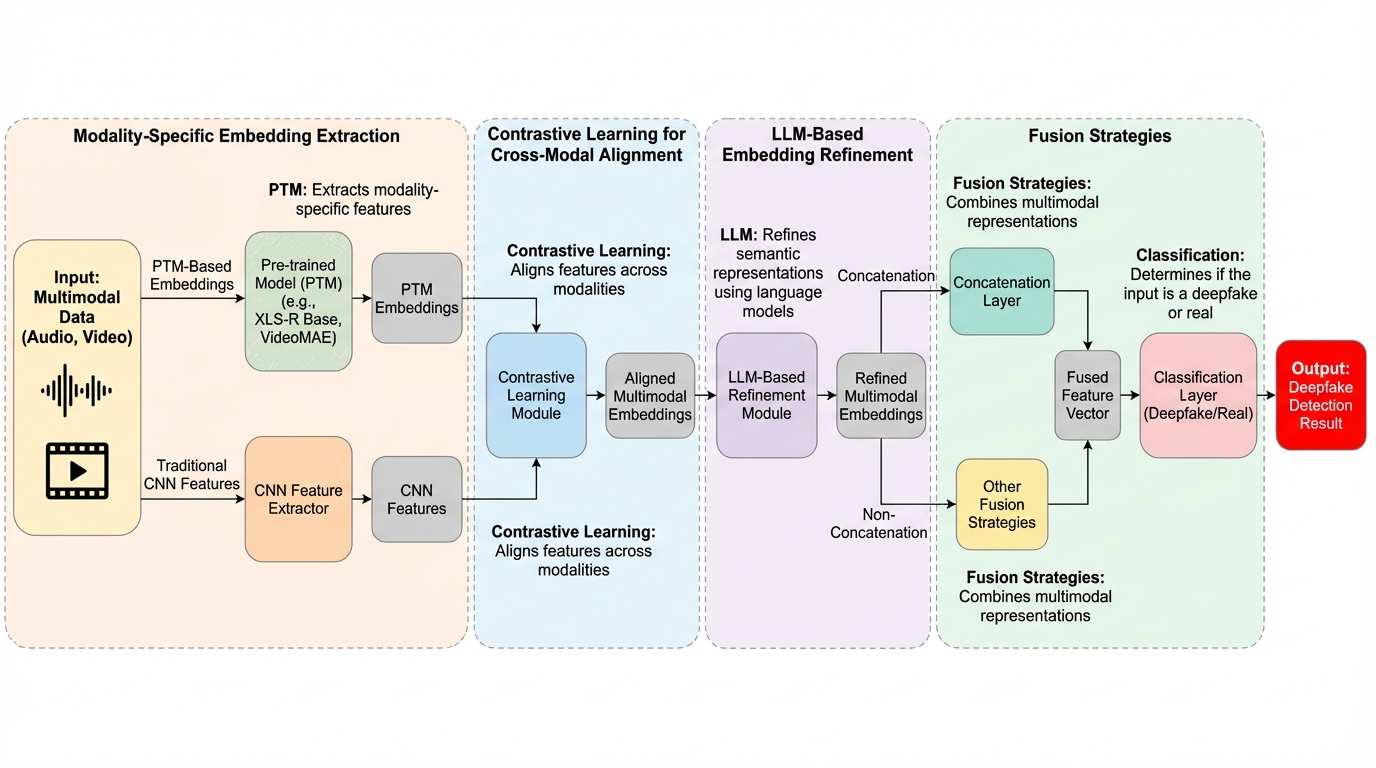
マルチモーダルディープフェイク検出のためのConLLMを用いた真実の解明
生成AIの進化により、音声と映像を組み合わせた高度なディープフェイクが社会的な脅威となっていますが、従来の検出手法は各要素を個別に処理するため、要素間の微細な矛盾を見逃す「モダリティの断片化」や「浅い相互推論」という課題を抱えていました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
生成AIの進化により、音声と映像を組み合わせた高度なディープフェイクが社会的な脅威となっていますが、従来の検出手法は各要素を個別に処理するため、要素間の微細な矛盾を見逃す「モダリティの断片化」や「浅い相互推論」という課題を抱えていました。
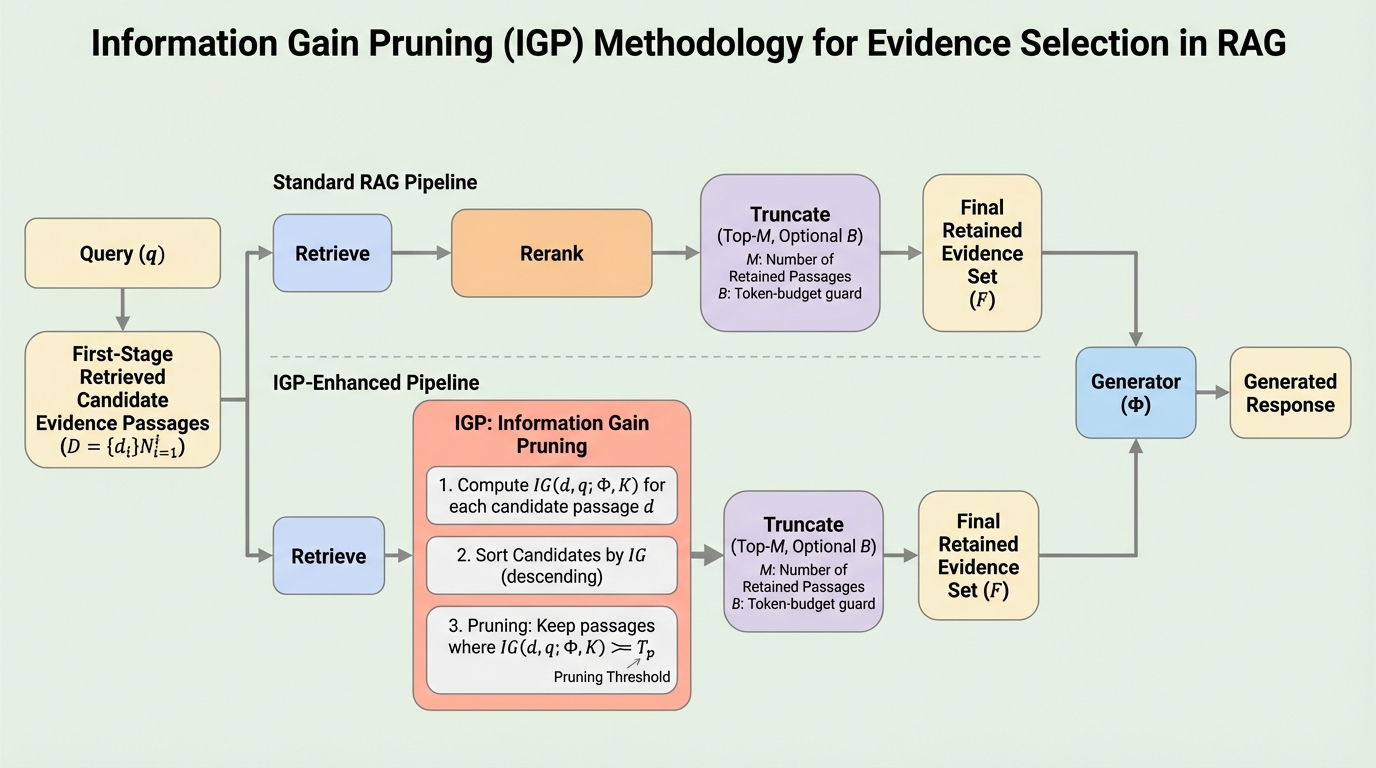
RAG(検索拡張生成)において、検索の関連性指標と最終的な回答精度が必ずしも一致せず、複数の証拠を注入すると冗長性や矛盾によって生成が不安定になるという「関連性と実用性のミスマッチ」を解消するため、生成モデルの不確実性の減少量を基準に証拠を選択する手法「Information Gain Pruning (IGP)」を提案しました。 / IGPは、追加の学習やラベルを必要とせず、生成モデルが出力するトークンの確率分布(ロジット)のみを用いて、回答の安定性に寄与する「情報利得」が高い証拠を特定し、生成を混乱させる低利得な情報をコンテキスト予算に到達する前に排除することで、限られたリソース内での最適な証拠選択を実現します。 / 5つのオープンドメイン質問回答ベンチマークを用いた検証において、IGPは従来手法と比較して回答精度(F1スコア)を約12〜20%向上させると同時に、生成モデルへの入力トークン数を約76〜79%削減するという、精度向上とコスト削減を同時に達成する極めて優れたパフォーマンスを実証しました。
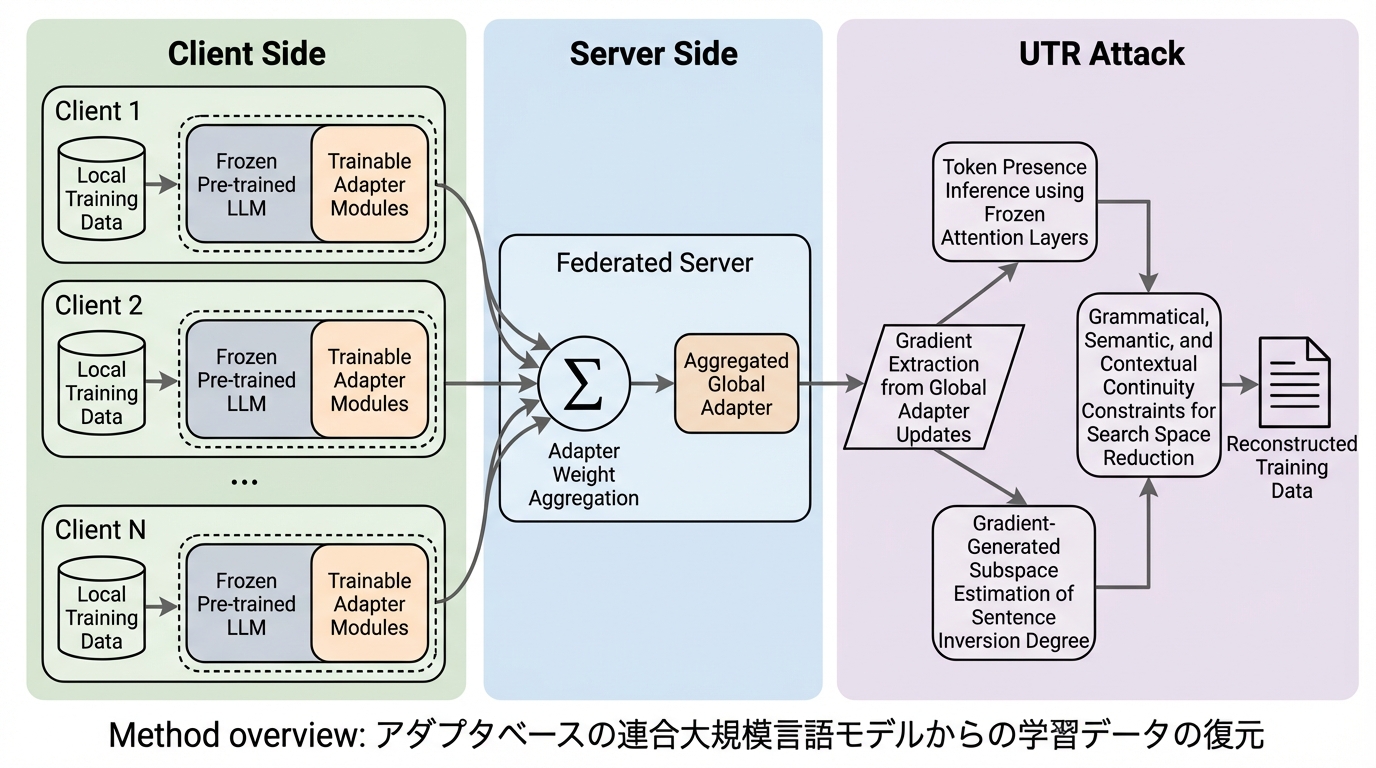
アダプタベースの連合大規模言語モデル(FedLLM)は、計算資源の節約とプライバシー保護を両立する手法として広く採用されていますが、本研究は「UTR」という新しい攻撃手法を用いることで、凍結されたモデル背後にある秘密の学習データを極めて高い精度で復元できることを明らかにしました。
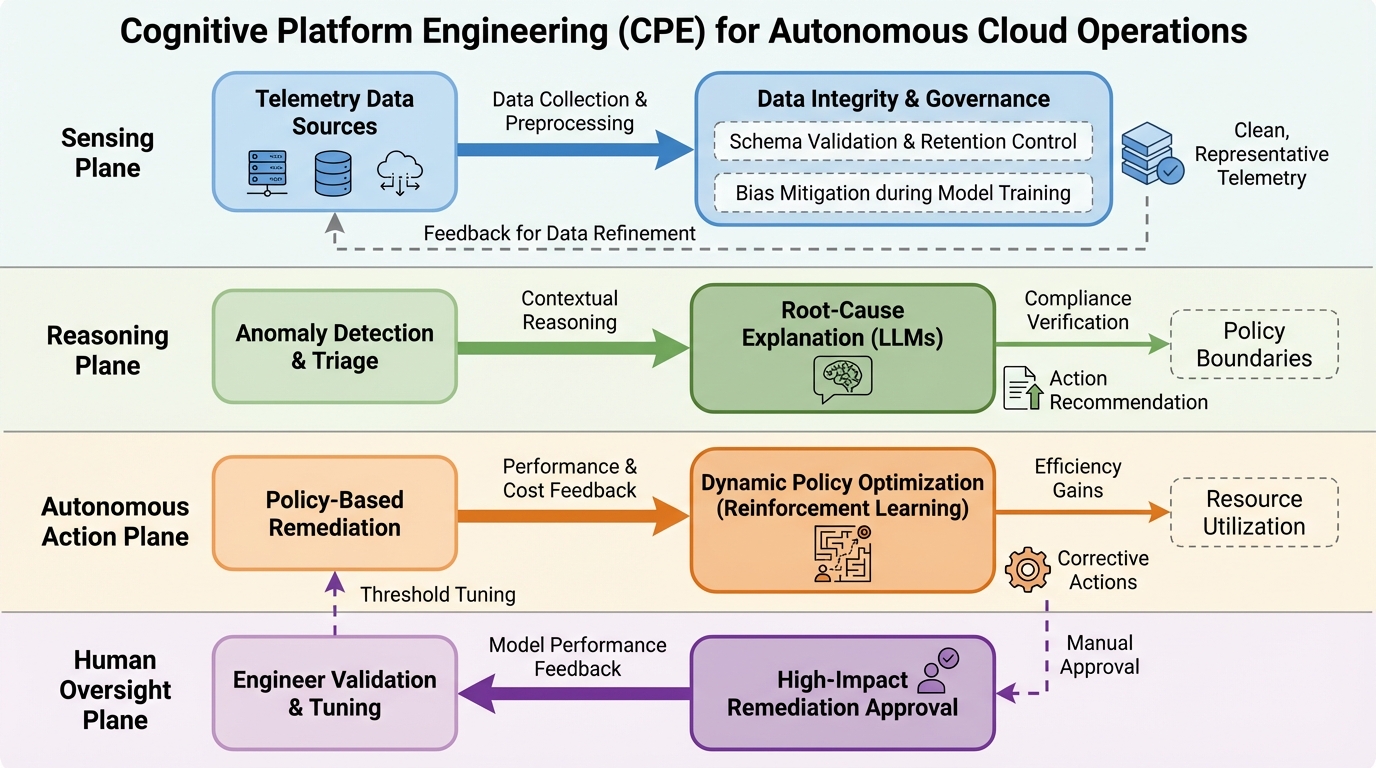
現代の複雑なクラウドネイティブ環境において、従来のDevOpsによる静的な自動化の限界を打破するため、感知・推論・行動を統合した「コグニティブ・プラットフォーム・エンジニアリング(CPE)」が提案されました。
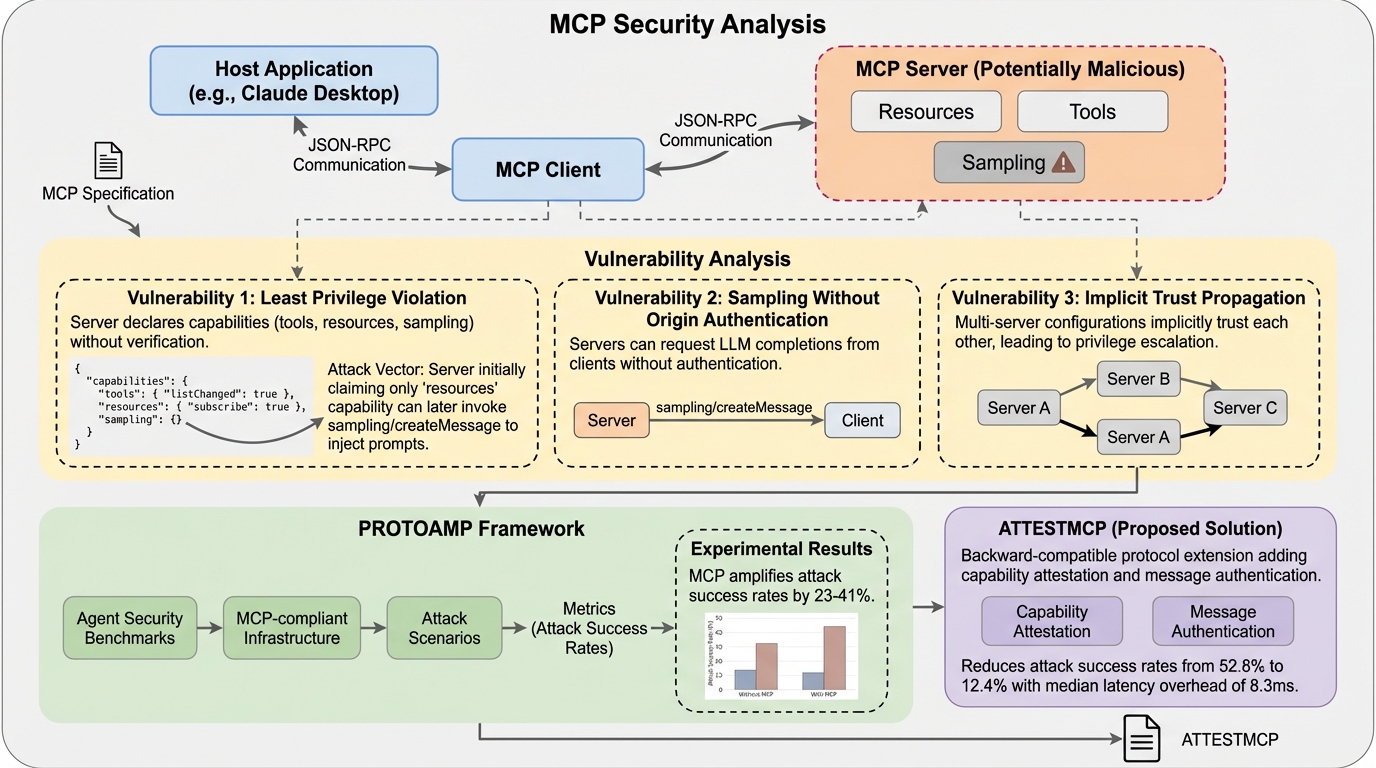
Anthropicが2024年11月に発表したModel Context Protocol(MCP)は、AIエージェントと外部ツールを統合する標準規格として急速に普及していますが、権限証明の欠如、送信元認証のないサンプリング機能、および複数サーバー間での暗黙的な信頼伝播という3つの根本的な設計上の脆弱性が存在することが本研究の分析によって明らかになりました。 研究チームは、既存のセキュリティベンチマークをMCP環境に適応させた評価フレームワーク「PROTOAMP」を開発し、847件の攻撃シナリオを用いて実験を行った結果、MCPのアーキテクチャ自体が攻撃の成功率を非MCP環境と比較して23%から41%も増幅させていることを定量的に示し、その危険性を証明しました。 これらの深刻な脆弱性への対策として、後方互換性を持つプロトコル拡張案「ATTESTMCP」が提案され、暗号化による権限証明やメッセージ認証、送信元のタグ付けを導入することで、攻撃成功率を52.8%から12.4%へと大幅に低減しつつ、追加される遅延を実用的な範囲内に抑えられることが実証されました。
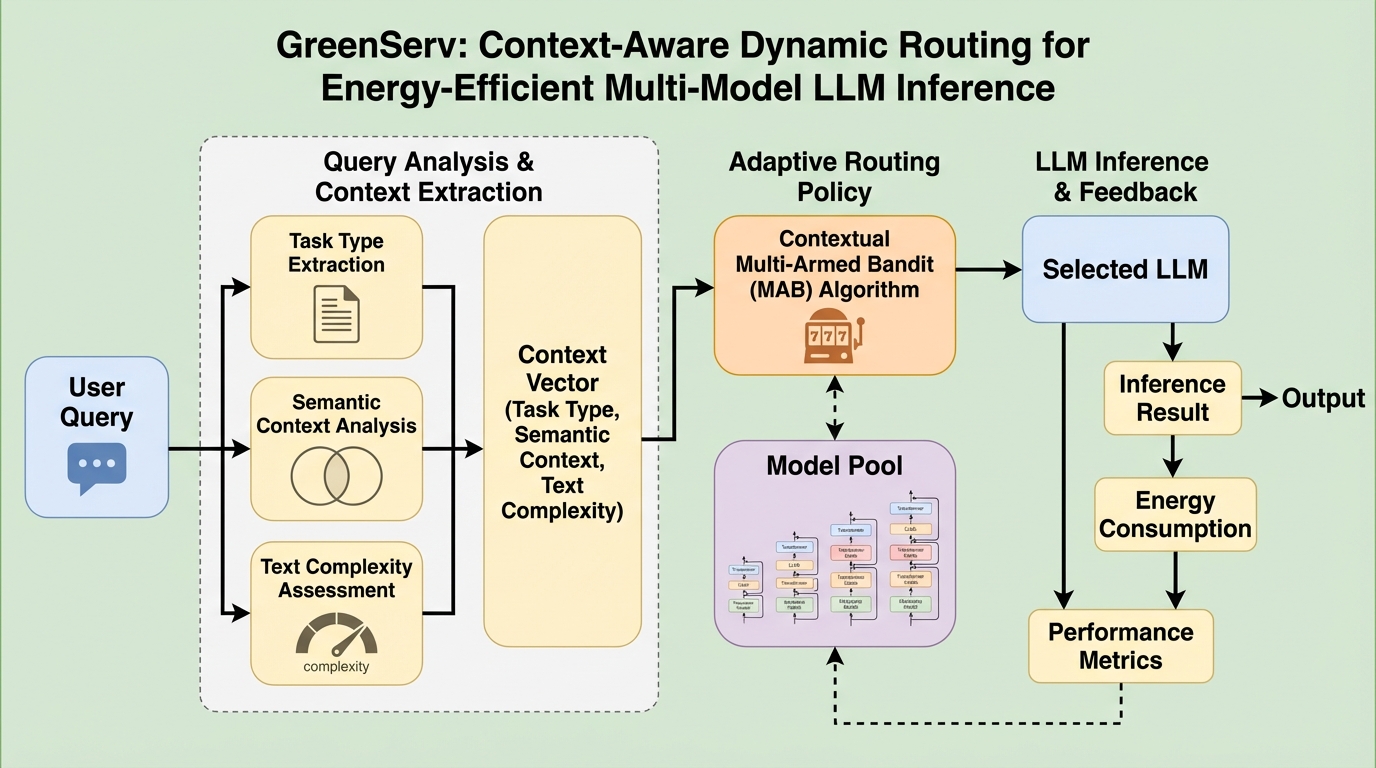
GreenServは、大規模言語モデル(LLM)の推論における膨大なエネルギー消費を削減するために開発された、動的でコンテキストを認識するルーティングフレームワークである。各クエリからタスクの種類や意味的クラスタ、テキストの複雑性などの軽量な特徴を抽出し、文脈付き多腕バンディット(MAB)アルゴリズムを用いて、精度とエネルギー効率のバランスが最も優れたモデルを複数の候補から自動的に選択する。 このシステムは、従来の静的なモデル選択とは異なり、実際の運用を通じてモデルの性能を学習し続けるオンライン学習機能を備えている。これにより、事前の膨大なキャリブレーションを必要とせず、新しいモデルが追加された際にも即座に最適なルーティング戦略に組み込むことが可能となっている。 実験の結果、ランダムなルーティングと比較して精度を22%向上させつつ、累積エネルギー消費を31%削減することに成功した。また、推論時のオーバーヘッドは極めて小さく、実用的な遅延制約を満たしながら、持続可能なAI運用のための高度なトレードオフ制御を実現している。
本研究は、行動ラベルのない観察データのみから学習を行う新しい模倣学習手法「UfO(Unsupervised Imitation Learning from Observation)」を提案し、従来の手法が抱えていた「行動ベースの教師あり学習への依存」や「特定の状態には単一の最適行動しかないという誤った仮定」を排除することに成功した。 UfOは、方策モデルと生成モデルを相互に最適化する「再構成ステージ」と、状態の差分を利用して行動を微調整する「敵対的ステージ」の二段階構成を採用しており、これにより教師データの行動を盲目的に模倣するのではなく、環境の因果構造を理解した上での柔軟な学習を可能にしている。 5つの標準的なシミュレーション環境を用いた検証において、UfOは教師モデルの性能を上回るスコアを記録しただけでなく、標準偏差を最小限に抑えることで未知のシナリオに対する極めて高い汎化性能を実証し、観察のみによる無人模倣学習の新たな基準を確立した。
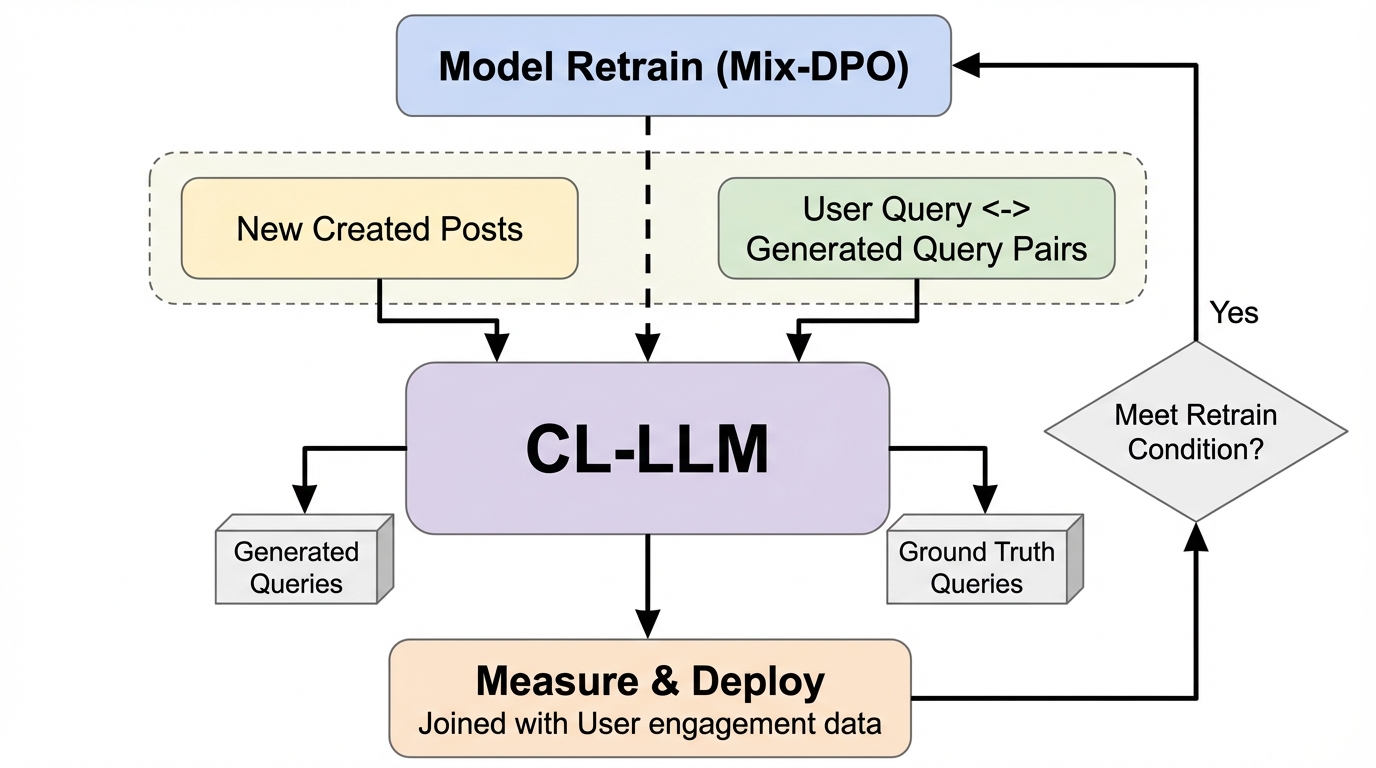
検索トラフィックが少ない環境では、従来のクエリ量に基づくトレンド検出が困難であるため、投稿内容から直接検索クエリを生成して合成シグナルを作るRTTPフレームワークが提案されました。 このシステムは、継続学習型の大規模言語モデル(CL-LLM)と、新旧のデータを適切に混合して学習させるMix-Policy DPOという新しい最適化手法を採用しており、モデルの知的な推論能力を維持しながら最新の話題に適応し続けることが可能です。 FacebookやMeta AIの製品規模で導入された結果、トレンド検出の精度が相対的に91.4%向上し、クエリ生成の正確性も従来手法より19%改善しており、ユーザーが検索を開始する前の極めて早い段階でトレンドを予測できることが実証されました。
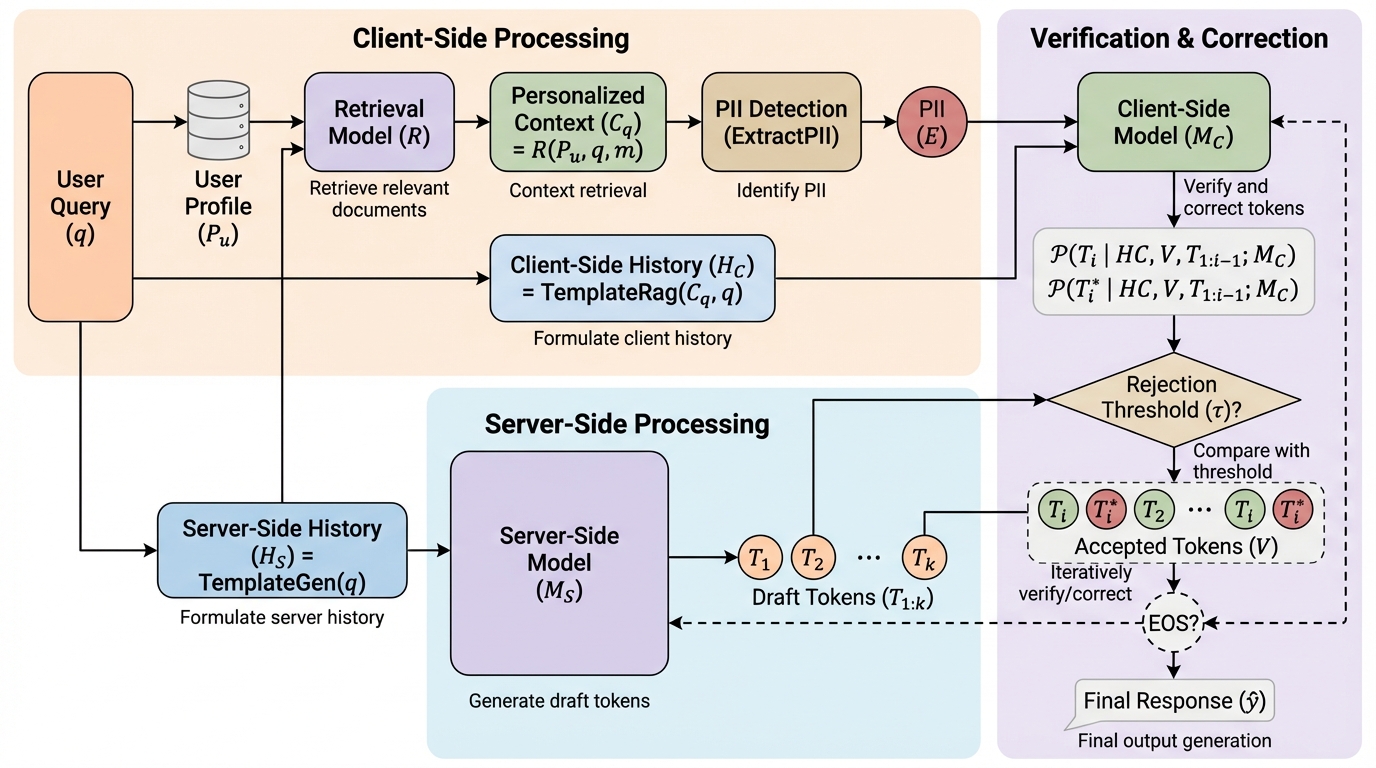
大規模言語モデル(LLM)のパーソナライズにおいて、ユーザーの機密情報をクラウドサーバーに一切開示することなく、高品質な回答を生成するための新しい対話型フレームワーク「P3」が提案されました。 この手法は、サーバー側の強力なモデルが回答候補を生成し、ユーザー手元の小規模モデルが個人のプロフィールに基づき内容を検証・修正する「推測、検証、修正」のプロセスを繰り返すことで、プライバシーと性能を両立させます。 実験では、個人情報を完全に公開した場合の9割以上の性能を維持しつつ、情報漏洩を最小限に抑え、従来のローカルモデル単体や非パーソナライズモデルを平均で7.4%から9%上回る精度を達成することに成功しました。
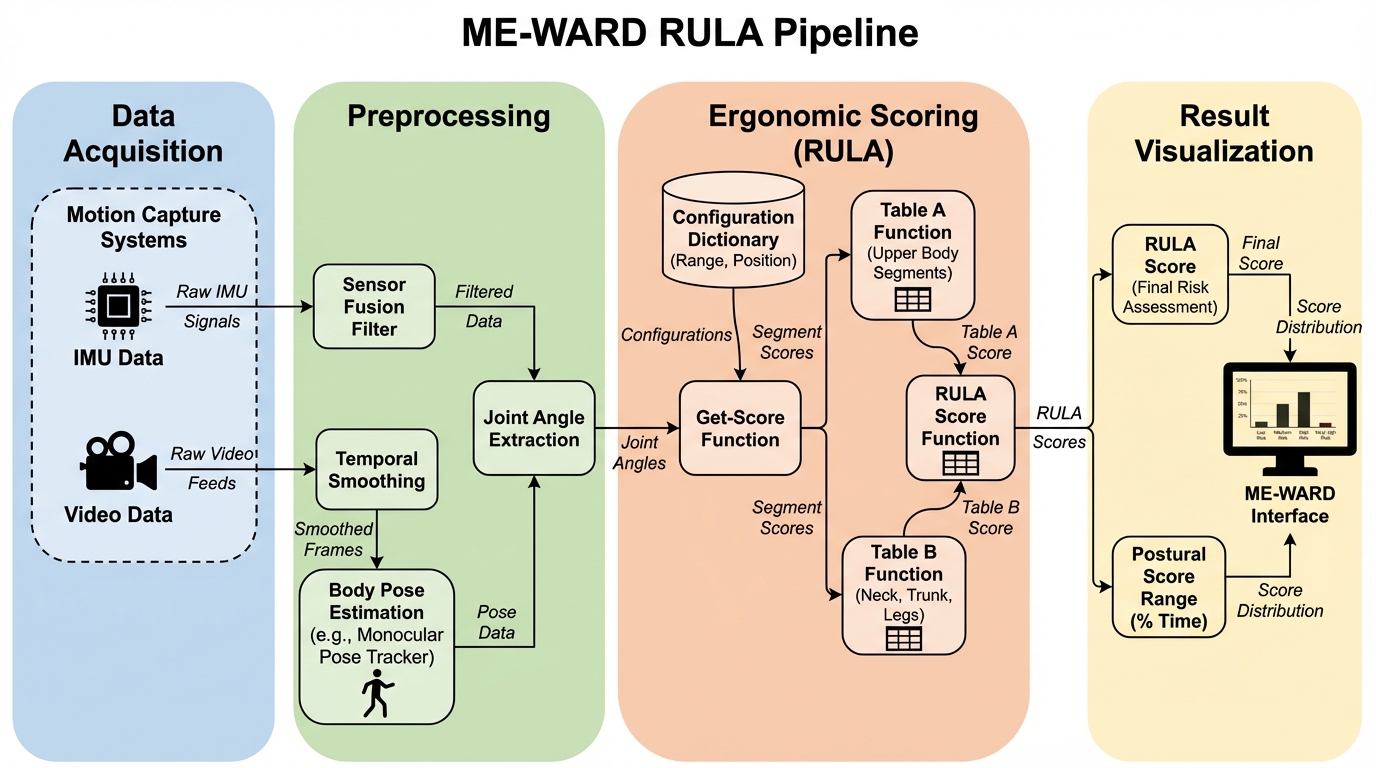
ME-WARDは、慣性計測装置(IMU)とビデオベースのポーズ推定技術を統合し、上肢の姿勢評価手法であるRULAをデジタル化することで、職場における筋骨格系疾患のリスクを自動かつ客観的に評価するマルチモーダルな分析システムである。