条件付き遷移推定とオンライン行動アライメントによる汎化可能な模倣学習に向けて
本研究は、行動ラベルのない観察データのみから学習を行う新しい模倣学習手法「UfO(Unsupervised Imitation Learning from Observation)」を提案し、従来の手法が抱えていた「行動ベースの教師あり学習への依存」や「特定の状態には単一の最適行動しかないという誤った仮定」を排除することに成功した。 UfOは、方策モデルと生成モデルを相互に最適化する「再構成ステージ」と、状態の差分を利用して行動を微調整する「敵対的ステージ」の二段階構成を採用しており、これにより教師データの行動を盲目的に模倣するのではなく、環境の因果構造を理解した上での柔軟な学習を可能にしている。 5つの標準的なシミュレーション環境を用いた検証において、UfOは教師モデルの性能を上回るスコアを記録しただけでなく、標準偏差を最小限に抑えることで未知のシナリオに対する極めて高い汎化性能を実証し、観察のみによる無人模倣学習の新たな基準を確立した。
TL;DR(結論)
本研究は、行動ラベルのない観察データのみから学習を行う新しい模倣学習手法「UfO(Unsupervised Imitation Learning from Observation)」を提案し、従来の手法が抱えていた「行動ベースの教師あり学習への依存」や「特定の状態には単一の最適行動しかないという誤った仮定」を排除することに成功した。 UfOは、方策モデルと生成モデルを相互に最適化する「再構成ステージ」と、状態の差分を利用して行動を微調整する「敵対的ステージ」の二段階構成を採用しており、これにより教師データの行動を盲目的に模倣するのではなく、環境の因果構造を理解した上での柔軟な学習を可能にしている。 5つの標準的なシミュレーション環境を用いた検証において、UfOは教師モデルの性能を上回るスコアを記録しただけでなく、標準偏差を最小限に抑えることで未知のシナリオに対する極めて高い汎化性能を実証し、観察のみによる無人模倣学習の新たな基準を確立した。
なぜこの問題か
コンピュータサイエンスの分野において、他者の行動を観察してタスクの遂行方法を学ぶ「模倣学習(IL)」は非常に重要な技術であるが、従来の主流であった「実演からの模倣学習(ILfD)」には大きな課題が存在していた。ILfDは教師が実行した「状態」と「行動」のペアをデータセットとして利用するが、現実の世界ではゲームのプレイ動画のように「状態(映像)」は得られても、実際にどのような「行動(入力)」が行われたかというラベルを取得することは極めて困難であり、データの希少性が問題となっていた。この問題を解決するために、行動ラベルを必要とせず状態の遷移のみから学習する「観察からの模倣学習(ILfO)」が登場したが、既存のILfO手法にも依然として深刻な制限が残されていた。既存手法の多くは、特定の状態から到達できる次の状態は一つしかないという「単射的な遷移関数」の仮定に依存しており、複数の解法が存在する複雑な環境では、特定の行動に偏った柔軟性のない学習結果を招く傾向があった。…
核心:何を提案したのか
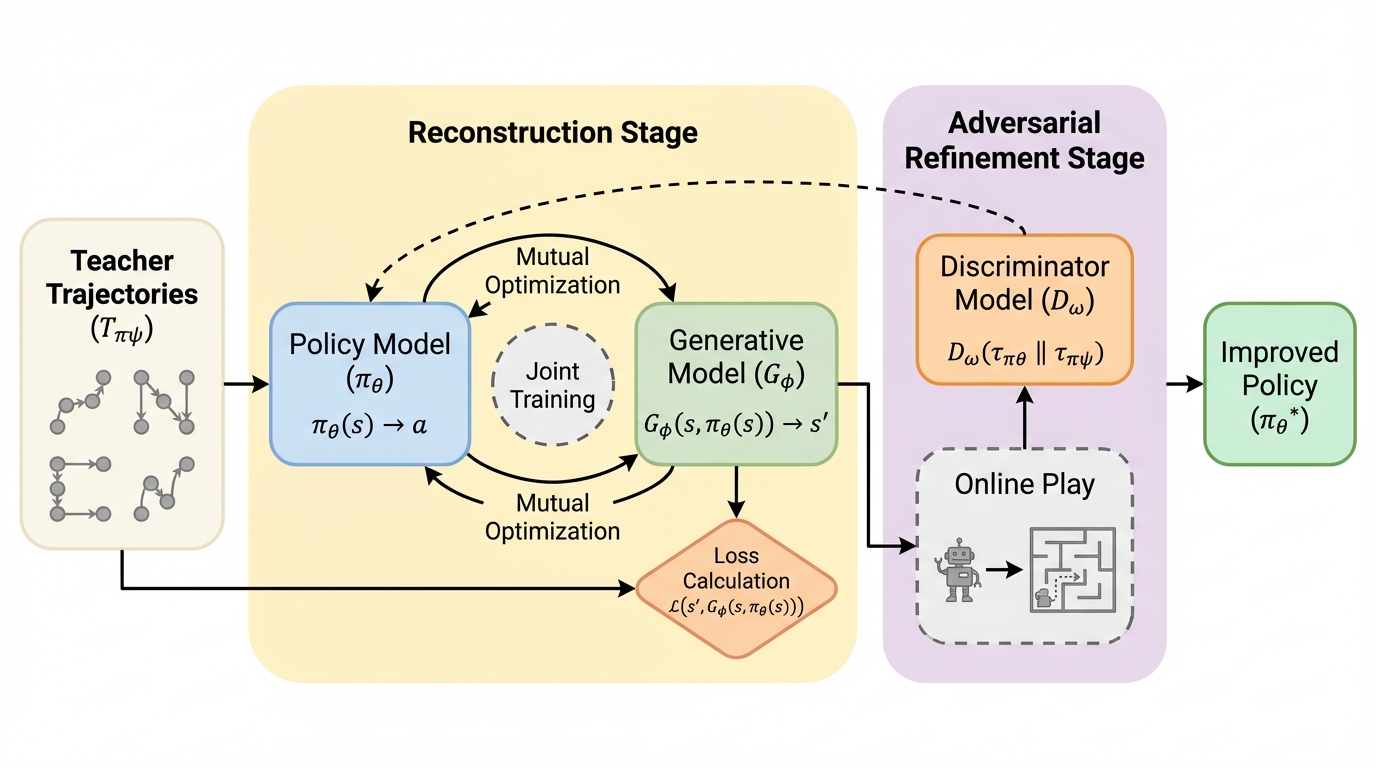
本論文では、行動ベースの教師あり最適化を一切必要としない、革新的な無人模倣学習手法「UfO(Unsupervised Imitation Learning from Observation)」を提案している。UfOの最大の特徴は、行動ラベルを介在させずに、状態遷移の因果構造から直接行動の本質を理解しようとする「二段階の学習プロセス」を導入した点にある。第一段階である「再構成ステージ」では、エージェントの方策モデルと、環境のダイナミクスを模倣する条件付き生成モデルを同時に訓練し、両者を相互に最適化させることで、教師の行動を間接的に推定する仕組みを構築した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related