継続的に調整されるLLMクエリ生成によるリアルタイムトレンド予測
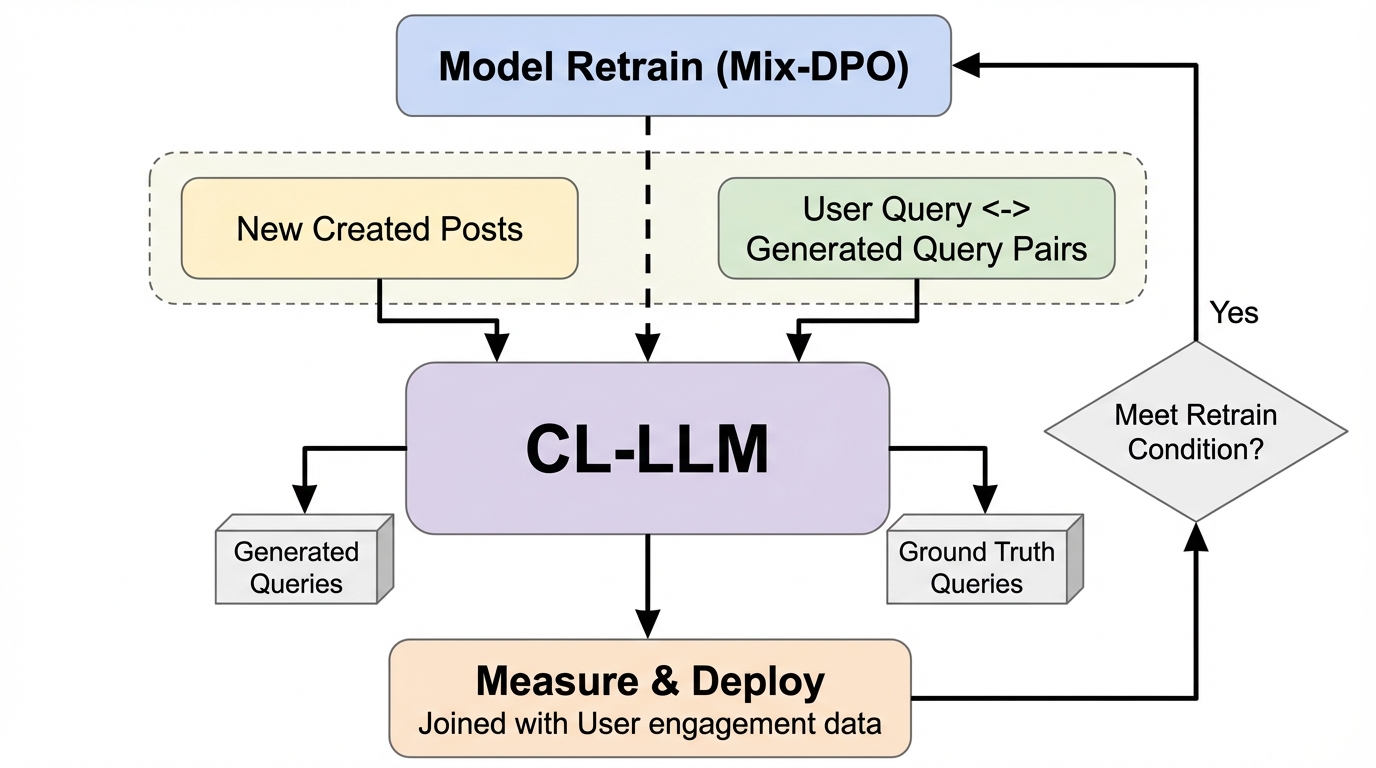
検索トラフィックが少ない環境では、従来のクエリ量に基づくトレンド検出が困難であるため、投稿内容から直接検索クエリを生成して合成シグナルを作るRTTPフレームワークが提案されました。 このシステムは、継続学習型の大規模言語モデル(CL-LLM)と、新旧のデータを適切に混合して学習させるMix-Policy DPOという新しい最適化手法を採用しており、モデルの知的な推論能力を維持しながら最新の話題に適応し続けることが可能です。 FacebookやMeta AIの製品規模で導入された結果、トレンド検出の精度が相対的に91.4%向上し、クエリ生成の正確性も従来手法より19%改善しており、ユーザーが検索を開始する前の極めて早い段階でトレンドを予測できることが実証されました。
TL;DR(結論)
検索トラフィックが少ない環境では、従来のクエリ量に基づくトレンド検出が困難であるため、投稿内容から直接検索クエリを生成して合成シグナルを作るRTTPフレームワークが提案されました。 このシステムは、継続学習型の大規模言語モデル(CL-LLM)と、新旧のデータを適切に混合して学習させるMix-Policy DPOという新しい最適化手法を採用しており、モデルの知的な推論能力を維持しながら最新の話題に適応し続けることが可能です。 FacebookやMeta AIの製品規模で導入された結果、トレンド検出の精度が相対的に91.4%向上し、クエリ生成の正確性も従来手法より19%改善しており、ユーザーが検索を開始する前の極めて早い段階でトレンドを予測できることが実証されました。
なぜこの問題か
ソーシャルメディアにおけるトレンド検出は、検索結果の新鮮さを保ち、ユーザーに最新の情報を提供するために極めて重要な役割を担っています。しかし、既存のトレンド検出手法には「コールドスタート問題」という根本的な課題が存在します。Google Trendsのようなシステムは膨大なクエリログに基づく統計的なヒューリスティックに依存しており、X(旧Twitter)などのプラットフォームではキーワードやハッシュタグの急激な増加を検知するためにポアソンモデルなどが用いられています。これらの手法は、すでに大量の検索トラフィックが発生していることを前提として設計されています。そのため、検索トラフィックが少ない環境や、発生したばかりの新しい話題、あるいは特定のコミュニティでのみ注目されるロングテールのトレンドにおいては、十分なクエリボリュームが集まるまでに時間がかかり、検出が大幅に遅れてしまいます。 この遅延は、現実世界での人々の関心の移り変わりに対してシステムが追従できないことを意味し、情報の鮮度が命であるソーシャルメディアにおいて致命的な欠陥となります。…
核心:何を提案したのか
本論文では、ユーザーが実際にクエリを発行するのを待つのではなく、新しく作成された投稿内容から直接検索クエリを生成する「RTTP(Real-Time Trending Prediction)」という新しいフレームワークを提案しています。このアプローチの核心は、検索ボリュームが形成される前の段階で、投稿内容から「ユーザーがどのような言葉で検索するか」を予測し、人工的な検索シグナル(合成シグナル)を作り出すことにあります。これにより、トラフィックが少ない環境でも、話題が拡散する兆候を早期に捉えることが可能になります。RTTPの心臓部には、継続学習型LLM(CL-LLM)が組み込まれており、最新の投稿を検索スタイルのクエリに変換する役割を担います。 生成されたクエリは、単に投稿からキーワードを抽出するのではなく、ユーザーの検索行動に合わせた形式に変換されます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related