Less is More for RAG: ジェネレーターに適合した情報利得プルーニングによるリランキングと証拠選択
RAG(検索拡張生成)において、検索の関連性指標と最終的な回答精度が必ずしも一致せず、複数の証拠を注入すると冗長性や矛盾によって生成が不安定になるという「関連性と実用性のミスマッチ」を解消するため、生成モデルの不確実性の減少量を基準に証拠を選択する手法「Information Gain Pruning (IGP)」を提案しました。 / IGPは、追加の学習やラベルを必要とせず、生成モデルが出力するトークンの確率分布(ロジット)のみを用いて、回答の安定性に寄与する「情報利得」が高い証拠を特定し、生成を混乱させる低利得な情報をコンテキスト予算に到達する前に排除することで、限られたリソース内での最適な証拠選択を実現します。 / 5つのオープンドメイン質問回答ベンチマークを用いた検証において、IGPは従来手法と比較して回答精度(F1スコア)を約12〜20%向上させると同時に、生成モデルへの入力トークン数を約76〜79%削減するという、精度向上とコスト削減を同時に達成する極めて優れたパフォーマンスを実証しました。
TL;DR(結論)
- RAG(検索拡張生成)において、検索の関連性指標と最終的な回答精度が必ずしも一致せず、複数の証拠を注入すると冗長性や矛盾によって生成が不安定になるという「関連性と実用性のミスマッチ」を解消するため、生成モデルの不確実性の減少量を基準に証拠を選択する手法「Information Gain Pruning (IGP)」を提案しました。
- IGPは、追加の学習やラベルを必要とせず、生成モデルが出力するトークンの確率分布(ロジット)のみを用いて、回答の安定性に寄与する「情報利得」が高い証拠を特定し、生成を混乱させる低利得な情報をコンテキスト予算に到達する前に排除することで、限られたリソース内での最適な証拠選択を実現します。
- 5つのオープンドメイン質問回答ベンチマークを用いた検証において、IGPは従来手法と比較して回答精度(F1スコア)を約12〜20%向上させると同時に、生成モデルへの入力トークン数を約76〜79%削減するという、精度向上とコスト削減を同時に達成する極めて優れたパフォーマンスを実証しました。
なぜこの問題か
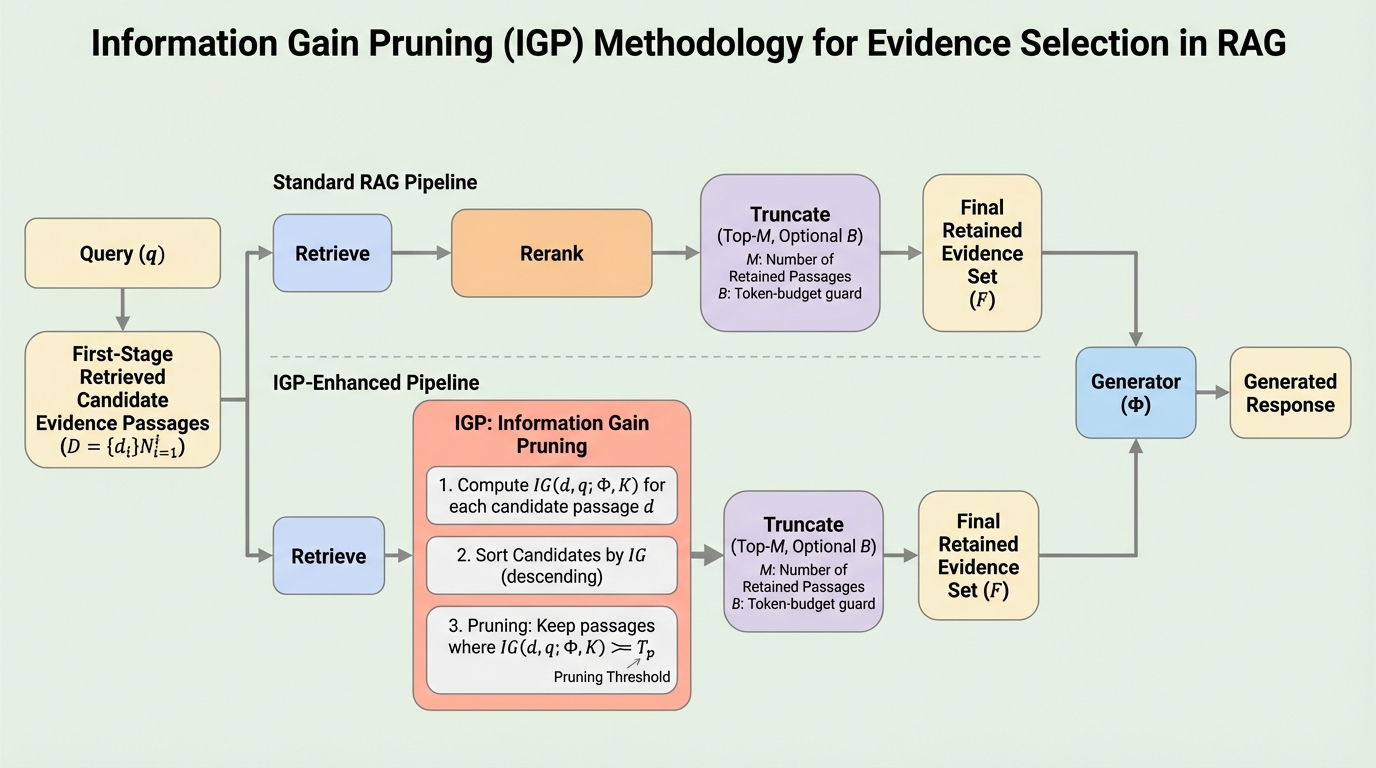
大規模言語モデル(LLM)を用いた検索拡張生成(RAG)は、外部の知識ベースから関連する文書を検索し、それを入力に加えることで回答の正確性を高める手法として広く普及しています。しかし、実用的なシステムにおいては、モデルが一度に処理できるコンテキストの長さには物理的な制限やコスト的な制約があり、限られた「予算」の中でどの情報を優先的に提供すべきかという証拠選択が極めて重要な課題となっています。従来のRAGシステムでは、まず大量の文書から関連性の高いものを検索し、次にそれらをリランキングして、上位のものを予算に合わせて切り捨てるという手順が一般的です。しかし、本研究が指摘する最も深刻な問題は、検索段階で重視される「関連性」の指標(例えばNDCGなど)が、最終的な回答の質(F1スコアなど)と必ずしも相関しないという事実です。特に、複数の証拠文書をモデルに注入するマルチエビデンスの設定においては、検索の関連性指標と回答精度の間の相関が極めて弱くなるだけでなく、場合によっては負の相関を示すことさえあることが判明しました。…
核心:何を提案したのか
本研究では、生成モデルの視点から証拠の有用性を直接評価し、不要な情報を効果的に排除する「Information Gain Pruning (IGP)」というモジュールを提案しました。IGPは、従来のリランキング段階を置き換えるプラグアンドプレイ型のコンポーネントであり、生成モデルが特定の証拠を得た際に、どれだけ回答に対する不確実性を減少させたかを「情報利得(Information Gain)」として数値化し、それに基づいて証拠の採否を決定します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related