アダプタベースの連合大規模言語モデルからの学習データの復元
アダプタベースの連合大規模言語モデル(FedLLM)は、計算資源の節約とプライバシー保護を両立する手法として広く採用されていますが、本研究は「UTR」という新しい攻撃手法を用いることで、凍結されたモデル背後にある秘密の学習データを極めて高い精度で復元できることを明らかにしました。
TL;DR(結論)
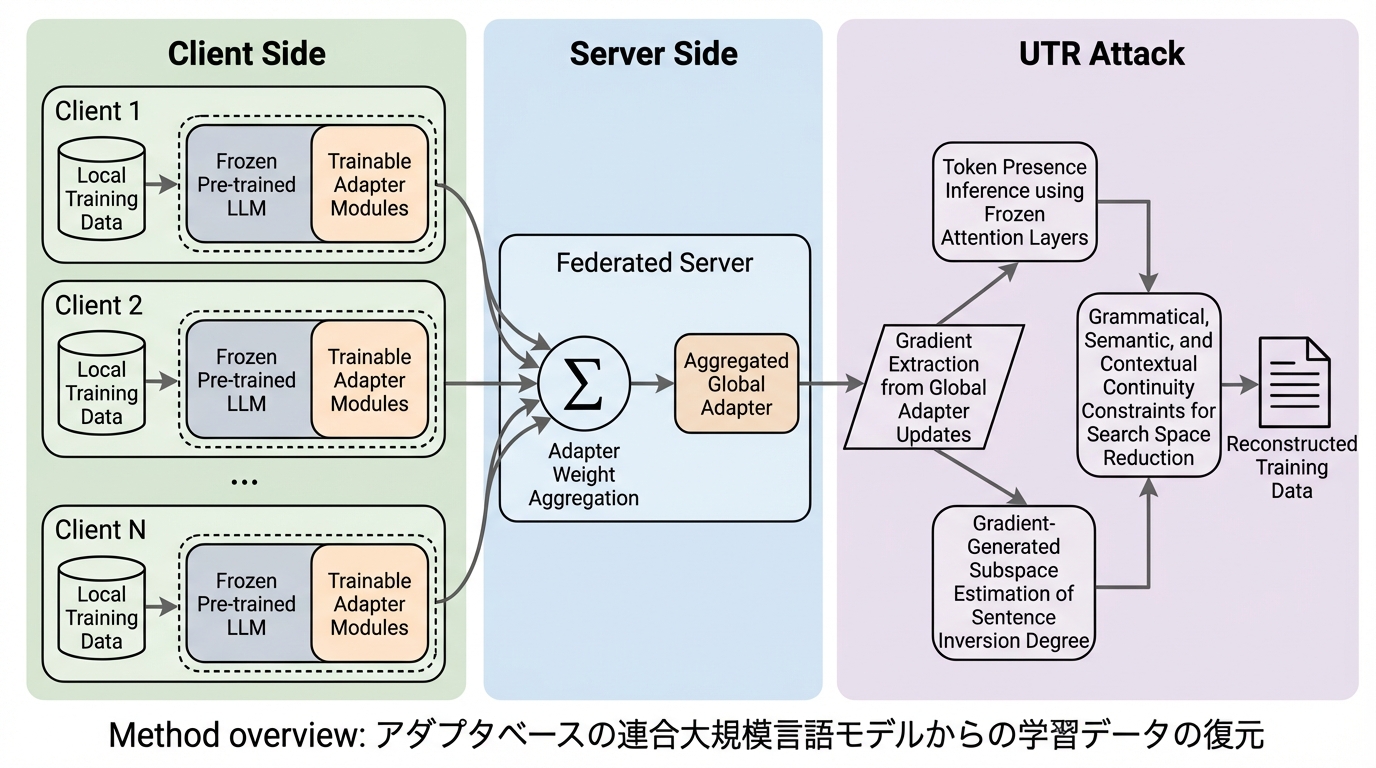
アダプタベースの連合大規模言語モデル(FedLLM)は、計算資源の節約とプライバシー保護を両立する手法として広く採用されていますが、本研究は「UTR」という新しい攻撃手法を用いることで、凍結されたモデル背後にある秘密の学習データを極めて高い精度で復元できることを明らかにしました。 UTR攻撃は、埋め込み層のアダプタ勾配から出現トークンを特定する「ワードバッグ推論」と、レイヤーアダプタの勾配を利用して文法・意味的整合性を保ちながら文章を組み立てる「データ推論」の2段階で構成されており、従来の手法では困難だった大規模なバッチサイズでの復元を可能にしています。 実験では、GPT-2やQwen2.5-7Bといった主要なモデルにおいて、バッチサイズ128という過酷な条件下でもROUGE-1/2スコアが99を超えるほぼ完璧な復元に成功しており、軽量なアダプタ学習が必ずしもデータの安全性を保証しないという、効率性とプライバシーの間の根本的な矛盾を提示しました。
なぜこの問題か
現代のウェブアプリケーションにおいて、パーソナライズされたエージェントやインテリジェントなチャットボット、共同コンテンツ生成プラットフォームなどの需要が高まっており、複数のユーザーやデバイス間でデータとモデルを連携させることが不可欠となっています。しかし、こうした連携にはメッセージ履歴や閲覧履歴、取引記録といった機密性の高い個人情報が含まれることが多く、GDPRやCCPAといった厳格なデータ保護規則の下では、直接的なデータ共有は大きなリスクを伴います。この課題を解決するために、データをローカルに保持したままモデルを更新する連合学習(FL)と大規模言語モデル(LLM)を組み合わせた「連合大規模言語モデル(FedLLM)」という枠組みが登場しました。 LLMは数百万から数十億のパラメータを持つため、すべてのパラメータを更新するフルパラメータ・ファインチューニングは、通信コストや計算資源の観点から現実的ではありません。そこで、モデルの大部分(バックボーン)を凍結し、LoRAのような軽量なアダプタモジュールのみを学習させる手法が主流となりました。…
核心:何を提案したのか
本研究は、アダプタベースのFedLLMに特化した新しい勾配反転攻撃手法である「UTR(Unordered-word-bag-based Text Reconstruction)」を提案しました。UTRの主な目的は、クライアントのプライベートな学習テキストを正確に復元すること、および一般的な防御メカニズムを回避することの2点にあります。この手法は、モデルのバックボーンが凍結されているという特性を逆手に取り、アダプタモジュールの構造的な脆弱性を突くことで、従来手法が失敗するような条件下でも高い復元性能を発揮します。 UTRは大きく分けて2つのステージで構成されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related