GreenServ:マルチモデルLLM推論のためのエネルギー効率に優れたコンテキスト認識型動的ルーティング
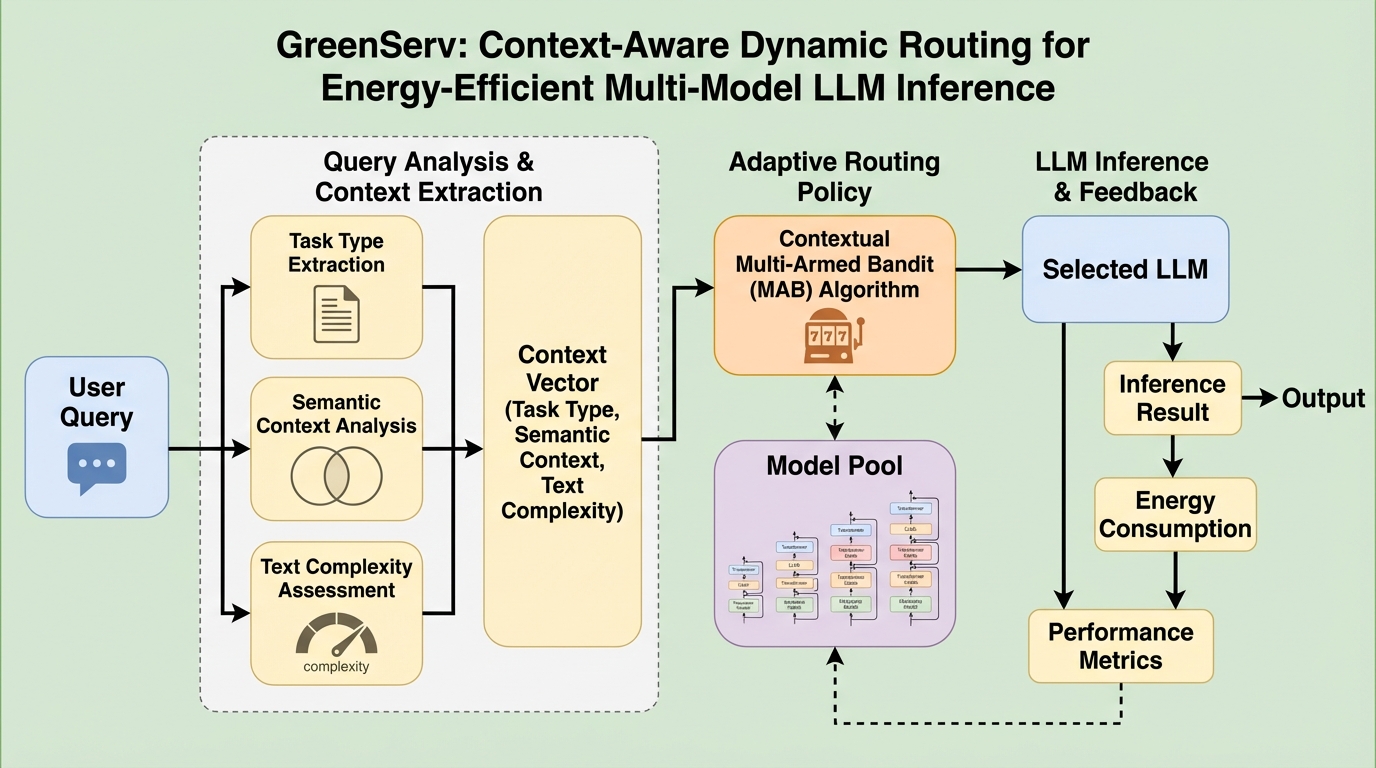
GreenServは、大規模言語モデル(LLM)の推論における膨大なエネルギー消費を削減するために開発された、動的でコンテキストを認識するルーティングフレームワークである。各クエリからタスクの種類や意味的クラスタ、テキストの複雑性などの軽量な特徴を抽出し、文脈付き多腕バンディット(MAB)アルゴリズムを用いて、精度とエネルギー効率のバランスが最も優れたモデルを複数の候補から自動的に選択する。 このシステムは、従来の静的なモデル選択とは異なり、実際の運用を通じてモデルの性能を学習し続けるオンライン学習機能を備えている。これにより、事前の膨大なキャリブレーションを必要とせず、新しいモデルが追加された際にも即座に最適なルーティング戦略に組み込むことが可能となっている。 実験の結果、ランダムなルーティングと比較して精度を22%向上させつつ、累積エネルギー消費を31%削減することに成功した。また、推論時のオーバーヘッドは極めて小さく、実用的な遅延制約を満たしながら、持続可能なAI運用のための高度なトレードオフ制御を実現している。
TL;DR(結論)
GreenServは、大規模言語モデル(LLM)の推論における膨大なエネルギー消費を削減するために開発された、動的でコンテキストを認識するルーティングフレームワークである。各クエリからタスクの種類や意味的クラスタ、テキストの複雑性などの軽量な特徴を抽出し、文脈付き多腕バンディット(MAB)アルゴリズムを用いて、精度とエネルギー効率のバランスが最も優れたモデルを複数の候補から自動的に選択する。 このシステムは、従来の静的なモデル選択とは異なり、実際の運用を通じてモデルの性能を学習し続けるオンライン学習機能を備えている。これにより、事前の膨大なキャリブレーションを必要とせず、新しいモデルが追加された際にも即座に最適なルーティング戦略に組み込むことが可能となっている。 実験の結果、ランダムなルーティングと比較して精度を22%向上させつつ、累積エネルギー消費を31%削減することに成功した。また、推論時のオーバーヘッドは極めて小さく、実用的な遅延制約を満たしながら、持続可能なAI運用のための高度なトレードオフ制御を実現している。
なぜこの問題か
大規模言語モデル(LLM)の急速な普及はAIの新たな時代を切り開いたが、その一方で膨大な計算資源、特に推論時のエネルギー消費が持続可能性の観点から深刻な懸念となっている。学習コストの削減には多くの注目が集まっているが、推論時のリソース需要は見落とされがちである。実際、累積的な推論エネルギーは学習エネルギーを上回る可能性があり、例えばChatGPTの1回のクエリは約2.9Whのエネルギーを消費し、年間では合計10テラワット時に達すると推定されている。データセンターの電力需要は世界的に増加しており、効率的な運用が急務である。 現在のLLM推論の多くは、クエリの複雑さや要求される品質に関わらず、すべてのリクエストを同じ大規模なモデルに送る「一つのモデルですべてを賄う」静的な戦略に依存している。しかし、翻訳のような単純なタスクは、品質をほとんど落とさずに、より小型で安価なモデルで処理できることが研究で示されている。…
核心:何を提案したのか
GreenServの核心的な提案は、推論精度とエネルギー効率のトレードオフを最適化する、動的でコンテキストを認識するルーティングフレームワークの構築である。従来の「カスケード方式」は、小型モデルから順に試行し、品質が不十分な場合に大型モデルへ移行するため、結果として複数の推論が発生し、遅延とコストが増大する欠点があった。これに対し、GreenServは「ルーティング方式」を採用し、各クエリに対して一回のステップで最適なモデルを割り当てることを目指している。 このフレームワークの最大の特徴は、文脈付き多腕バンディット(MAB)アルゴリズムを活用したオンライン学習能力にある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related