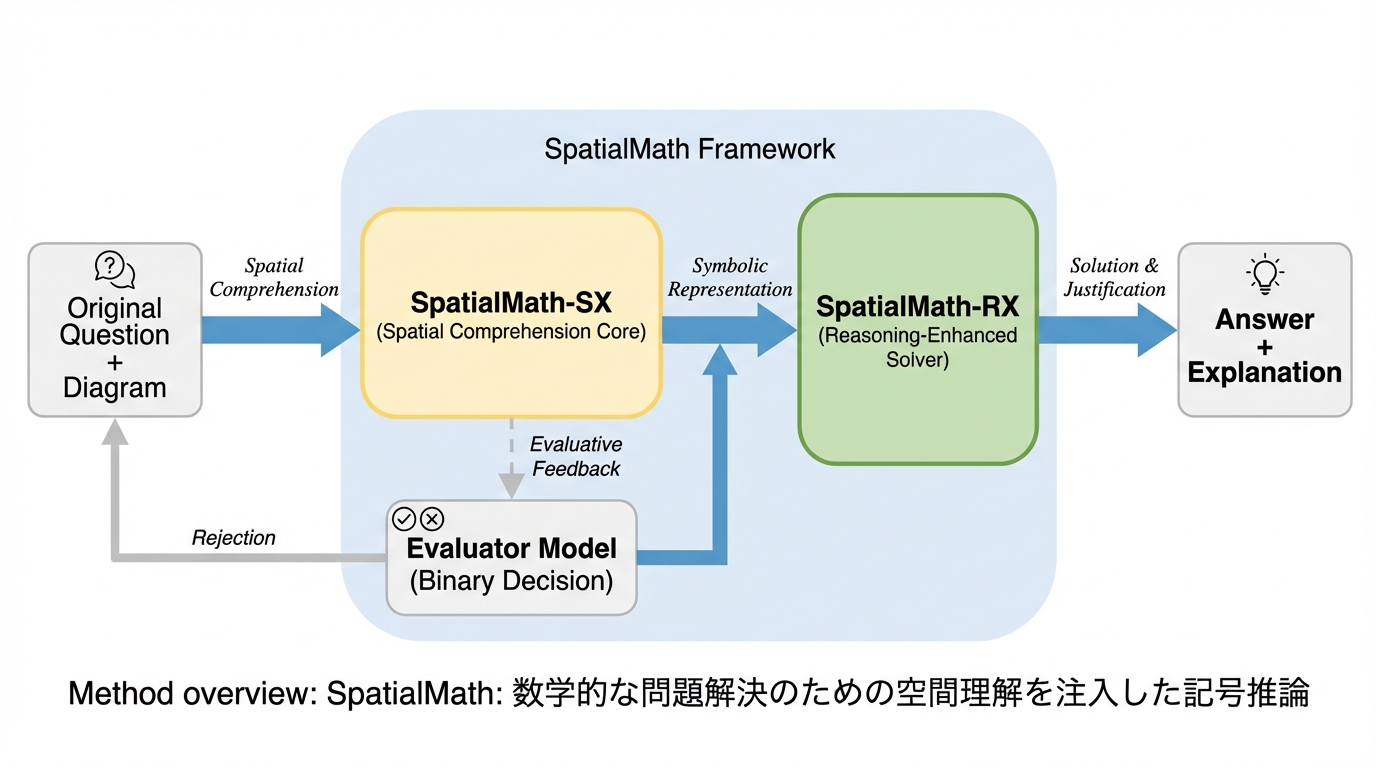
SpatialMath: 数学的な問題解決のための空間理解を注入した記号推論
マルチモーダル中小規模言語モデル(MSLM)が幾何学問題で直面する、視覚的理解と論理的推論の乖離を解消するため、空間情報を記号的推論鎖に統合する新フレームワーク「SpatialMath」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
マルチモーダル中小規模言語モデル(MSLM)が幾何学問題で直面する、視覚的理解と論理的推論の乖離を解消するため、空間情報を記号的推論鎖に統合する新フレームワーク「SpatialMath」が提案されました。
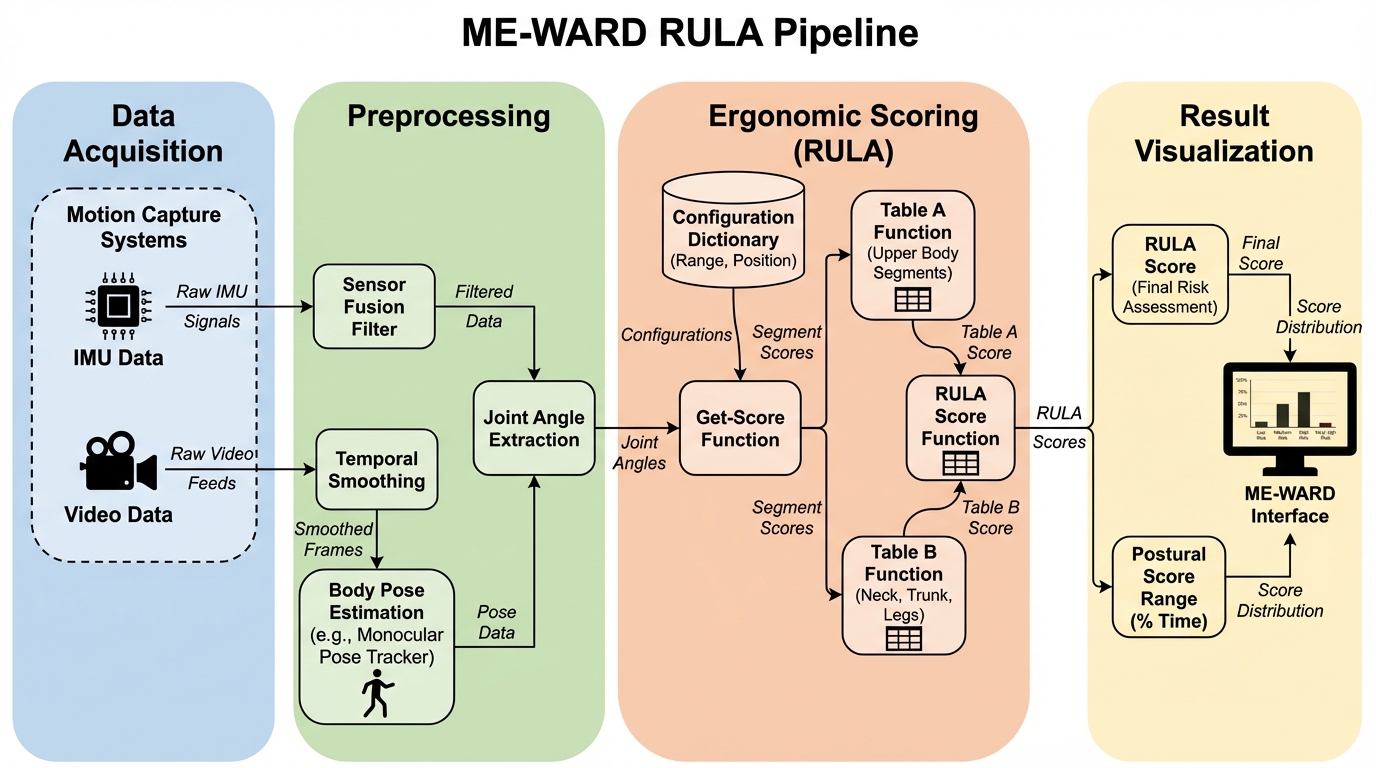
ME-WARDは、慣性計測装置(IMU)とビデオベースのポーズ推定技術を統合し、上肢の姿勢評価手法であるRULAをデジタル化することで、職場における筋骨格系疾患のリスクを自動かつ客観的に評価するマルチモーダルな分析システムである。
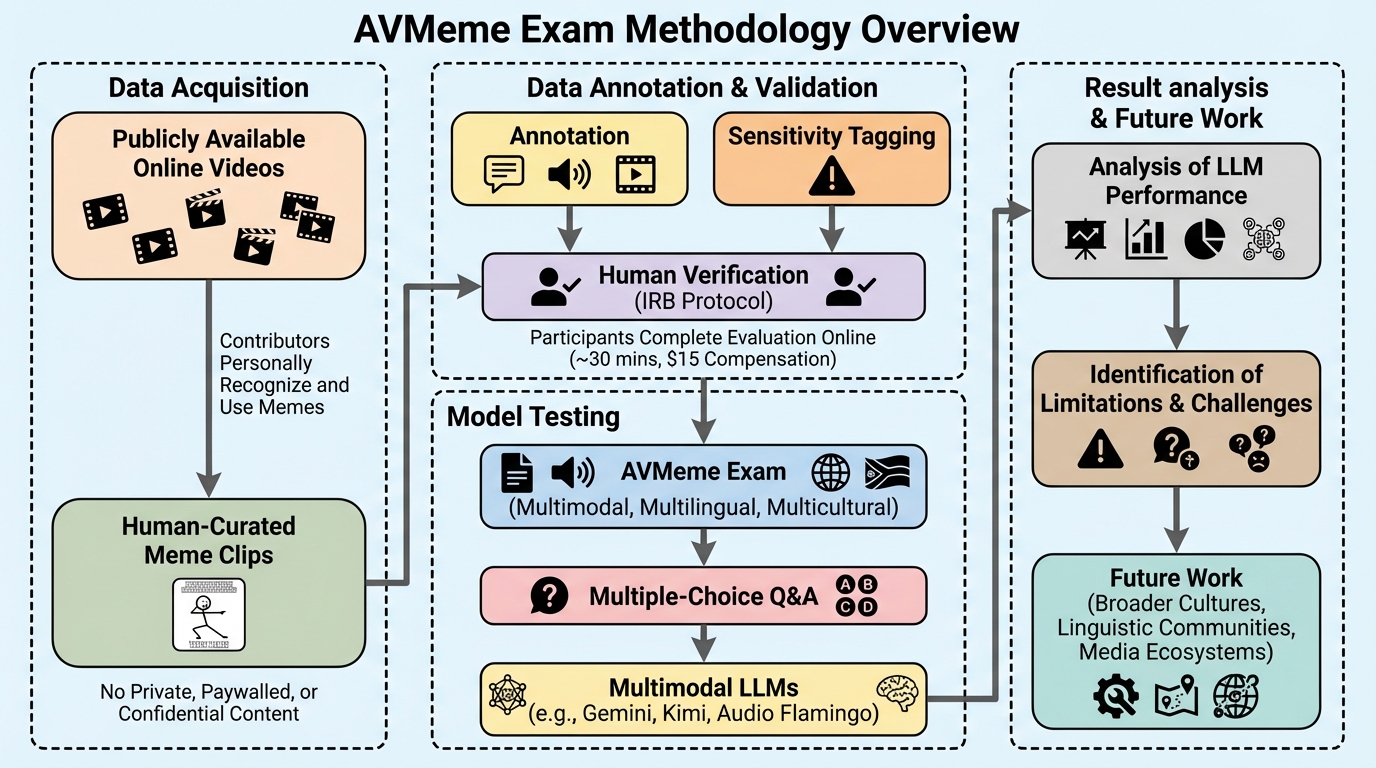
本研究では、インターネット上の音声・映像ミーム1,032件を厳選し、AIモデルが人間の文化的・文脈的な意味をどの程度理解できるかを測定する新しいベンチマーク「AVMeme Exam」を開発しました。
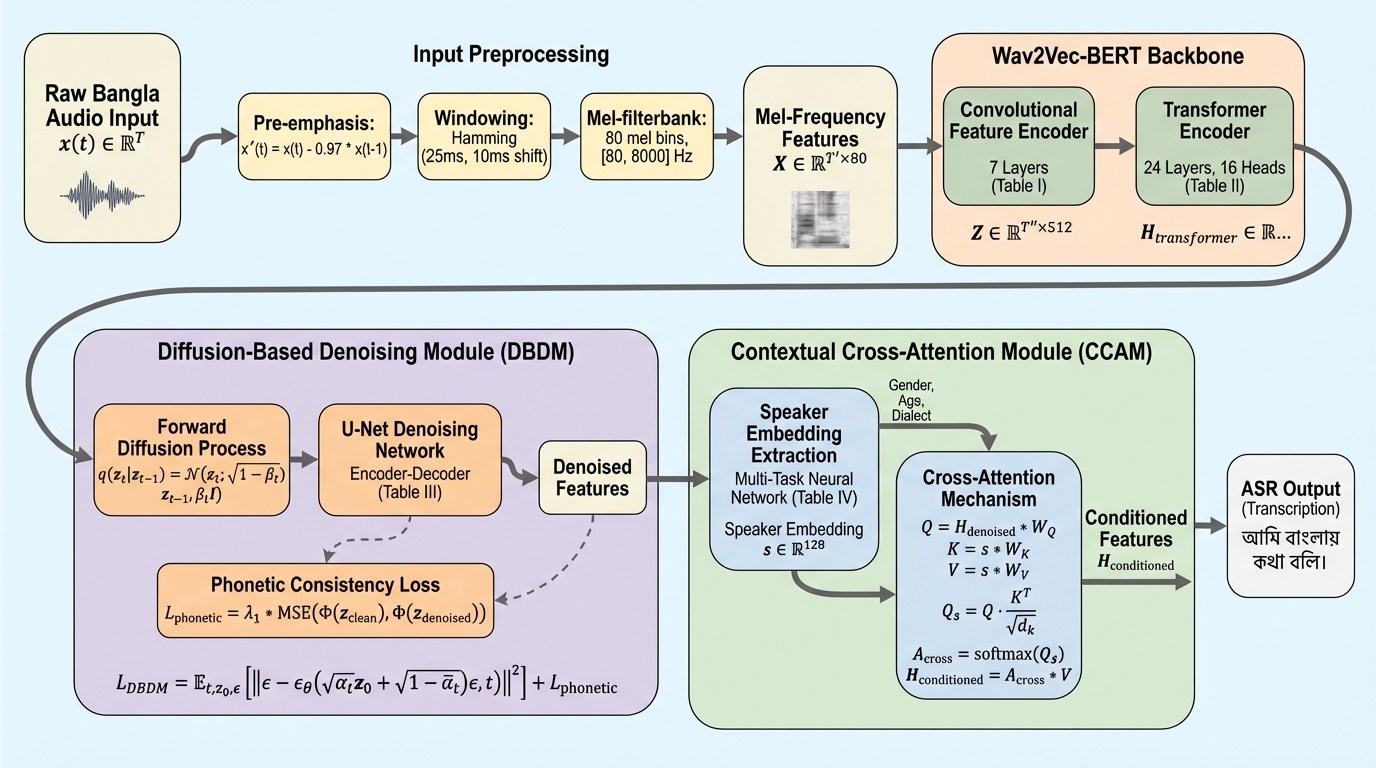
ベンガル語は2億5千万人以上の話者を抱えながら、音声認識(ASR)においてはデータが不足している低リソース言語であり、環境ノイズや多様な方言、複雑な音韻構造が実用化の大きな壁となっていました。本研究が提案するBanglaRobustNetは、Wav2Vec-BERTを基盤に、拡散モデルを用いたノイズ除去モジュールと話者特性を捉えるクロスアテンション機構を統合することで、音韻の正確性を保ちつつノイズ耐性を劇的に向上させています。評価の結果、従来のWhisperやWav2Vec-BERTを大幅に上回る精度を達成し、クリーンな環境で12%、ノイズ環境で18%、方言において15%の単語誤り率(WER)削減を実現し、リアルタイムでの推論効率も確保されています。
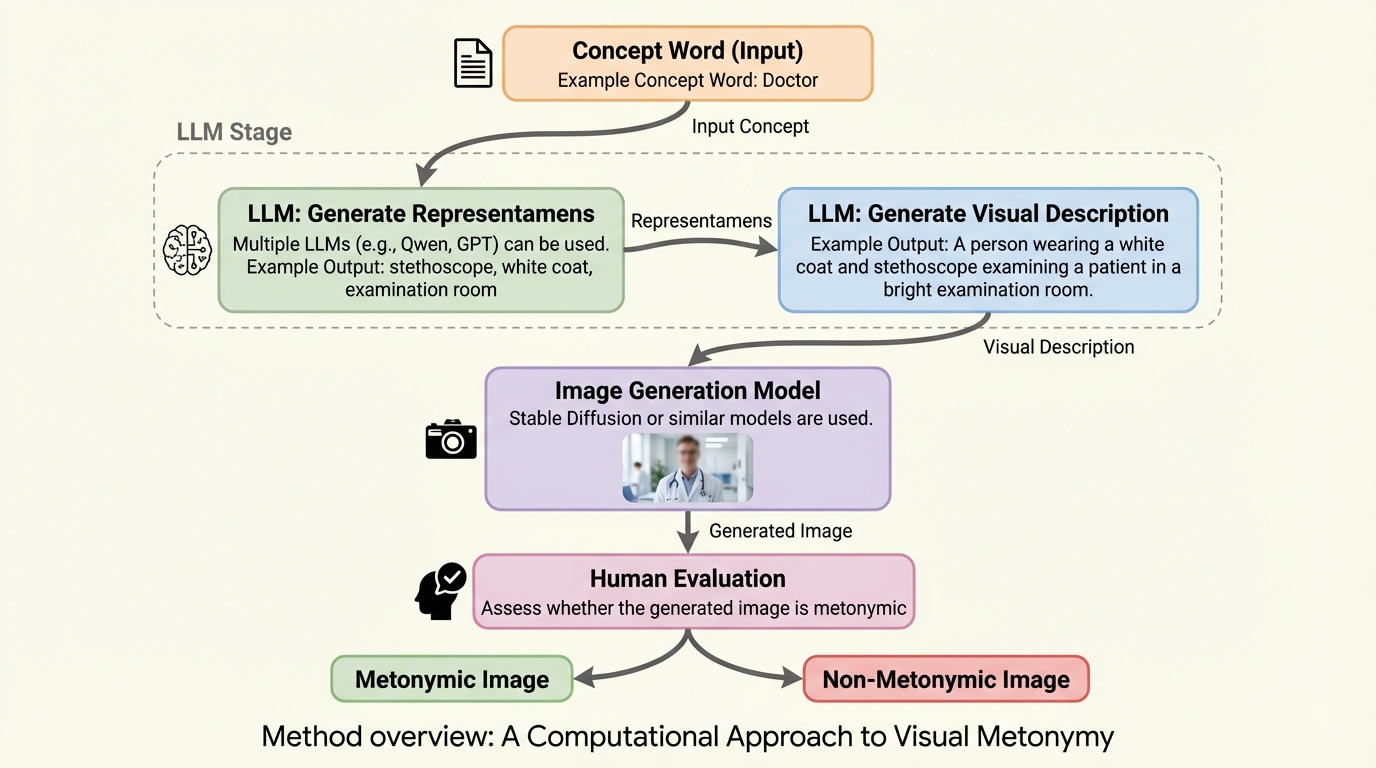
画像が文字通りの意味を超えて、関連する手がかりから対象概念を想起させる「視覚的換喩」について、記号論に基づいた初の計算機的な調査が行われました。大規模言語モデル(LLM)と画像生成モデルを組み合わせ、関連オブジェクトを通じて概念を間接的に表現する新しい生成パイプラインを構築し、2,000問の多肢選択式問題からなるデータセット「ViMET」を開発しました。 検証の結果、最新の視覚言語モデル(VLM)の正解率は65.9%にとどまり、人間の86.9%という精度と比較して21%もの大きな性能差があることが判明し、AIが間接的な視覚的参照を解釈する能力には依然として大きな限界があることが浮き彫りになりました。 この研究は、単なる物体認識を超えた「AIがいかに視覚情報を解釈するか」という認知的な推論能力を評価するための新しい基準を提示しており、文化や文脈、象徴的な関連性を理解する次世代のマルチモーダルAI開発に向けた重要な基礎を築いています。
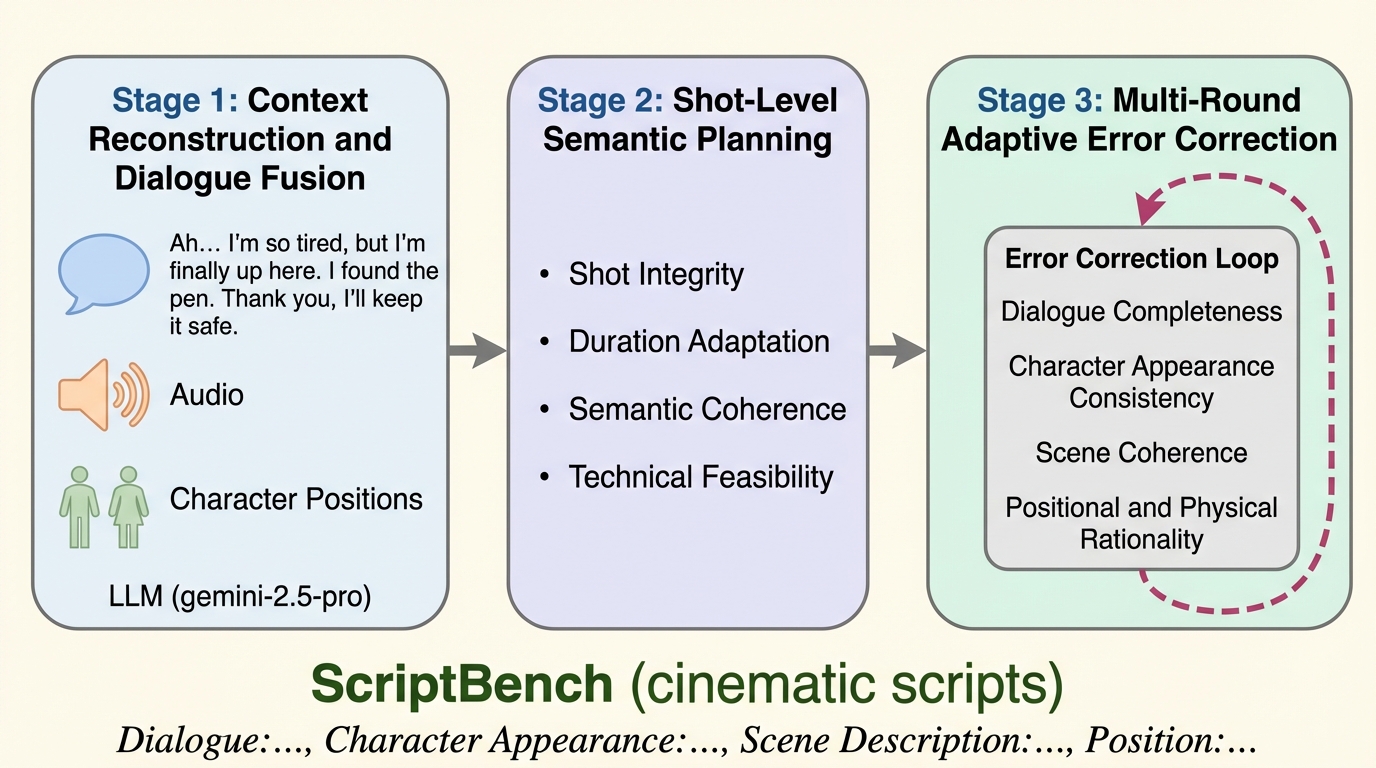
従来の動画生成AIは、対話のような抽象的な概念から一貫した物語を持つ長尺映像を作る際、創作意図と映像表現の間に「意味のギャップ」が生じる課題がありました。本研究では、アルフレッド・ヒッチコックの「映画には脚本が最も重要である」という哲学に基づき、断片的な対話文から詳細な撮影指示を含む脚本を自動生成し、それを基に一貫性のある映像を構築する新しいエージェントフレームワークを提案しています。 専門的な脚本家、監督、批評家の役割を担う3つのエージェントと、大規模データセットScriptBench、そして強化学習(GRPO)を組み合わせることで、既存の動画生成モデルの限界を超えた劇的な緊張感と視覚的一貫性を実現することに成功しました。これにより、キャラクターの同一性や物語の文脈を維持したまま、プロフェッショナルな品質の映画風動画を自動で制作することが可能になります。 本フレームワークは、ScripterAgentによる精密な脚本作成、DirectorAgentによるシーン間の連続性確保、CriticAgentによる多角的な評価という一連のプロセスを通じて、最新の動画生成モデル(Sora2-ProやVeo3.1など)の性能を最大限に引き出します。実験では、脚本への忠実度や映像の連続性を示す新指標VSAにおいて大幅な向上を記録し、自動映画製作における新たなパラダイムを確立しました。
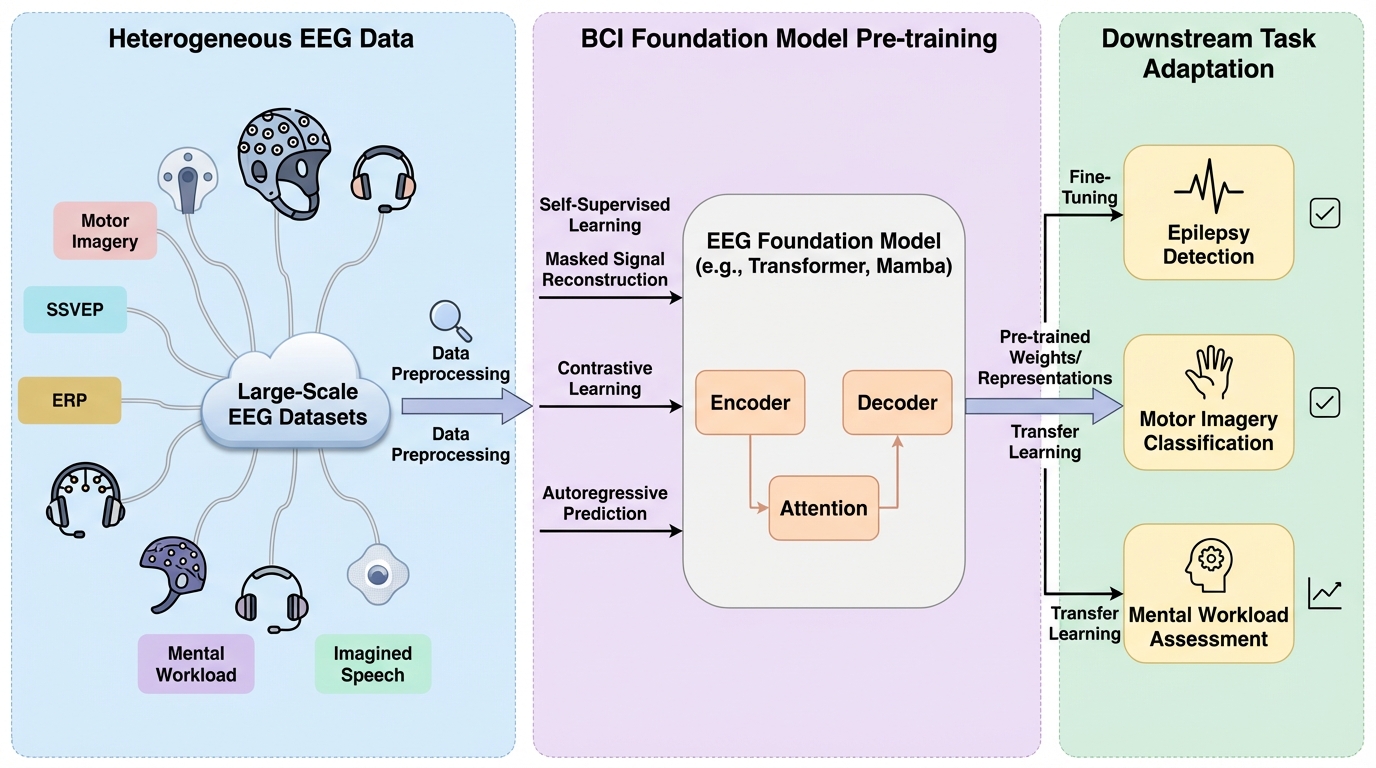
本研究は、急速に拡大する脳波(EEG)基盤モデルの分野を包括的に整理するため、50の代表的なモデルを詳細に調査し、その設計選択をデータ標準化、モデルアーキテクチャ、自己教師あり学習戦略の観点から統一的な分類体系にまとめた。
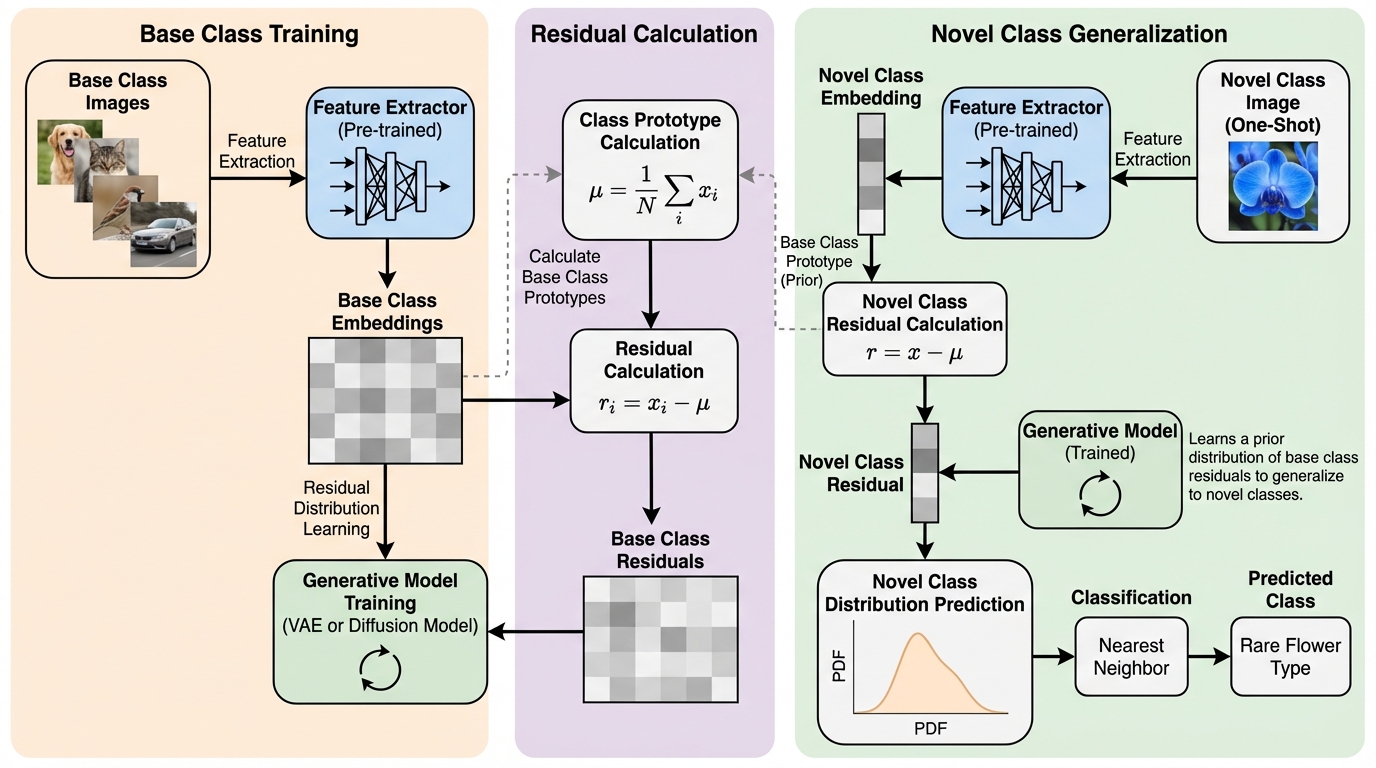
本研究は、わずか1枚の画像から新しい概念を学習する「ワンショットクラス増分学習(1SCIL)」において、データの極端な不足とクラス分布の複雑さに対応するため、特徴空間上での生成モデルを活用する新手法「Gen1S」を提案した。
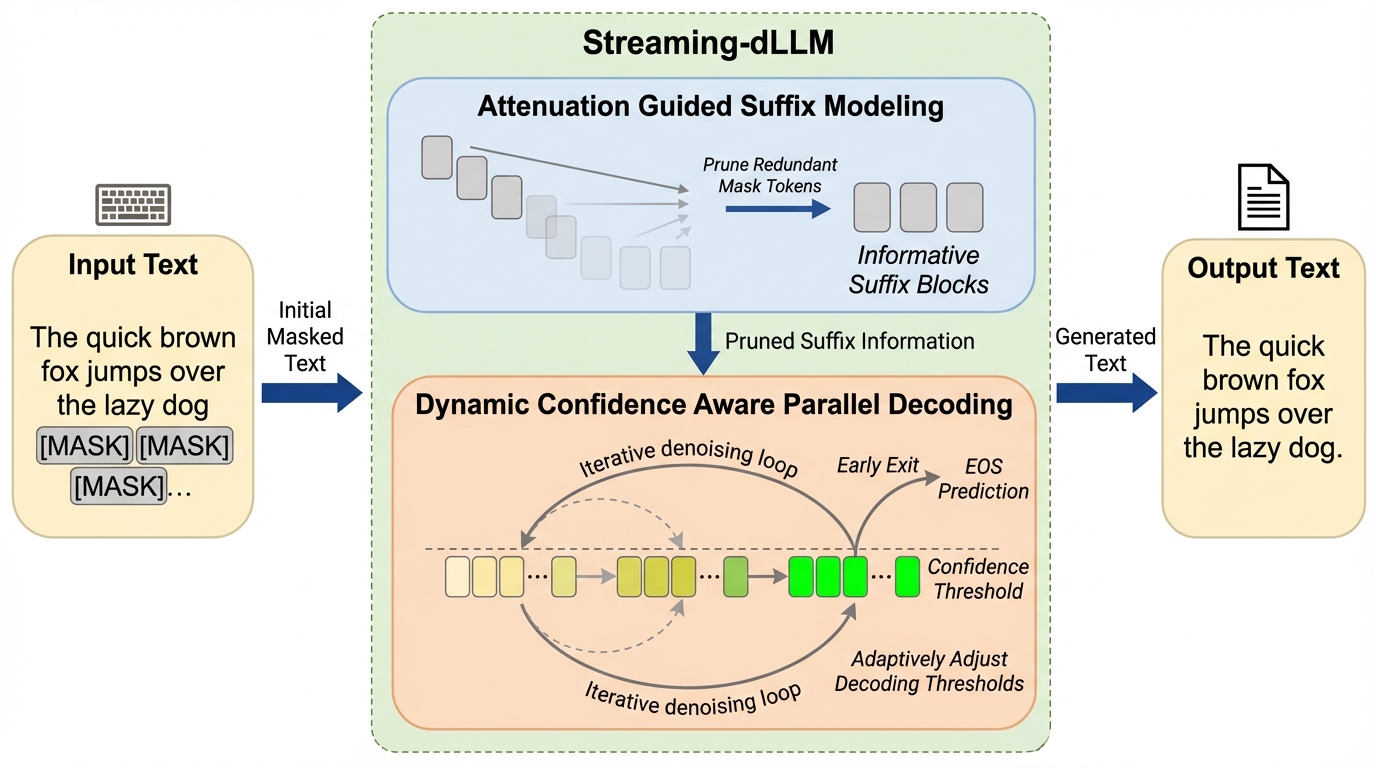
拡散大規模言語モデル(dLLM)は並列デコーディングと双方向アテンションにより高い一貫性を持つが、自己回帰型モデルと比較して推論速度が大幅に遅いという課題がある。 本研究が提案するStreaming-dLLMは、空間的な冗長性を排除する「減衰誘導サフィックスモデリング」と、時間的な非効率性を改善する「動的信頼度認識並列デコーディング」を導入した学習不要のフレームワークである。 検証の結果、生成品質を維持したまま最大68.2倍の推論加速を達成し、既存の手法を大幅に上回るスループットと競争力のある精度を両立することに成功した。
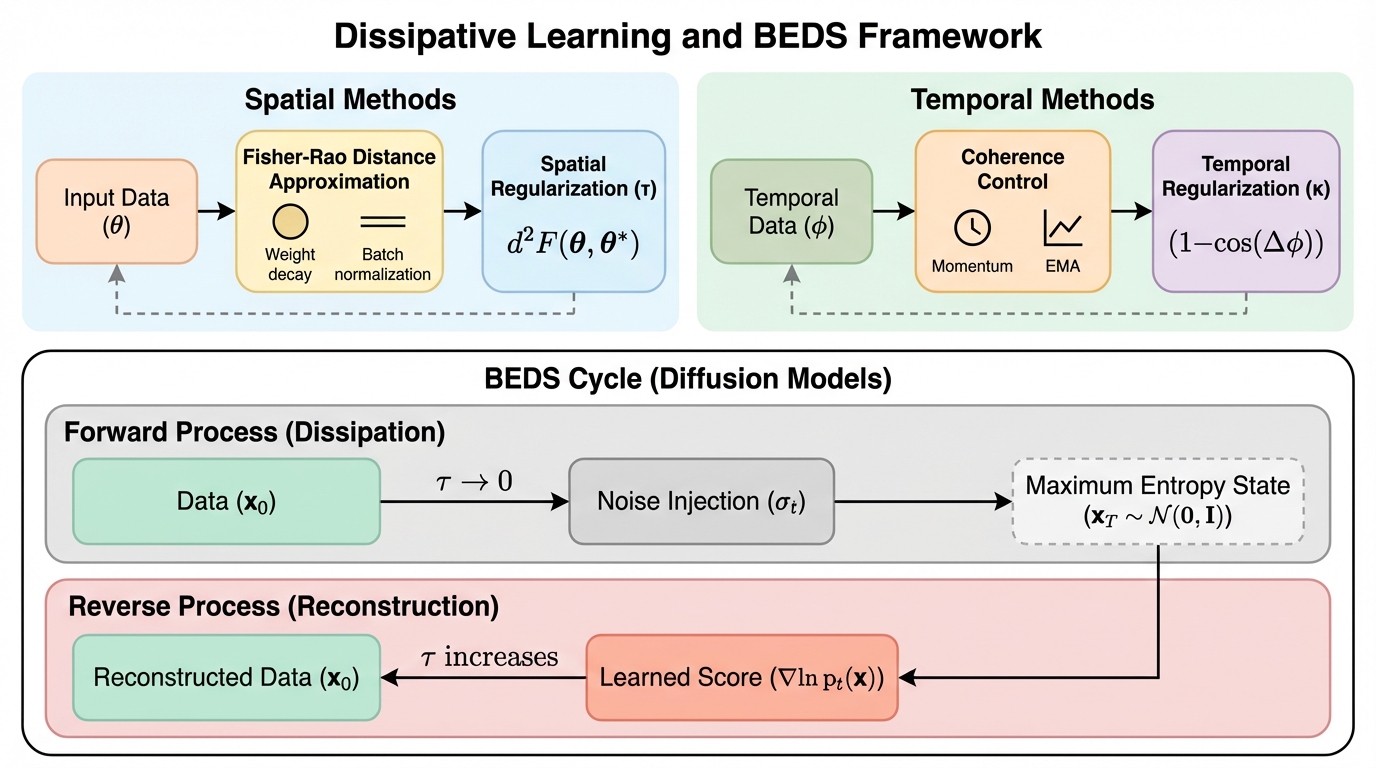
学習を本質的にエネルギーを消費し情報を捨てる「散逸プロセス」と定義し、忘却や正則化をシステムの生存に不可欠な構造的要件として再構築するBEDSフレームワークを提案している。 情報幾何学と熱力学に基づき、フィッシャー・ラオ正則化が最小の散逸で学習を実現する唯一の最適戦略であることを理論的に証明し、既存の多様な機械学習手法を単一の方程式で統一的に説明することに成功した。 過学習を「過剰な結晶化」、壊滅的忘却を「散逸制御の不全」と捉え直し、有限のリソース下で精度と適応性のバランスを維持し続ける「生存可能性」を、従来の評価基準に代わる新たな指標として提示している。