SpatialMath: 数学的な問題解決のための空間理解を注入した記号推論
マルチモーダル中小規模言語モデル(MSLM)が幾何学問題で直面する、視覚的理解と論理的推論の乖離を解消するため、空間情報を記号的推論鎖に統合する新フレームワーク「SpatialMath」が提案されました。
TL;DR(結論)
マルチモーダル中小規模言語モデル(MSLM)が幾何学問題で直面する、視覚的理解と論理的推論の乖離を解消するため、空間情報を記号的推論鎖に統合する新フレームワーク「SpatialMath」が提案されました。 この手法は、図形から構造化された空間表現を抽出する「SpatialMath-SX」と、その情報を基に段階的な推論を行う「SpatialMath-RX」の2段階構成により、視覚依存度の高い問題で最大10.2パーセントポイントの精度向上を実現しています。 幾何学に特化した新データセット「MATHVERSE-PLUS」を導入し、視覚的な知覚を言語的な構造へと変換してから推論に繋げるパイプラインを構築することで、従来のモデルが陥っていた記憶依存の回答パターンを打破し、真の数学的解決能力を高めました。
なぜこの問題か
近年の生成AI、特にマルチモーダル中小規模言語モデル(MSLM)は、画像の説明文生成や一般的な質問応答において目覚ましい成果を上げています。しかし、幾何学的な図形や空間的な推論を必要とする数学の問題においては、依然として大きな課題が残されています。その根本的な原因は、これらのモデルが採用しているビジョンエンコーダにあります。現在のエンコーダの多くは、一般的な画像理解のために最適化されており、数学的なタスクを解くために不可欠な、構造化された記号情報や空間的な関係性を正確に捉えるようには設計されていません。このため、複雑な図形を要素ごとに分解し、それを論理的な推論ステップに結びつけることが困難になっています。 この問題の深刻さは、既存のベンチマーク評価からも明らかになっています。例えば、MathVerseを用いた調査では、テキスト情報が豊富な問題では良好な成績を収めるモデルであっても、図形に基づいた角度の計算や座標を用いた証明など、視覚情報が密集したタスクでは極端に性能が低下することが示されました。…
核心:何を提案したのか
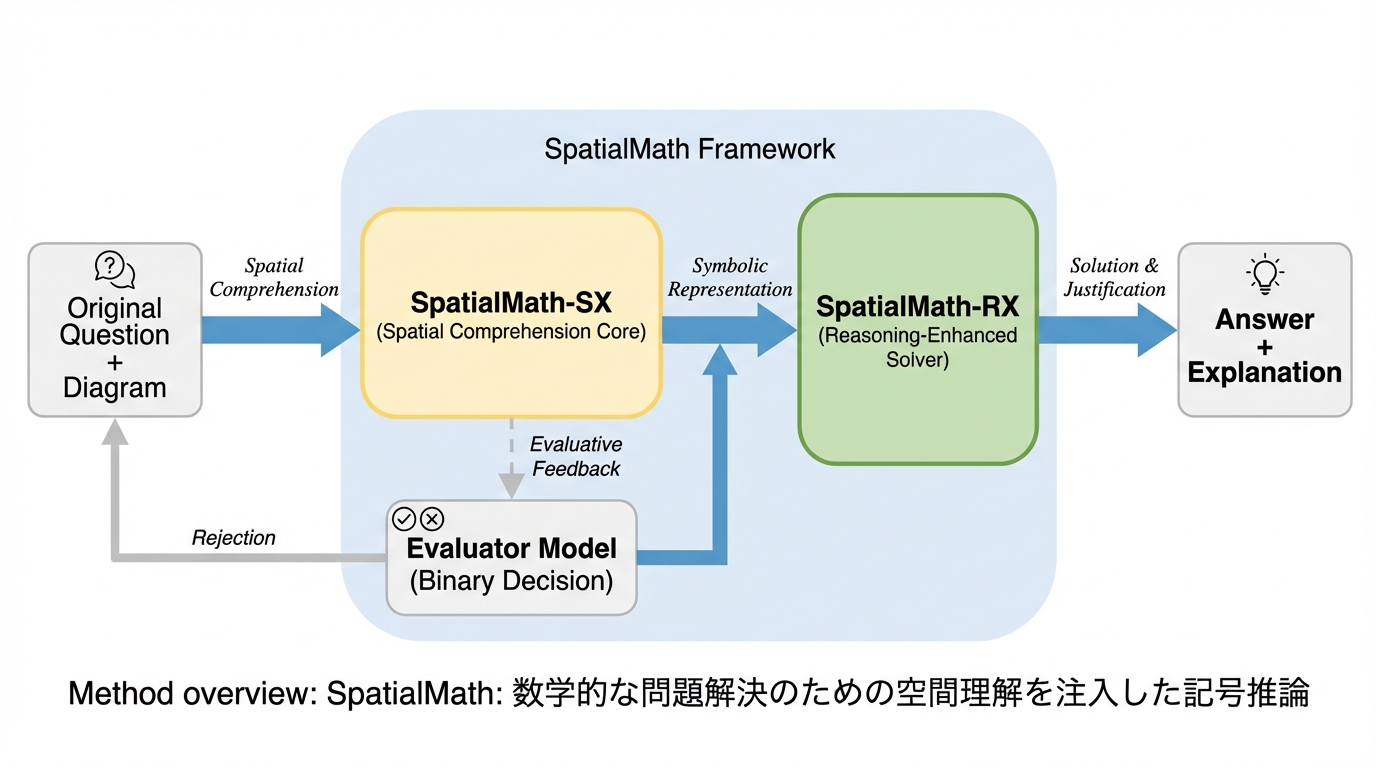
本研究では、視覚的な理解を記号的な推論プロセスに明示的に注入するための新しいフレームワーク「SpatialMath」を提案しました。このフレームワークの核心は、知覚から推論へと至るプロセスを構造化されたパイプラインとして再構築することにあります。SpatialMathは、役割の異なる2つの主要なモジュール、すなわち「SpatialMath-SX(空間理解コア)」と「SpatialMath-RX(推論注入コア)」によって構成されています。これらは、視覚的な情報を一度言語的な構造へと変換し、その構造を基に論理を組み立てるという、人間が数学の問題を解く際のアプローチを模倣しています。 1つ目のモジュールであるSpatialMath-SXは、視覚的な数学コンテンツから構造化された空間理解を抽出することに特化したビジョン言語モデルです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related