Streaming-dLLM:サフィックス剪定と動的デコーディングによる拡散LLMの加速
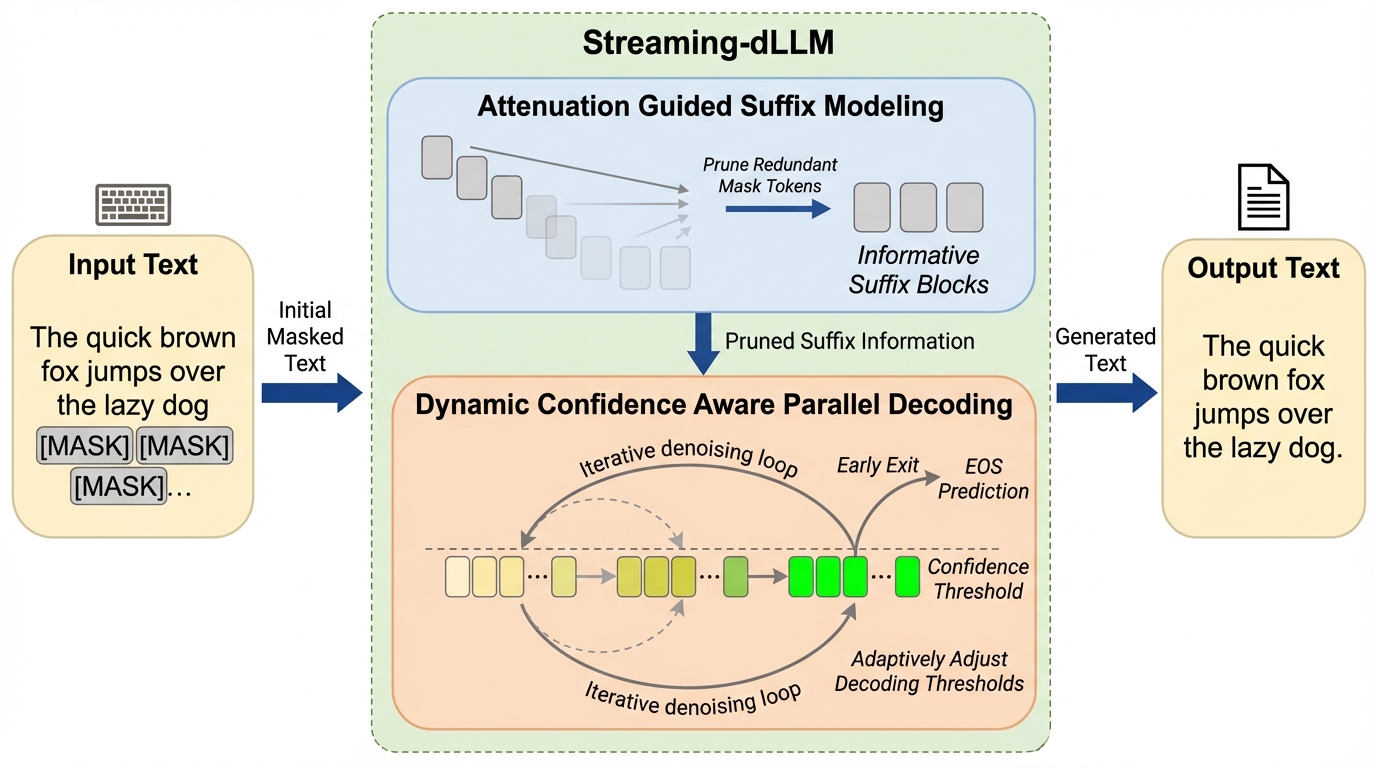
拡散大規模言語モデル(dLLM)は並列デコーディングと双方向アテンションにより高い一貫性を持つが、自己回帰型モデルと比較して推論速度が大幅に遅いという課題がある。 本研究が提案するStreaming-dLLMは、空間的な冗長性を排除する「減衰誘導サフィックスモデリング」と、時間的な非効率性を改善する「動的信頼度認識並列デコーディング」を導入した学習不要のフレームワークである。 検証の結果、生成品質を維持したまま最大68.2倍の推論加速を達成し、既存の手法を大幅に上回るスループットと競争力のある精度を両立することに成功した。
TL;DR(結論)
拡散大規模言語モデル(dLLM)は並列デコーディングと双方向アテンションにより高い一貫性を持つが、自己回帰型モデルと比較して推論速度が大幅に遅いという課題がある。 本研究が提案するStreaming-dLLMは、空間的な冗長性を排除する「減衰誘導サフィックスモデリング」と、時間的な非効率性を改善する「動的信頼度認識並列デコーディング」を導入した学習不要のフレームワークである。 検証の結果、生成品質を維持したまま最大68.2倍の推論加速を達成し、既存の手法を大幅に上回るスループットと競争力のある精度を両立することに成功した。
なぜこの問題か
拡散大規模言語モデル(dLLM)は、自然言語生成における有望なパラダイムとして注目を集めている。 従来の自己回帰型モデルがトークンを一つずつ順番に生成するのに対し、dLLMは並列デコーディングと双方向アテンションを活用する。 この仕組みにより、シーケンスの全位置にわたる情報を同時に統合することが可能となり、優れたグローバルな一貫性と意味的な整合性を実現できる。 しかし、このような利点がある一方で、dLLMの推論速度は自己回帰型モデルに比べて著しく遅いという現実がある。 この速度の差が生じる主な原因は、拡散デコーディングの本質的な性質に由来している。 具体的には、デノイジングのステップが進むにつれてトークンの表現が連続的に変化するため、自己回帰型モデルで高度に最適化されているKVキャッシュの再利用が困難である。 また、並列生成はデコーディングの不確実性に対して敏感であり、品質を維持するために追加のデノイジング反復が必要になることが多い。 既存の研究では、KVキャッシュの限定的な再利用やヒューリスティックなデコーディングによる加速が試みられてきた。…
核心:何を提案したのか
本研究は、dLLMの推論を加速させるための学習不要なフレームワークである「Streaming-dLLM」を提案した。 このフレームワークの核心は、空間的および時間的な次元の両方で冗長な計算を段階的に排除し、ブロック単位の拡散デコーディングを合理化することにある。 空間的な冗長性に対しては、「減衰誘導サフィックスモデリング(Attenuation Guided Suffix Modeling)」を導入した。 これは、現在のブロックを生成する際に最も重要な構造的ヒントのみを保持し、冗長なサフィックスのアテンションを剪定する手法である。 時間的な非効率性に対しては、「動的信頼度認識並列デコーディング(Dynamic Confidence Aware Parallel Decoding)」を提案した。 この戦略は、ブロック内での拡散反復中に変化するトークンの信頼度分布に応じて、デコーディングの閾値を適応的に調整するものである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related