視覚的換喩への計算論的アプローチ
画像が文字通りの意味を超えて、関連する手がかりから対象概念を想起させる「視覚的換喩」について、記号論に基づいた初の計算機的な調査が行われました。大規模言語モデル(LLM)と画像生成モデルを組み合わせ、関連オブジェクトを通じて概念を間接的に表現する新しい生成パイプラインを構築し、2,000問の多肢選択式問題からなるデータセット「ViMET」を開発しました。 検証の結果、最新の視覚言語モデル(VLM)の正解率は65.9%にとどまり、人間の86.9%という精度と比較して21%もの大きな性能差があることが判明し、AIが間接的な視覚的参照を解釈する能力には依然として大きな限界があることが浮き彫りになりました。 この研究は、単なる物体認識を超えた「AIがいかに視覚情報を解釈するか」という認知的な推論能力を評価するための新しい基準を提示しており、文化や文脈、象徴的な関連性を理解する次世代のマルチモーダルAI開発に向けた重要な基礎を築いています。
TL;DR(結論)
画像が文字通りの意味を超えて、関連する手がかりから対象概念を想起させる「視覚的換喩」について、記号論に基づいた初の計算機的な調査が行われました。大規模言語モデル(LLM)と画像生成モデルを組み合わせ、関連オブジェクトを通じて概念を間接的に表現する新しい生成パイプラインを構築し、2,000問の多肢選択式問題からなるデータセット「ViMET」を開発しました。 検証の結果、最新の視覚言語モデル(VLM)の正解率は65.9%にとどまり、人間の86.9%という精度と比較して21%もの大きな性能差があることが判明し、AIが間接的な視覚的参照を解釈する能力には依然として大きな限界があることが浮き彫りになりました。 この研究は、単なる物体認識を超えた「AIがいかに視覚情報を解釈するか」という認知的な推論能力を評価するための新しい基準を提示しており、文化や文脈、象徴的な関連性を理解する次世代のマルチモーダルAI開発に向けた重要な基礎を築いています。
なぜこの問題か
画像は、そこに直接描かれているもの以上の内容を伝えることが多々あります。例えば、一揃いの道具が特定の職業を示唆したり、文化的な工芸品が特定の伝統を想起させたりすることがあります。このような間接的な視覚的参照は「視覚的換喩(Visual Metonymy)」と呼ばれ、視聴者に対して、明示的な描写ではなく関連する手がかりを通じて対象となる概念を復元するように促す手法です。広告や芸術の分野では、製品やブランドのアイデンティティを指し示すために、視覚的な比喩よりも説得力があり機能的な戦略として広く利用されています。しかし、これまでのマルチモーダルな自然言語処理(NLP)の研究において、この視覚的換喩はほとんど未開拓の領域でした。 既存のマルチモーダルベンチマークの多くは、モデルが「何を見ているか」という物体認識やキャプションの整合性に焦点を当てており、モデルが視覚情報を「どのように解釈しているか」という深い理解を評価できていないという課題があります。…
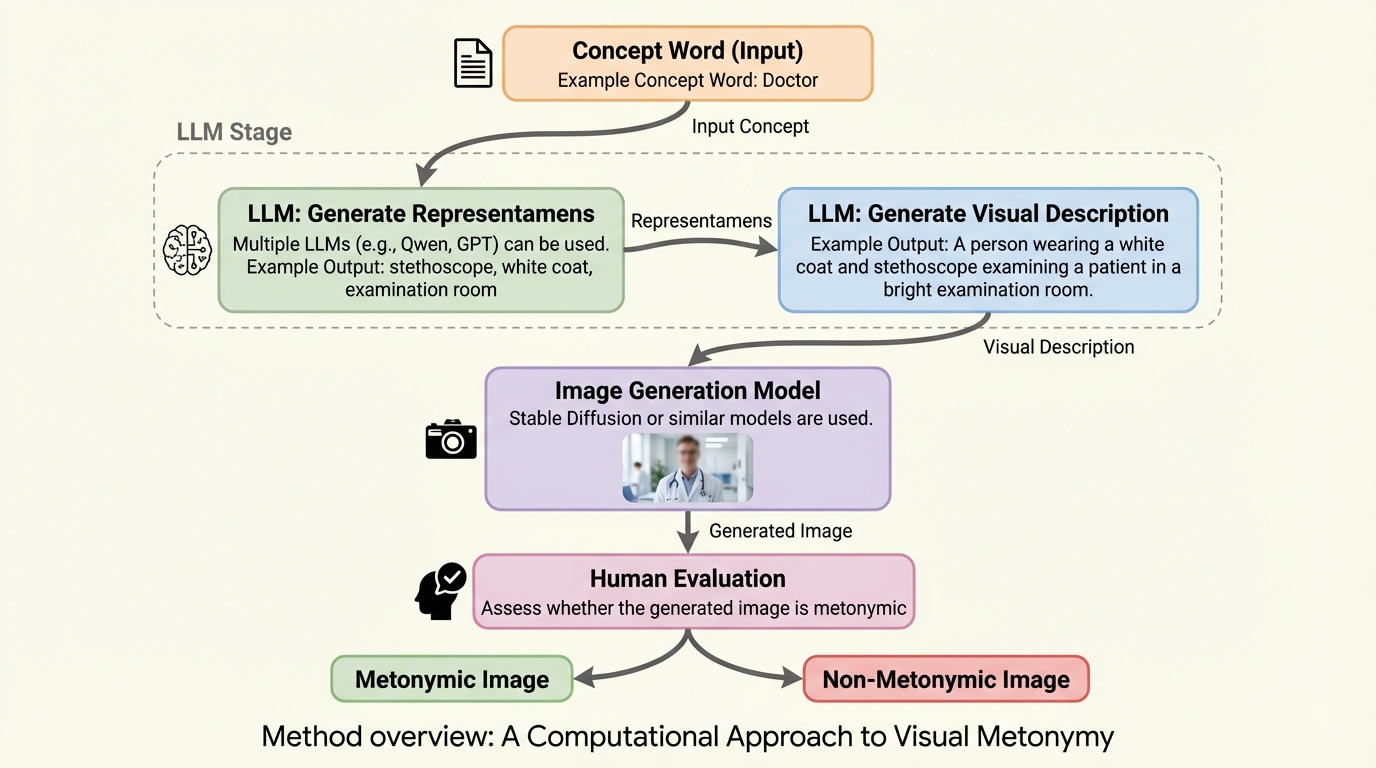
核心:何を提案したのか
本研究では、視覚的換喩に関する初の計算機的な調査を提示し、記号論の理論に基づいた新しい画像生成パイプラインを提案しました。このパイプラインは、チャールズ・サンダース・パースの記号論的三位一体(Semiotic Triad)という理論的枠組みを基盤としています。この理論では、表現される実世界の見念である「対象(Object)」、それを象徴する知覚可能な形式である「表現体(Representamen)」、そして観察者の心の中に形成される意味である「解釈体(Interpretant)」の三つの要素の相互作用によって意味が構築されると考えます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related