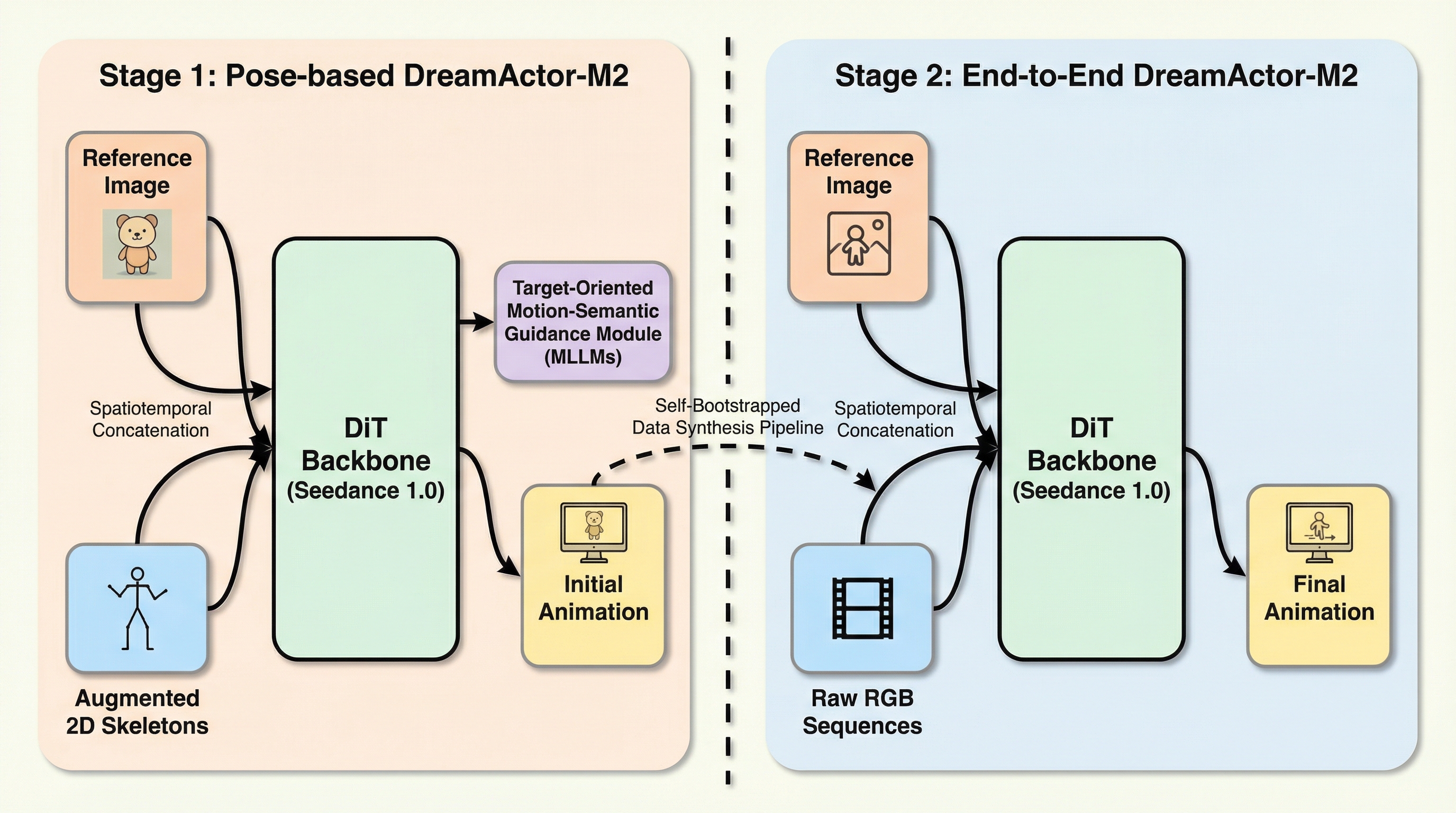
DreamActor-M2:時空間インコンテキスト学習による汎用キャラクター画像アニメーション
DreamActor-M2は、静止画のキャラクターに任意の動画の動きを転送する新しいアニメーション手法であり、情報の注入を「インコンテキスト学習」として再定義することで、外見の維持と動きの再現を高い次元で両立することに成功しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
DreamActor-M2は、静止画のキャラクターに任意の動画の動きを転送する新しいアニメーション手法であり、情報の注入を「インコンテキスト学習」として再定義することで、外見の維持と動きの再現を高い次元で両立することに成功しました。
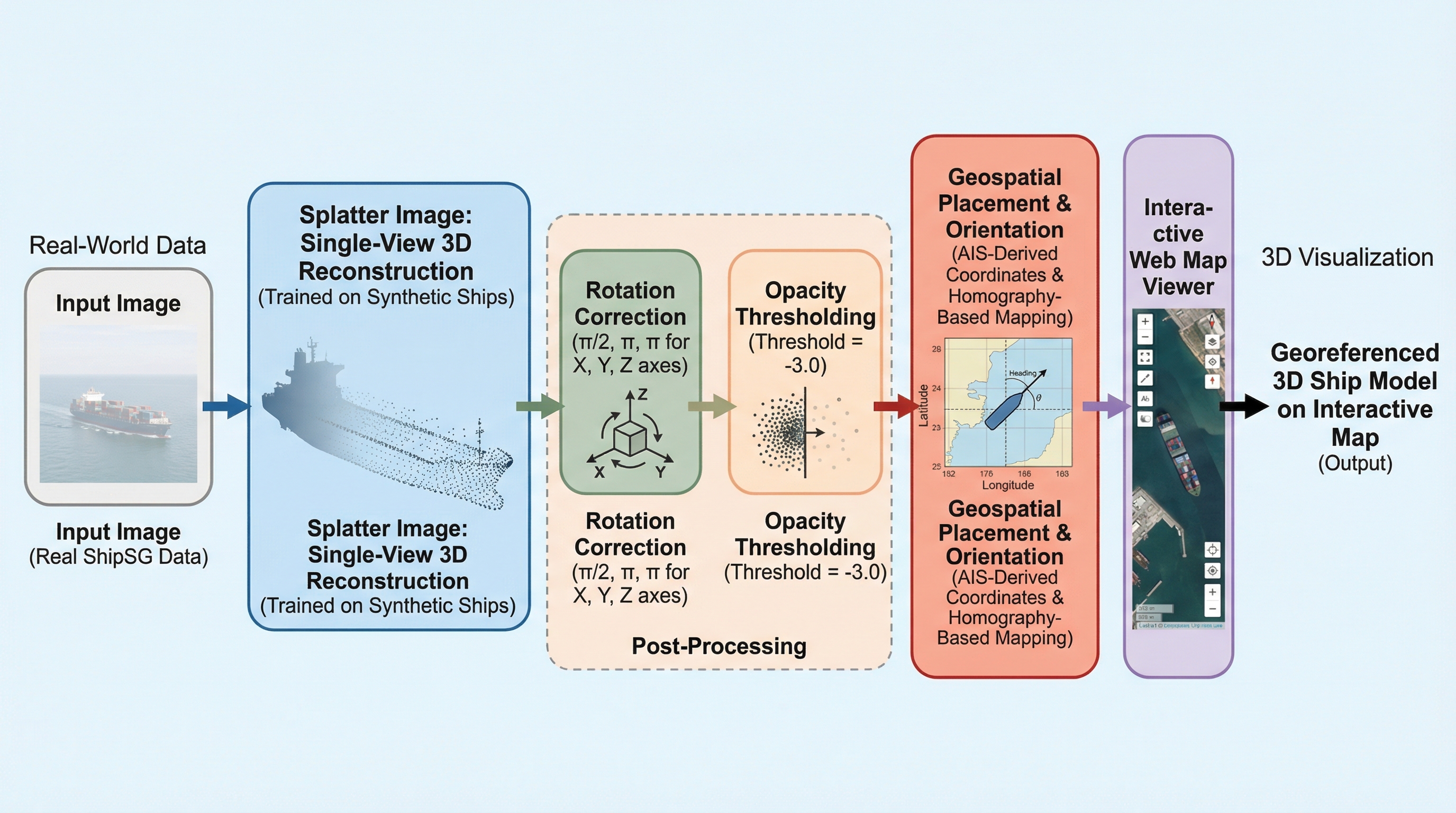
本研究は、実世界の3Dアノテーションを一切必要とせず、完全に合成データのみで学習を行うことで、単一の画像から船舶の3Dモデルを再構成する効率的なパイプラインを提案しています。 3Dガウス表現を用いるSplatter Imageネットワークを基盤とし、ShapeNetの船舶データと独自に作成した高精度な合成船舶データセットの2段階でファインチューニングを行うことで、合成データと実データのドメインギャップを克服しています。 YOLOv8によるセグメンテーション、AISメタデータを用いた実寸スケーリング、地理参照によるWebマップ上への配置を統合しており、港湾監視や船舶の寸法検証などの実用的な海洋状況把握を支援するシステムとして機能します。
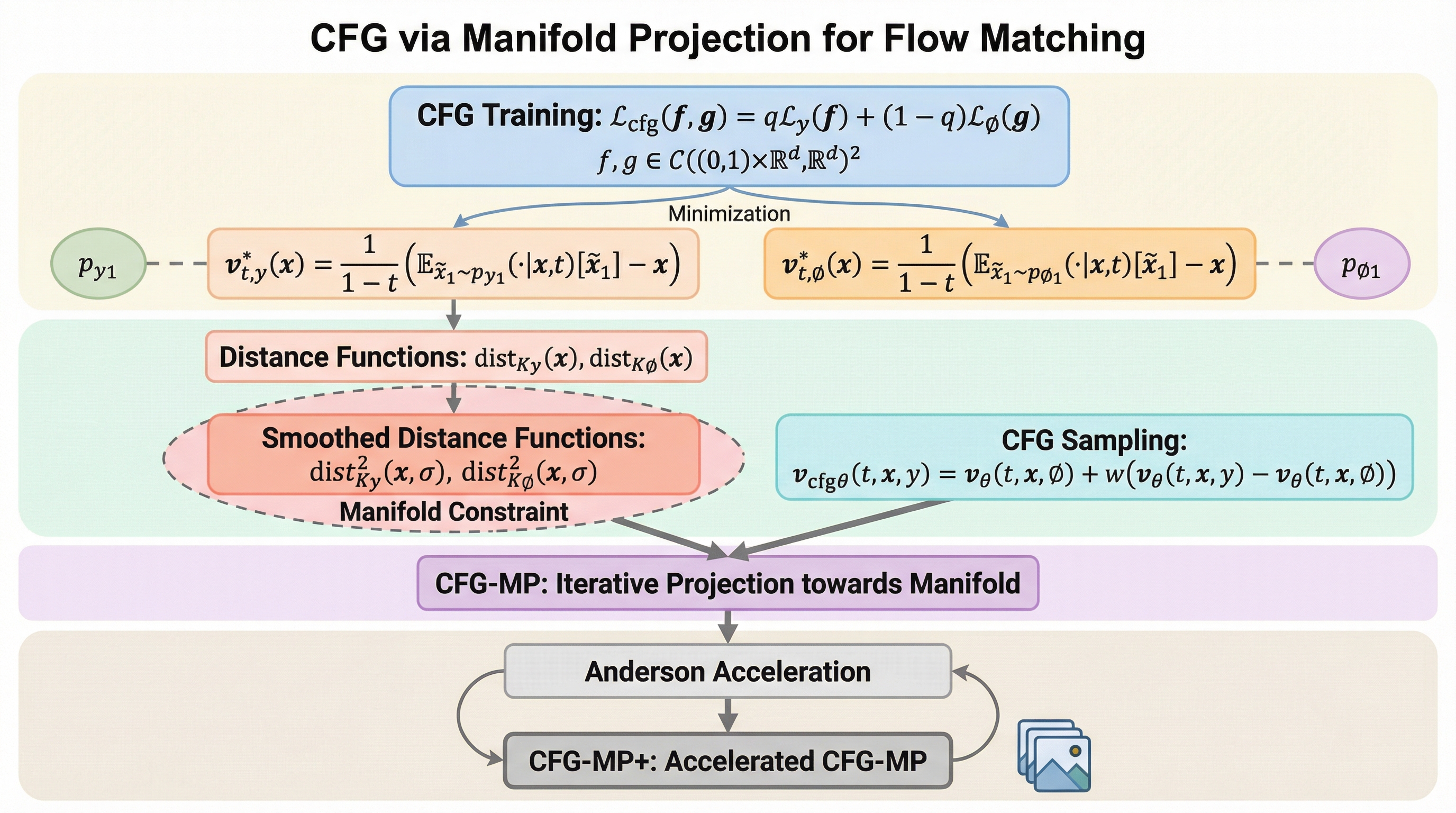
フローマッチングにおける分類器なしガイダンス(CFG)を最適化の観点から再解釈し、生成プロセスをターゲット画像集合への距離を最小化するホモトピー最適化として定義することで、サンプリングの精度を向上させる新手法「CFG-MP」を提案した。
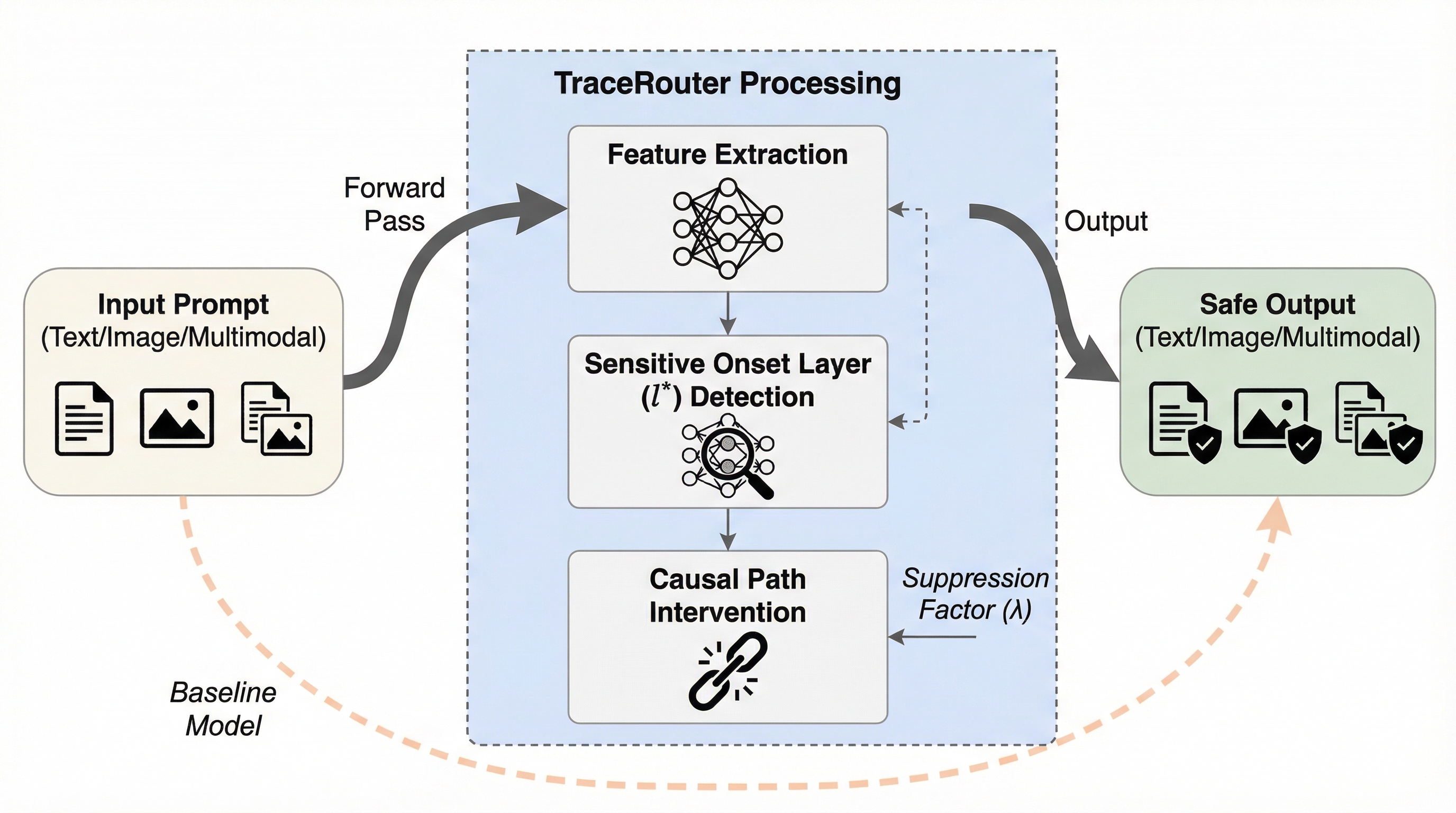
TraceRouterは、大規模基盤モデルにおける有害情報の伝播を、個別のニューロン単位ではなく複数の層にまたがる「経路(パス)」のレベルで特定し遮断する新しい安全フレームワークである。 従来の防御手法が依存していた局所性仮説の限界を打破し、注意力の分散分析とスパース自己符号化器(SAE)を用いて有害なセマンティクスの回路を精密に特定し、特徴影響スコア(FIS)に基づき因果的な伝播を物理的に断ち切る。 画像生成、言語生成、マルチモーダルの各分野で検証され、モデル本来の生成品質や汎用的な推論能力を維持したまま、敵対的な脱獄攻撃に対しても極めて高い防御成功率と堅牢性を実現することに成功した。
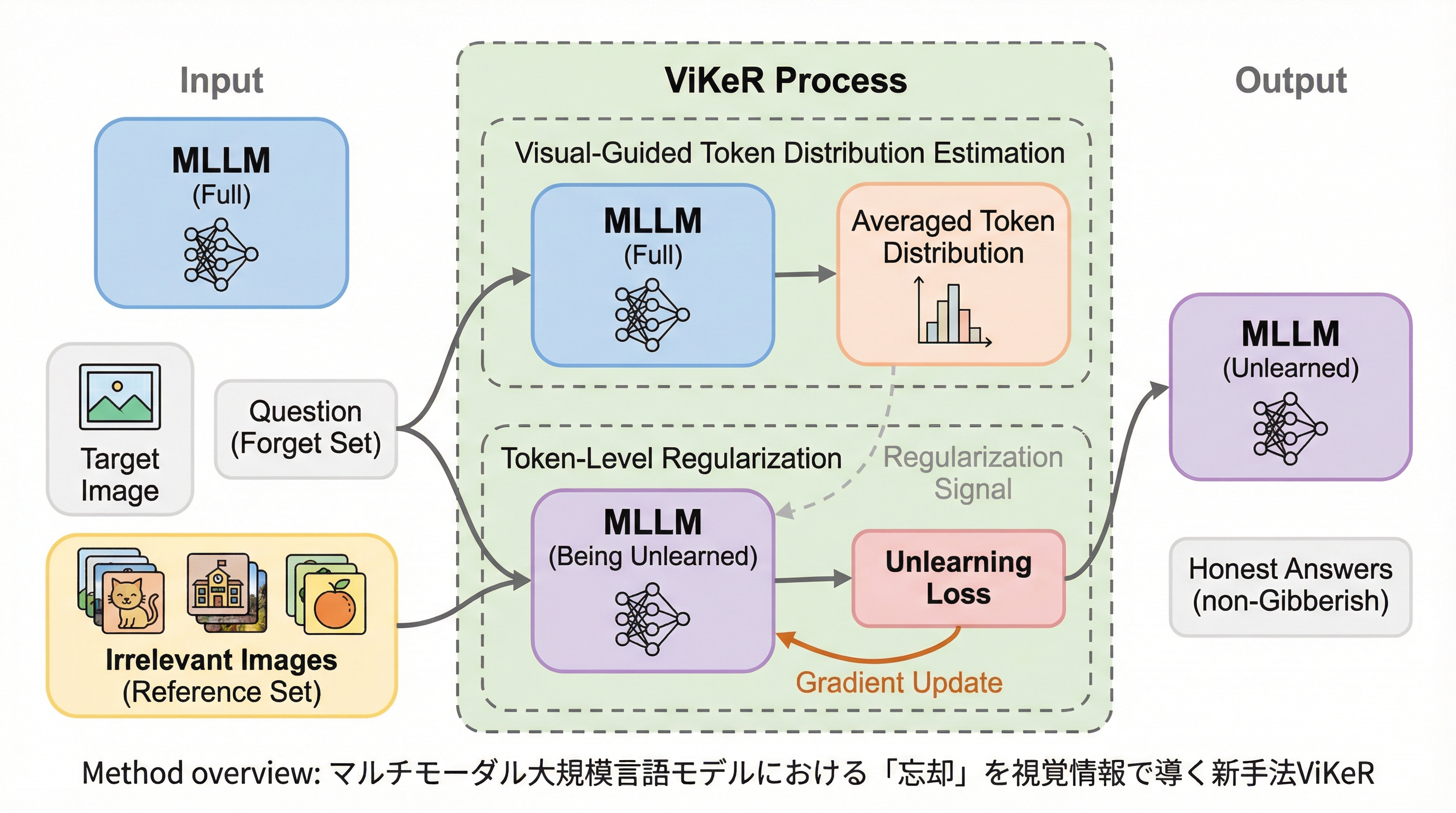
マルチモーダル大規模言語モデル(MLLM)において、特定の個人情報や著作権データを消去する際、従来のテキストベースの手法では文法構造を司る単語まで損なわれ「This am」のような言語崩壊を招く課題があったが、本研究では視覚情報を手がかりに重要な情報を識別する新手法「ViKeR」を提案した。
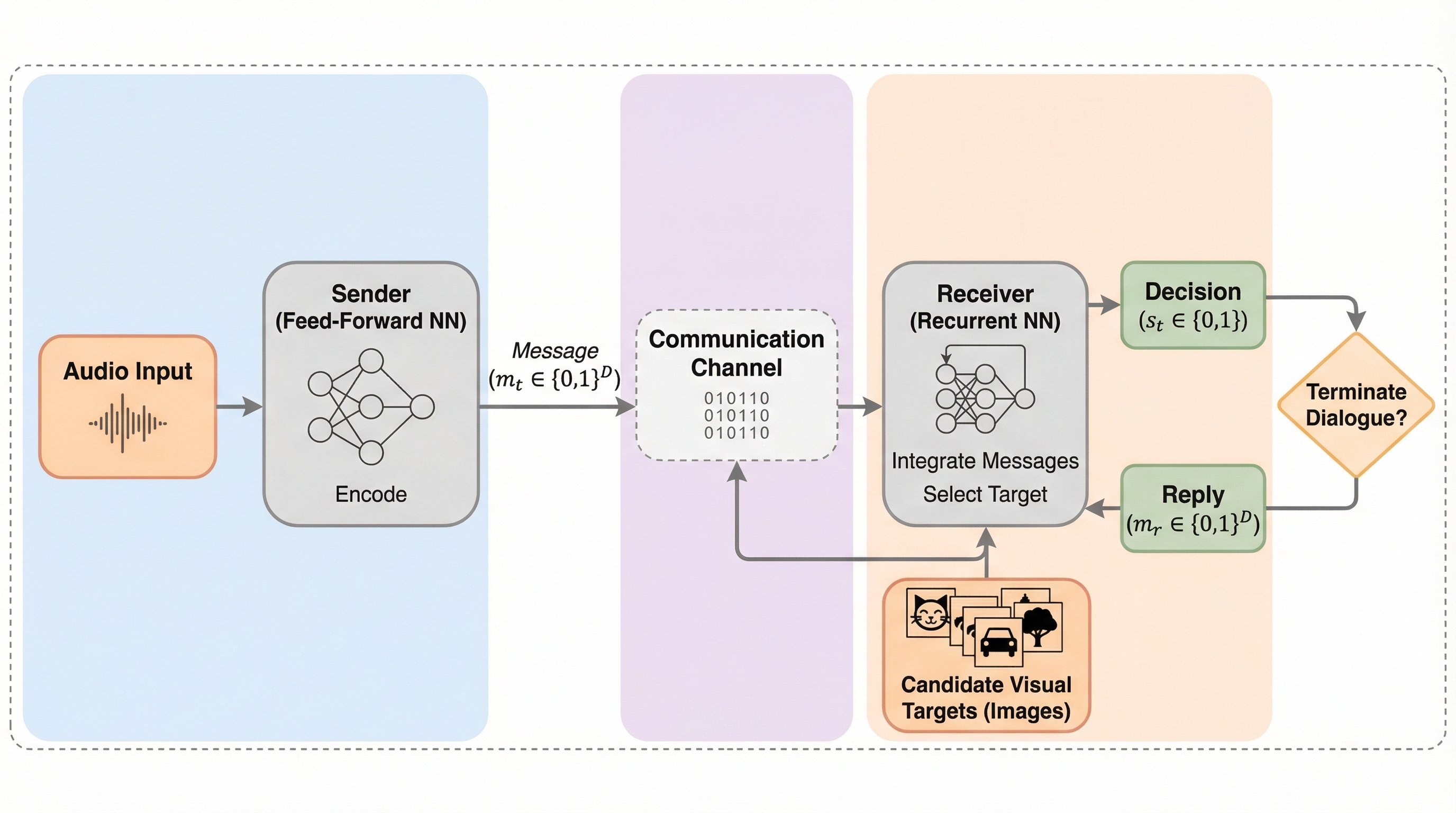
本研究は、送信者が「音声」を聞き、受信者が「画像」を見るという、互いに異なる知覚モダリティ(感覚器)を持つ異種マルチエージェント間において、共通の知覚基盤がない状態からどのようにコミュニケーションが創発するかを調査したものです。
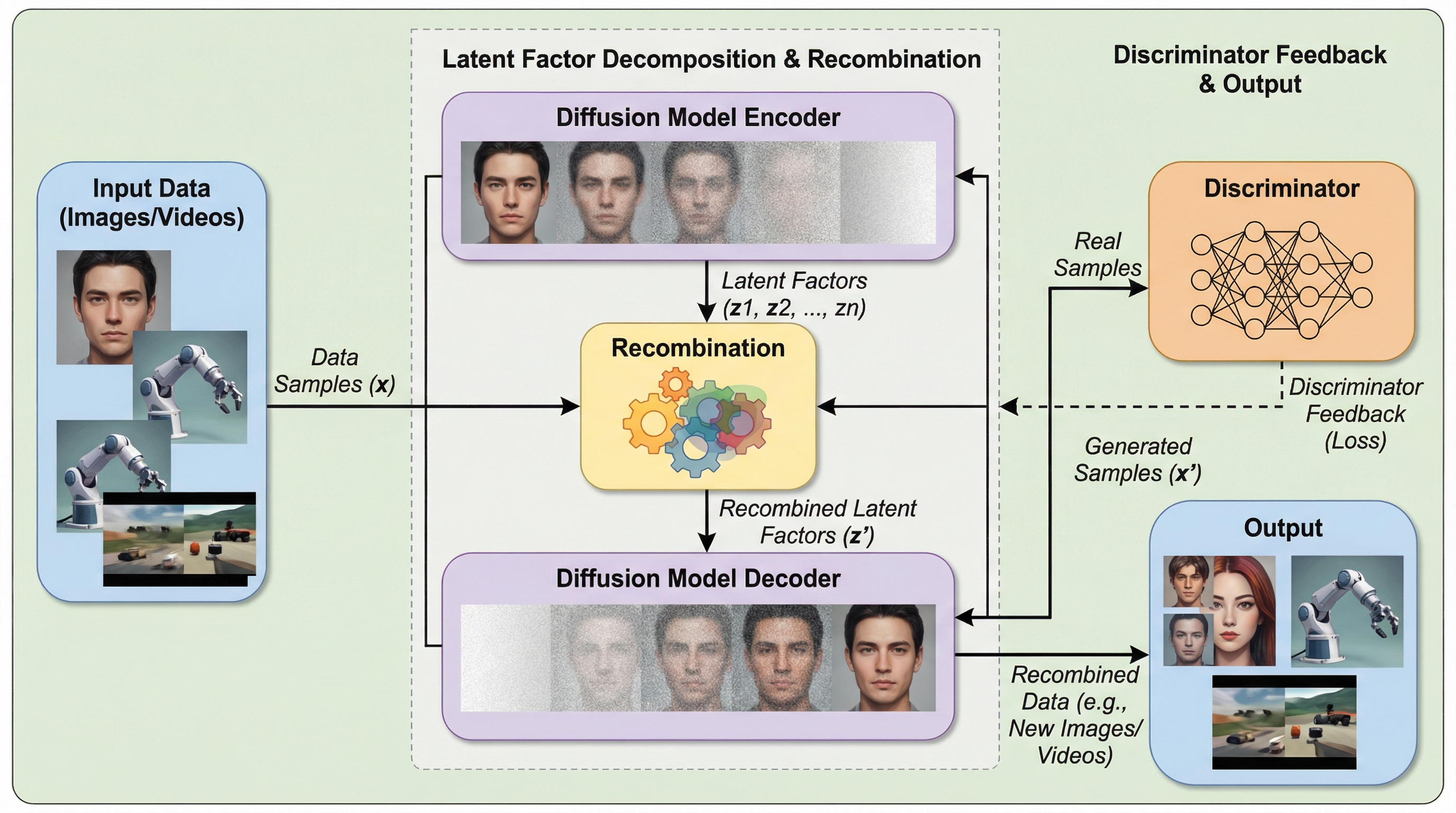
複雑なデータを教師なしで背景、照明、物体の属性、あるいはロボットの動作といった独立した構成要素へと分解し、それらを自在に再結合して新たなサンプルを合成する手法を提案する。本研究では拡散モデルを基盤とし、要素レベルの教師信号を一切必要とせずに、再利用可能な構成要素を抽出する能力を持つ因子化された潜在空間の学習を実現している。 学習過程において、単一のデータ源から生成されたサンプルと、複数のデータ源の構成要素を組み合わせて生成されたサンプルを判別する「識別器」を用いた敵対的学習シグナルを導入した。生成器がこの識別器を欺くように最適化されることで、再結合されたデータにおける物理的および意味的な一貫性が強化され、不自然なアーティファクトの抑制と高品質な合成が可能になる。 CelebA-HQ、Virtual KITTI、CLEVR、Falcor3Dといった画像データセットで、従来手法を上回るFIDスコアと高い解離性を達成した。さらに、ロボットのビデオ軌跡における動作要素の再結合という新しい応用を実証し、LIBEROベンチマークにおいて状態空間の探索範囲を大幅に拡大する多様なシーケンスの生成に成功した。
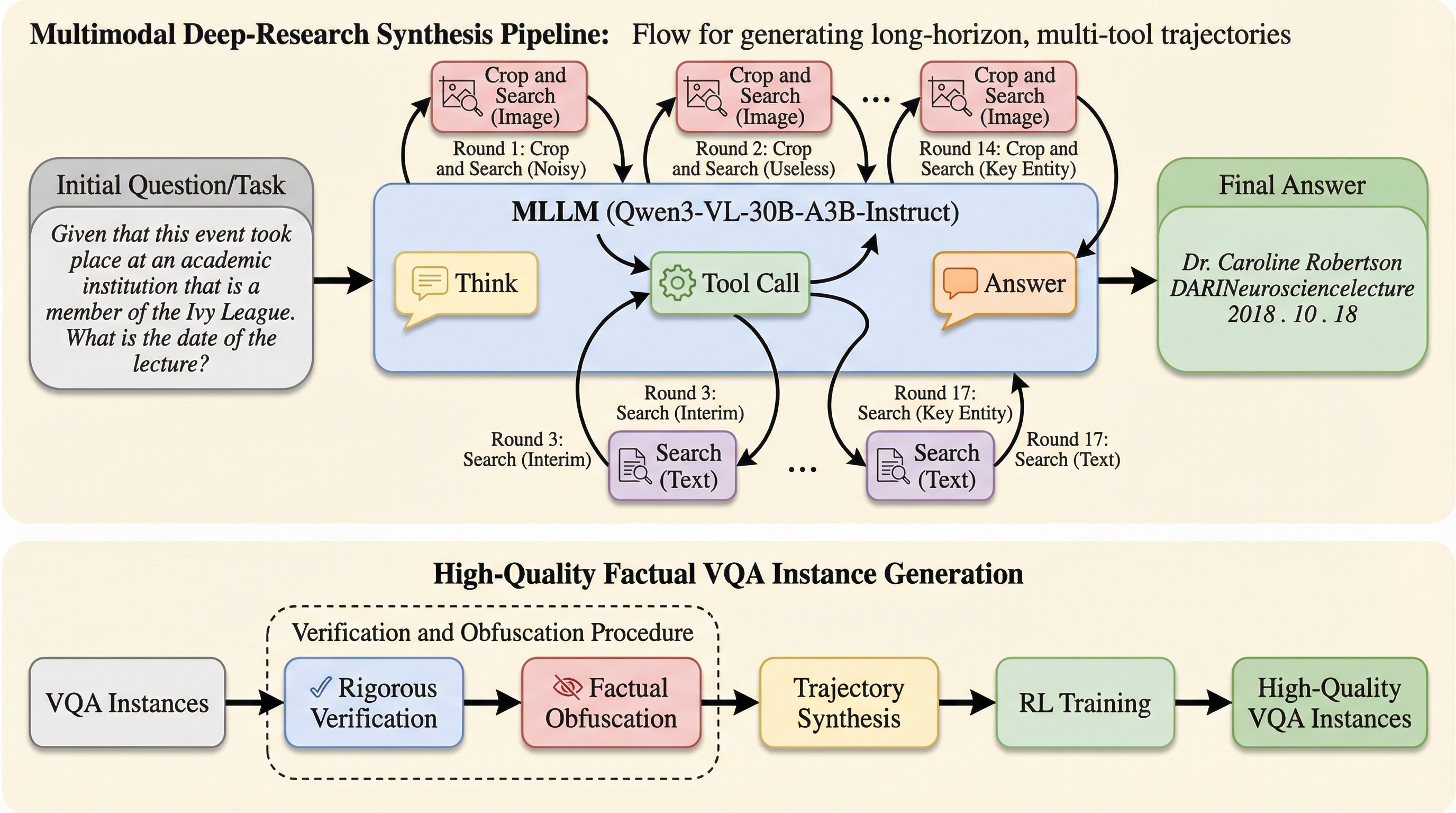
既存のマルチモーダル大規模言語モデル(MLLM)は、外部ツールを用いた検索において、画像全体を一度に検索する単純な手法に頼っており、ノイズの多い現実の環境では必要な情報に辿り着けない「ヒット率」の問題や、推論の深さと検索の幅が不足しているという課題を抱えています。
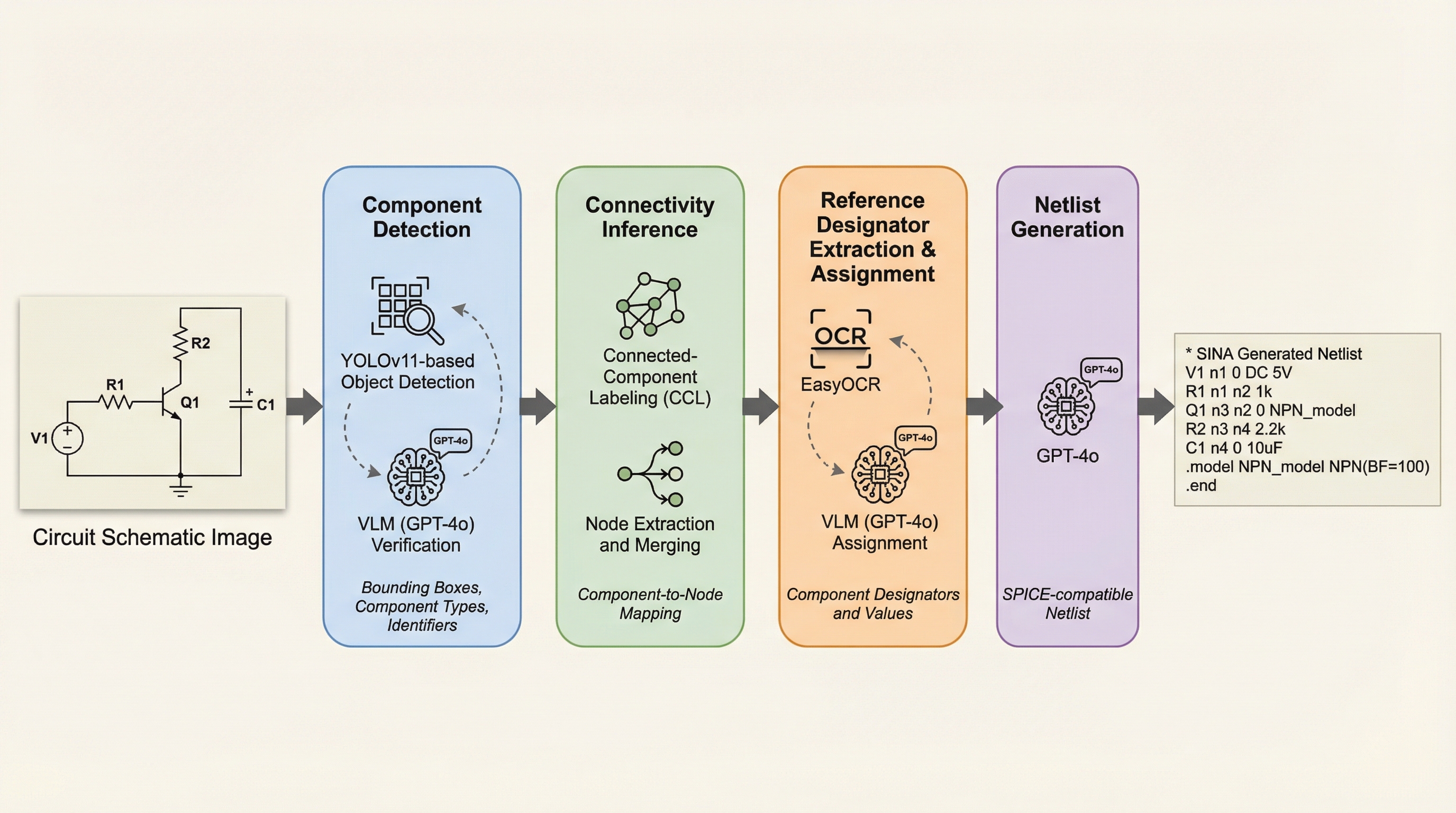
SINAは、回路図の画像からSPICE互換のネットリストを全自動で生成するオープンソースの革新的なパイプラインであり、深層学習と高度な画像処理技術を統合することで、従来の手法が抱えていた素子認識の誤りや複雑な接続推論の困難さといった課題を根本から解決することに成功した。
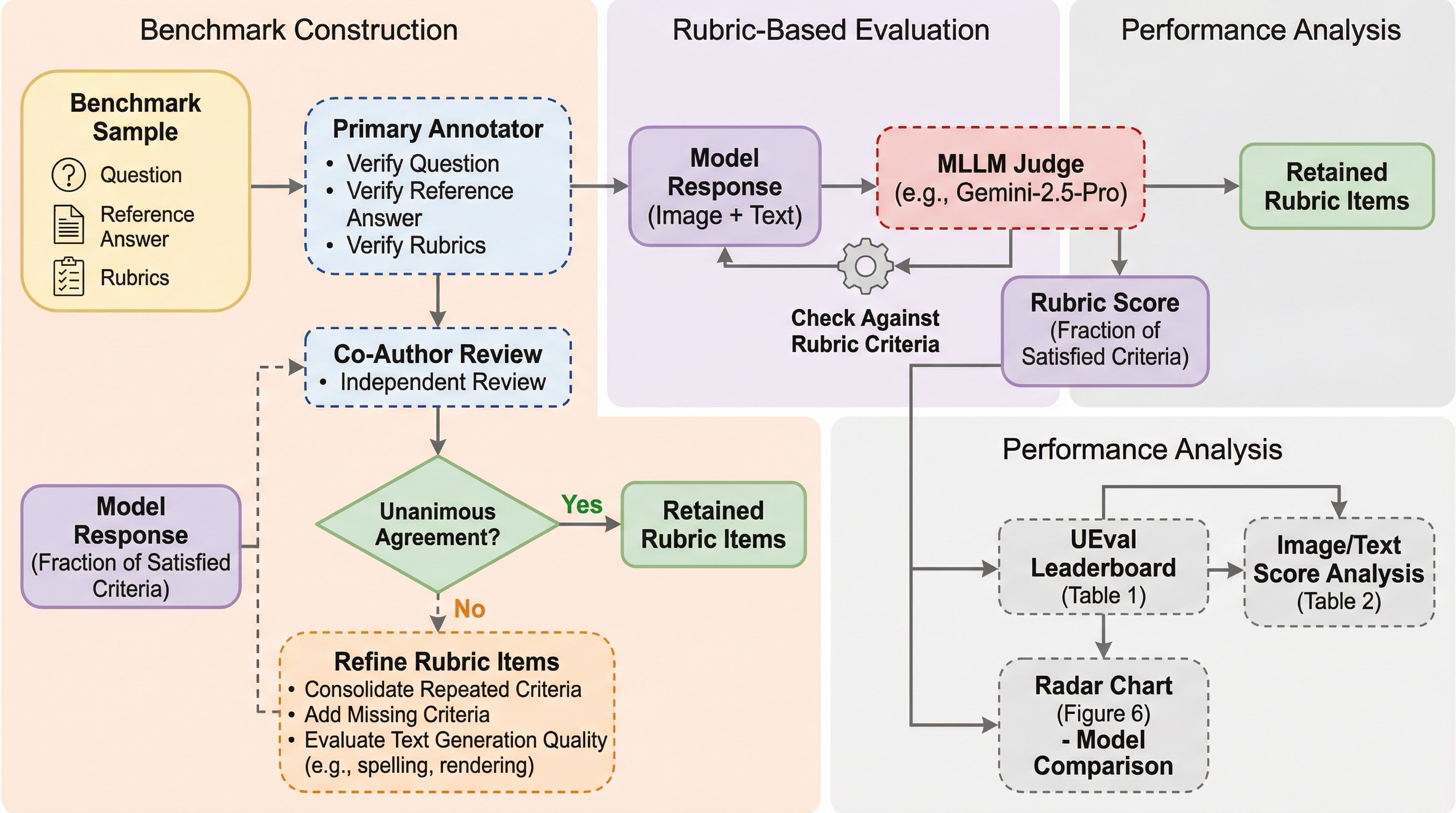
本研究は、テキストの問いかけに対して画像とテキストの両方で回答する「統合マルチモーダル生成」を評価するための新しいベンチマーク「UEval」を提案しました。専門家が厳選した1,000件の質問と、それに対する10,417件の検証済み評価基準(ルーブリック)を用いることで、従来の画像理解や画像生成のみの評価では捉えきれなかった、複雑な推論を伴うマルチモーダルな応答能力を詳細に測定することが可能になります。検証の結果、最新のGPT-5-Thinkingでも100点満点中66.4点に留まり、オープンソースモデルの最高値は49.1点であるなど、現在の統合モデルにとって非常に難易度が高い課題であることが明らかになるとともに、推論プロセスが生成品質の向上に寄与することが示されました。