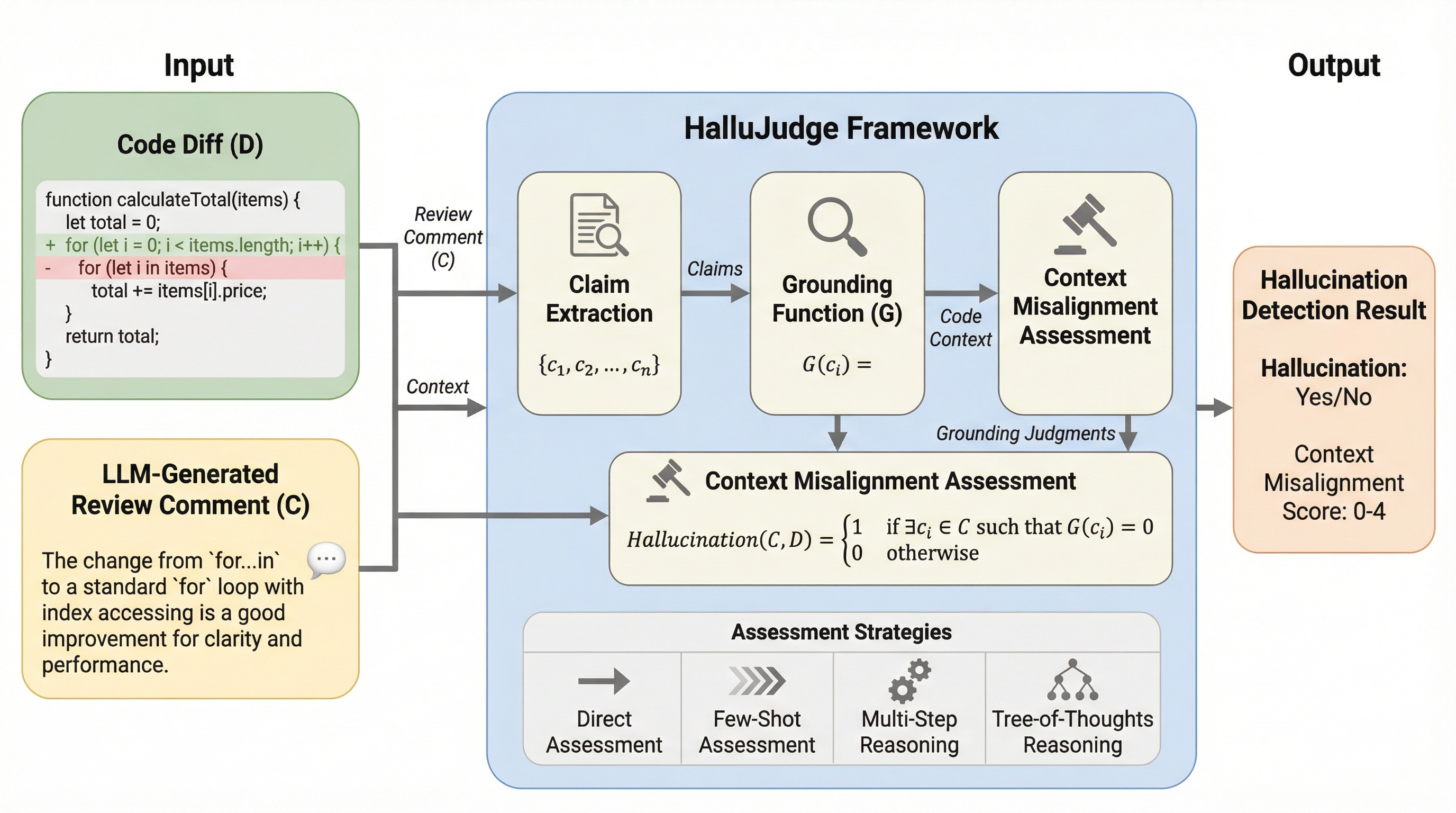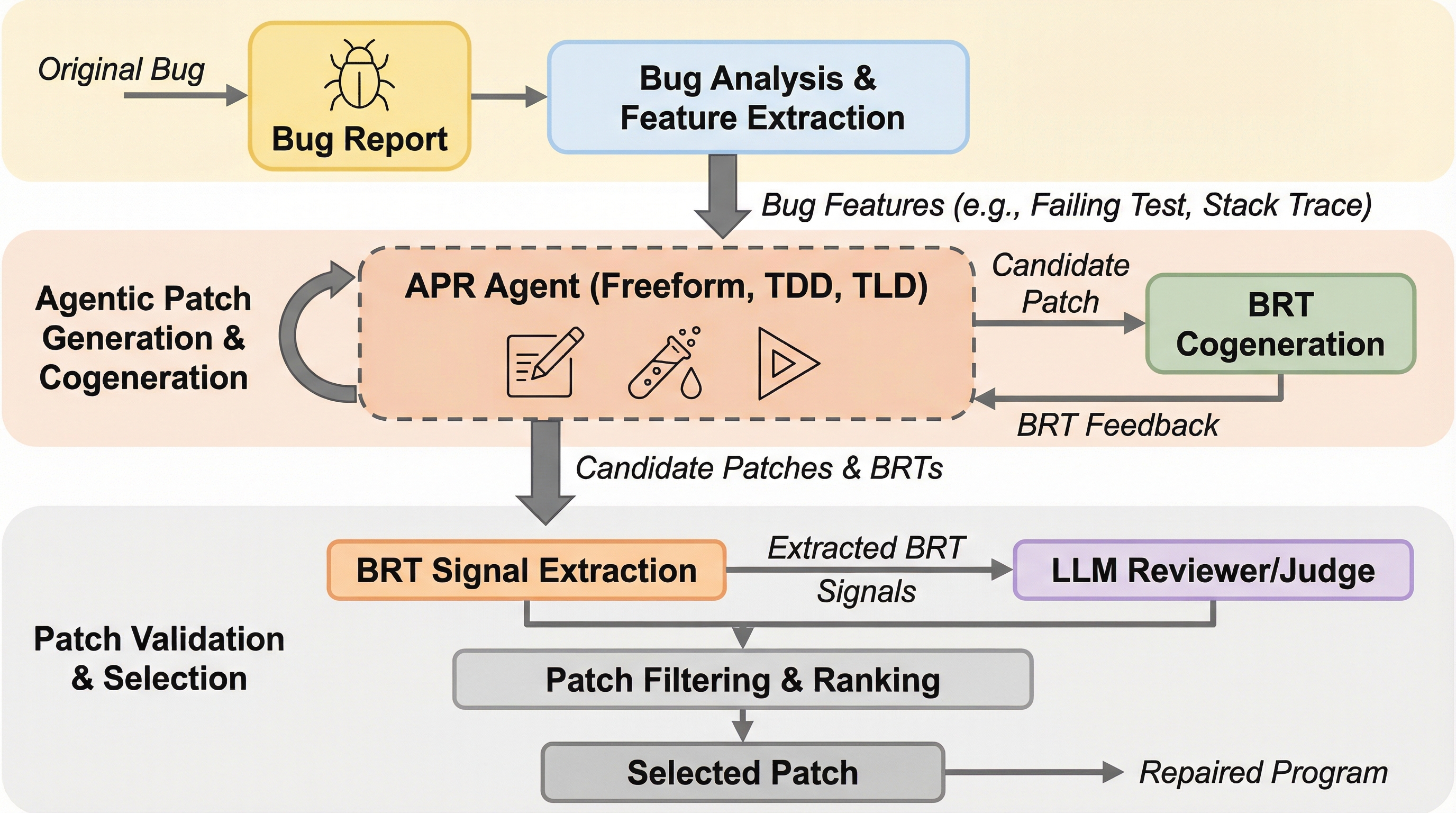
エージェント型プログラム修正におけるバグ再現テストの動的共生成
開発者の信頼を高めるため、AIによるバグ修正と同時にそのバグを再現するテスト(BRT)を生成する「共生成」手法を提案し、Googleの120件の実際のバグを用いてその有効性を検証した。 テスト駆動型(TDD)、テスト後置型(TLD)、自由形式(Freeform)の3つの戦略を比較した結果、自由形式が最も高い成功率を記録し、修正のみやテストのみを生成する専用エージェントと同等以上の成果を上げた。 テストの有無を考慮した新しいパッチ選択手法を導入することで、修正とテストの両方が含まれる高品質なパッチを精度よく特定できることを示し、大規模なソフトウェア開発におけるAIエージェントの有用性を実証した。