強化学習を通じた関数呼び出しモデルの弱点探索:敵対的データ拡張によるアプローチ
大規模言語モデル(LLM)の関数呼び出し能力を向上させるため、強化学習を用いてモデルの弱点を能動的に探索し、敵対的なクエリを生成する新しいデータ拡張フレームワークを提案しました。 この手法は、クエリを生成する「クエリモデル」と、それに応答する「関数呼び出しモデル」を零和ゲームの枠組みで交互に反復学習させることで、従来の固定的なデータセットでは到達できなかった複雑な失敗パターンを体系的に特定します。 検証の結果、提案手法はモデルの堅牢性と汎用性を大幅に向上させ、外部ツールやAPIとの対話において、より正確で信頼性の高い構造化データの出力を可能にすることが確認されました。
TL;DR(結論)
大規模言語モデル(LLM)の関数呼び出し能力を向上させるため、強化学習を用いてモデルの弱点を能動的に探索し、敵対的なクエリを生成する新しいデータ拡張フレームワークを提案しました。 この手法は、クエリを生成する「クエリモデル」と、それに応答する「関数呼び出しモデル」を零和ゲームの枠組みで交互に反復学習させることで、従来の固定的なデータセットでは到達できなかった複雑な失敗パターンを体系的に特定します。 検証の結果、提案手法はモデルの堅牢性と汎用性を大幅に向上させ、外部ツールやAPIとの対話において、より正確で信頼性の高い構造化データの出力を可能にすることが確認されました。
なぜこの問題か
現代の大規模言語モデル(LLM)において、外部ツールやAPIと連携するための関数呼び出し能力は、実用性を左右する極めて重要な機能となっています。GPT-4、Gemini、Qwenといったモデルは、ユーザーの要求を解釈し、適切なツールを選択して、その実行に必要なパラメータをJSONなどの構造化された形式で生成する能力を備えています。このプロセスは、情報の検索、アプリケーションの制御、ユーザーに代わって複雑な操作を実行するための基盤となります。しかし、この能力をさらに強化するための従来のトレーニング手法には、データの質と多様性に関する根本的な限界が存在していました。 現在、関数呼び出しモデルの学習には、人間による手動のアノテーションや、LLMを用いた自動生成データが主に使われています。しかし、手動でのデータ作成は多大な時間と労力を要するためスケールが難しく、生成されるパターンも限定的になりやすいという欠点があります。一方で、LLMによる自動生成データは特定の分布に固執する傾向があり、モデルが本来苦手とする「弱点」を意図的に狙い撃ちするような設計がなされていません。…
核心:何を提案したのか
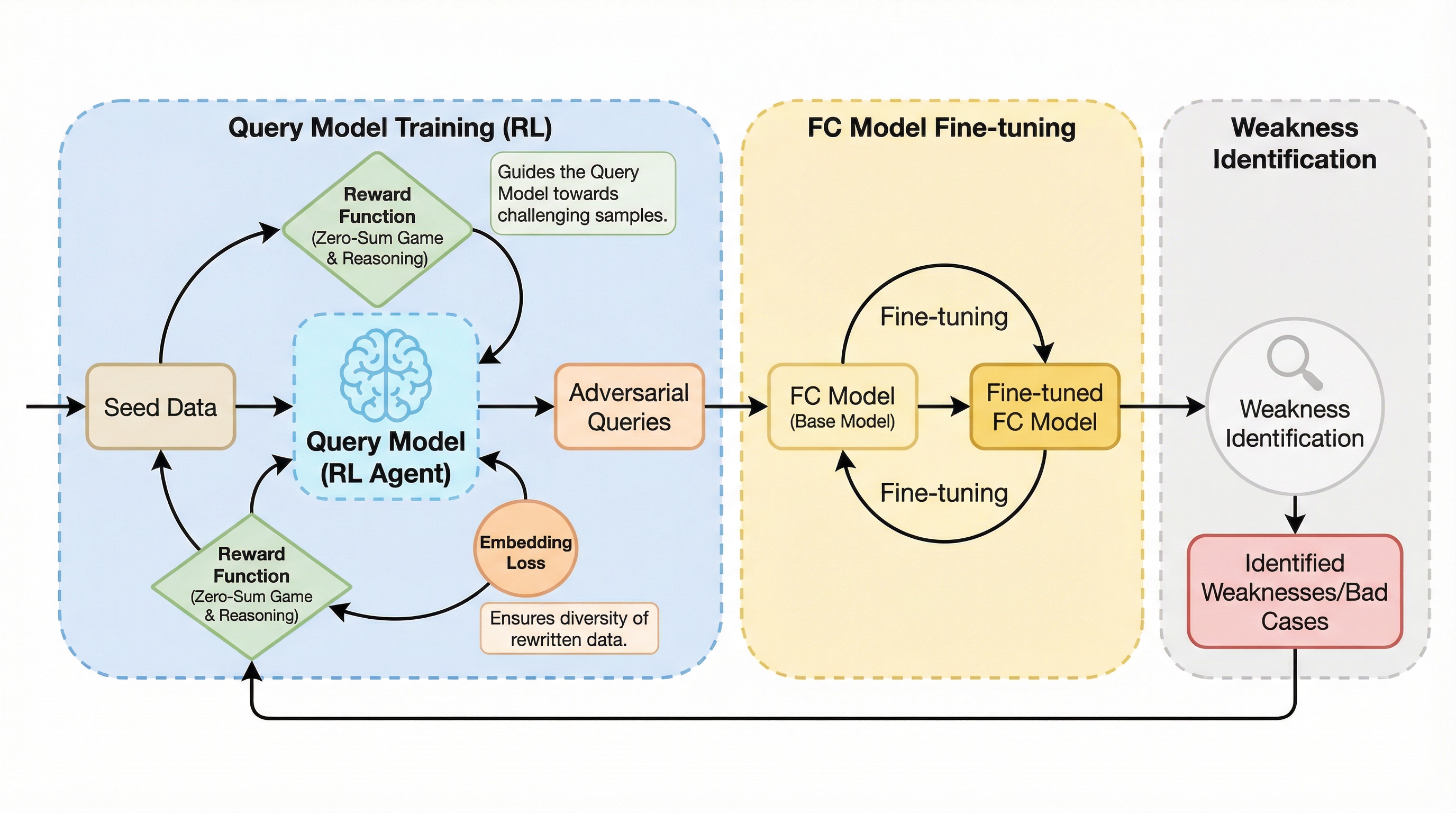
本研究の核心は、強化学習(RL)を活用して関数呼び出しモデルの弱点を能動的に探索し、標的を絞ったデータ拡張を行う新しいトレーニングフレームワークを提案した点にあります。具体的には、既存のシードデータを書き換えて、関数呼び出しモデルが誤答しやすい「敵対的クエリ」を生成する「クエリモデル」を構築しました。このアプローチは、一方の利益が他方の損失となる「零和ゲーム」の理論に基づいています。クエリモデルは、関数呼び出しモデルを攻撃する側として機能し、関数呼び出しモデルはそれに対処する防御側として機能します。 この両者を交互に反復して学習させることで、モデルは自身の弱点を継続的に発見し、それを克服し続けることができます。クエリをゼロから生成するのではなく、既存のデータを書き換える手法を採用した理由として、プロンプトの多様性を維持できること、正解ラベルを利用して学習をガイドできること、そしてデータ分布の制御が容易であることが挙げられます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related