CLIPガイドによる教師なし意味論的露出補正
不適切な露出による詳細の消失や色被りを解決するため、Fast Segment Anything Modelから得られる物体レベルの意味情報を活用し、領域ごとの精密な補正を行う新しい教師なし学習フレームワークが提案されました。
TL;DR(結論)
不適切な露出による詳細の消失や色被りを解決するため、Fast Segment Anything Modelから得られる物体レベルの意味情報を活用し、領域ごとの精密な補正を行う新しい教師なし学習フレームワークが提案されました。 CLIPを用いて露出状態を自動判別し、画像ごとに最適化された擬似的な正解画像を生成することで、膨大な手間を要する手動でのラベル付けを不要にしながら、混合照明シーンにおいても構造の完全性と自然な色彩を維持する高精度な露出補正を実現しています。 長距離の空間的依存関係を効率的に捉えるMambaベースのネットワーク構造と、意味論的な一貫性を強制する新しい損失関数を導入した結果、既存の教師なし手法を数値的および視覚的な両面で大きく上回る性能が確認されました。
なぜこの問題か
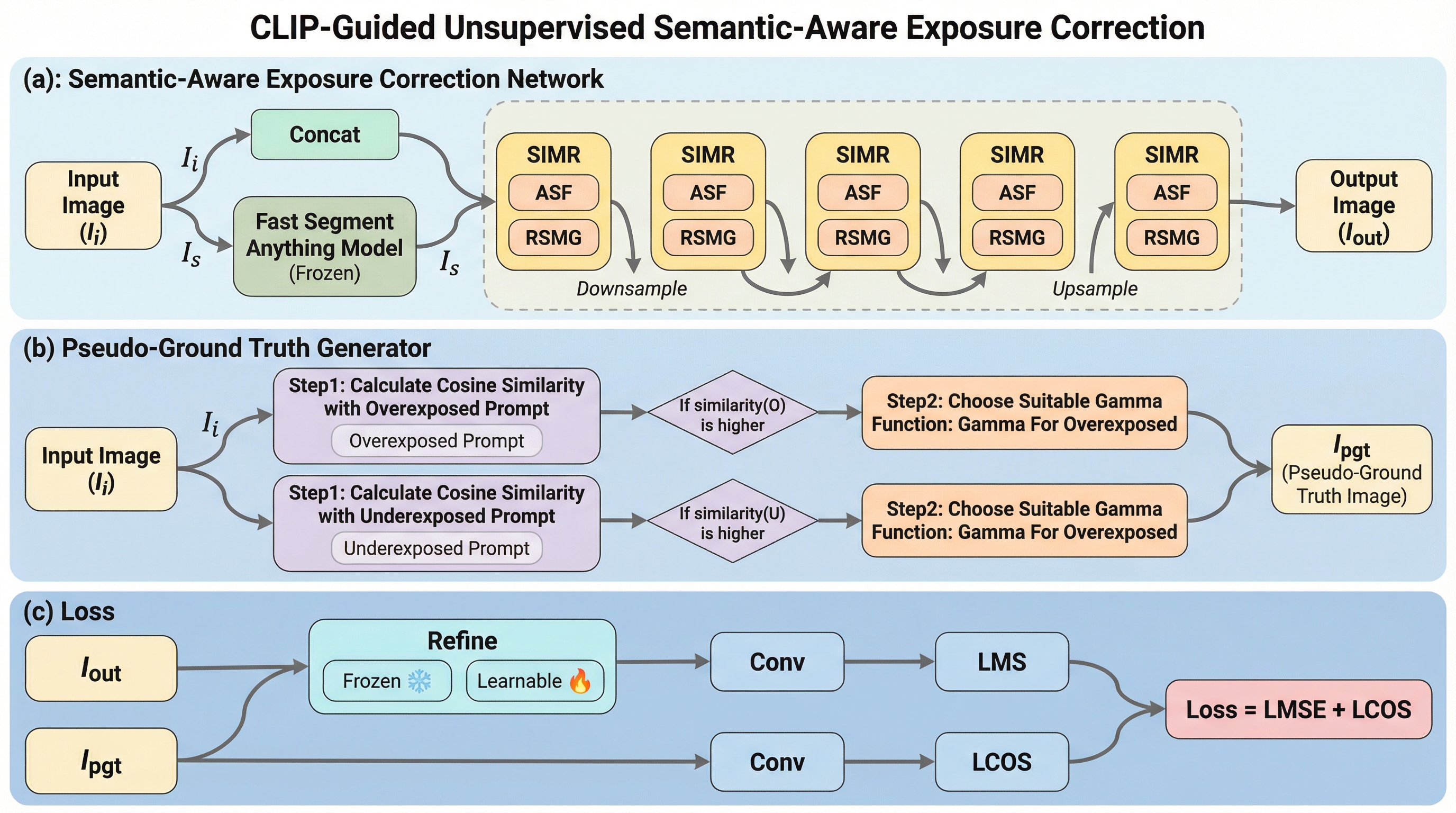
現実世界の写真撮影において、照明環境の多様性やカメラの露出設定の不備は、画像の品質を著しく低下させる主要な要因となります。具体的には、絞りやシャッタースピード、ISO感度の設定が不適切であると、露出不足による黒潰れや露出過多による白飛びが発生し、重要な細部が失われるだけでなく、色の歪みやコントラストの低下を招きます。これまで多くのディープラーニング手法が提案されてきましたが、依然として解決すべき二つの決定的な課題が残されています。第一の課題は、既存手法の多くが画像全体を一律に調整したり、大まかなバイナリマスクを使用したりしている点です。このようなアプローチでは、画像内の個々の物体が持つ領域的な意味情報が無視されるため、意味論的な一貫性が損なわれ、構造的な忠実度が低下し、結果として不自然な色移りが発生しやすくなります。特に、一つの画面内に極端に明るい部分と暗い部分が混在する混合照明シーンでは、局所的な露出の差異を正確に捉えて補正することが極めて困難です。第二の課題は、学習データの確保に関する深刻な問題です。多くの高性能な手法は教師あり学習に依存しており、専門家が手動で編集した高品質なターゲット画像を必要とします。…
核心:何を提案したのか
本研究では、上述の課題を抜本的に解決するために、CLIP(Contrastive Language-Image Pre-training)とFast Segment Anything Model(FastSAM)の知見を統合した「教師なし意味論的露出補正ネットワーク」を提案しています。このフレームワークの核心は、事前学習済みの強力なモデルから得られる豊富な知識を、露出補正という特定のタスクに効果的に組み込んだ点にあります。まず、物体レベルの意味論的プライアを導入するために、FastSAMから抽出された領域情報を活用しています。これにより、画像内の各物体や領域の特性に応じた、きめ細やかな露出調整が可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related