RobustExplain:推薦のためのLLMベース説明エージェントの堅牢性評価
大規模言語モデル(LLM)を推薦理由の説明に活用する際、誤クリックやデータの欠損といった現実的なノイズが説明の整合性に与える影響を評価する初のフレームワーク「RobustExplain」が開発されました。 5種類の行動ノイズと4つの評価指標を用いて実験した結果、現在のLLMの堅牢性は平均0.
TL;DR(結論)
大規模言語モデル(LLM)を推薦理由の説明に活用する際、誤クリックやデータの欠損といった現実的なノイズが説明の整合性に与える影響を評価する初のフレームワーク「RobustExplain」が開発されました。 5種類の行動ノイズと4つの評価指標を用いて実験した結果、現在のLLMの堅牢性は平均0.50程度の中程度に留まり、特に説明の構造やキーワードの維持において入力の変化に敏感であることが明らかになりました。 モデルの規模が大きくなるほど堅牢性が向上する傾向(最大8%の改善)が確認されましたが、実用化にはノイズに対する安定性を重視した設計と評価が不可欠であり、本研究はそのための重要な基準値を提示しています。
なぜこの問題か
現代の推薦システムにおいて、大規模言語モデル(LLM)はユーザーの行動履歴に基づいた自然言語による説明を生成する「説明エージェント」として急速に普及しています。従来のテンプレート形式や特徴量ベースの説明と比較して、LLMが生成する説明は流暢さ、パーソナライズ、文脈の理解において優れており、人間のような対話形式で推薦の根拠を提示することが可能です。これにより、システムの透明性が高まり、ユーザーの信頼を獲得することが期待されています。しかし、これまでの研究の多くは、入力データがクリーンで固定されていることを前提とした、説明の流暢さや関連性、ユーザーの満足度といった「生成の質」に焦点を当ててきました。 現実世界のウェブプラットフォームにおけるユーザーの行動データは、本質的にノイズを含んでいます。例えば、意図しない誤クリック、データの記録遅延による時間的な不整合、メタデータの欠落、家族などによるアカウントの共有、そして時間の経過とともに変化するユーザーの好みなどが挙げられます。…
核心:何を提案したのか
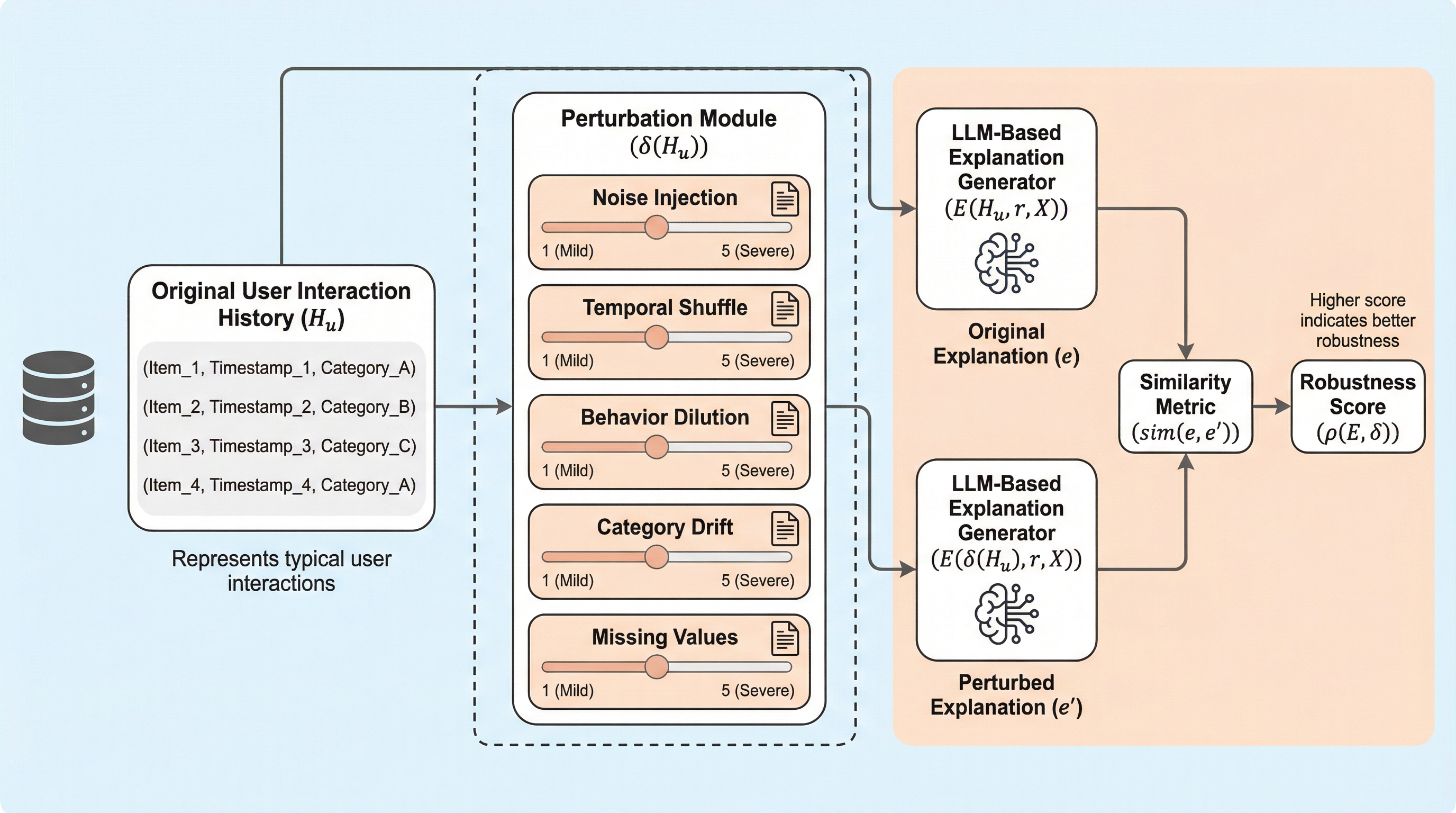
本論文では、推薦システムにおけるLLMベースの説明エージェントの堅牢性を測定するための、世界初の体系的な評価フレームワーク「RobustExplain」を提案しています。このフレームワークの核心は、現実の運用環境で発生し得るユーザー行動の乱れを模倣し、それに対して説明の内容がどれだけ変化するかを多角的に分析することにあります。RobustExplainは、単なるテキストの一致度を測るものではなく、推薦システム特有のデータの性質を考慮した設計となっています。 RobustExplainは、主に3つの要素で構成されています。第一に、現実的なノイズシナリオをモデル化した「摂動タクソノミ(分類法)」です。これには、ランダムなクリックを模したノイズの注入や、時間順序の入れ替えなど、実務上の課題を反映した5つのタイプが含まれています。第二に、説明の変容を捉えるための「多次元堅牢性指標」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related