最適輸送理論に基づくサンプル生成による分布外データの過剰適合抑制
深層学習モデルが未知のデータ(分布外データ)に対して根拠のない高い確信度を持つ「過剰適合」の問題に対し、半離散最適輸送理論の幾何学的構造を利用して、意味的に曖昧な境界領域を特定し制御する新しい学習フレームワークが提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
深層学習モデルが未知のデータ(分布外データ)に対して根拠のない高い確信度を持つ「過剰適合」の問題に対し、半離散最適輸送理論の幾何学的構造を利用して、意味的に曖昧な境界領域を特定し制御する新しい学習フレームワークが提案されました。
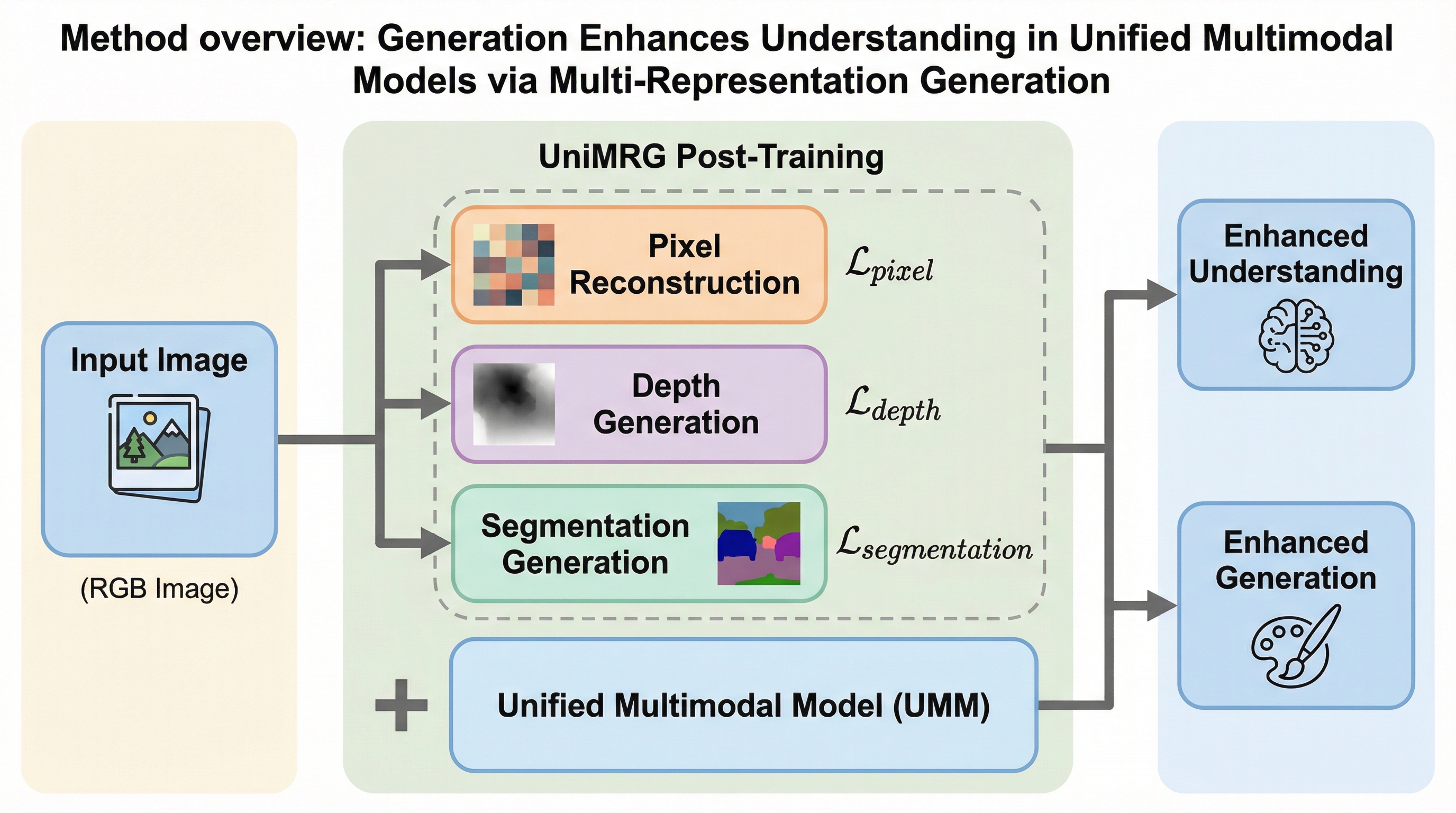
統一マルチモーダルモデル(UMM)において、画像生成タスクを補助的に活用することで視覚的理解能力を飛躍的に向上させる新しい学習手法「UniMRG」が提案されました。 従来のピクセル再構成に加え、幾何学的な奥行き(デプス)や構造的なセグメンテーションといった複数の内部表現を生成させることで、モデルは空間関係や物体の境界をより深く学習します。 実験では、微細な知覚能力の向上やハルシネーションの抑制、空間認識の強化が確認され、理解タスクの精度向上と同時に画像生成の質も高まるという相乗効果が実証されました。
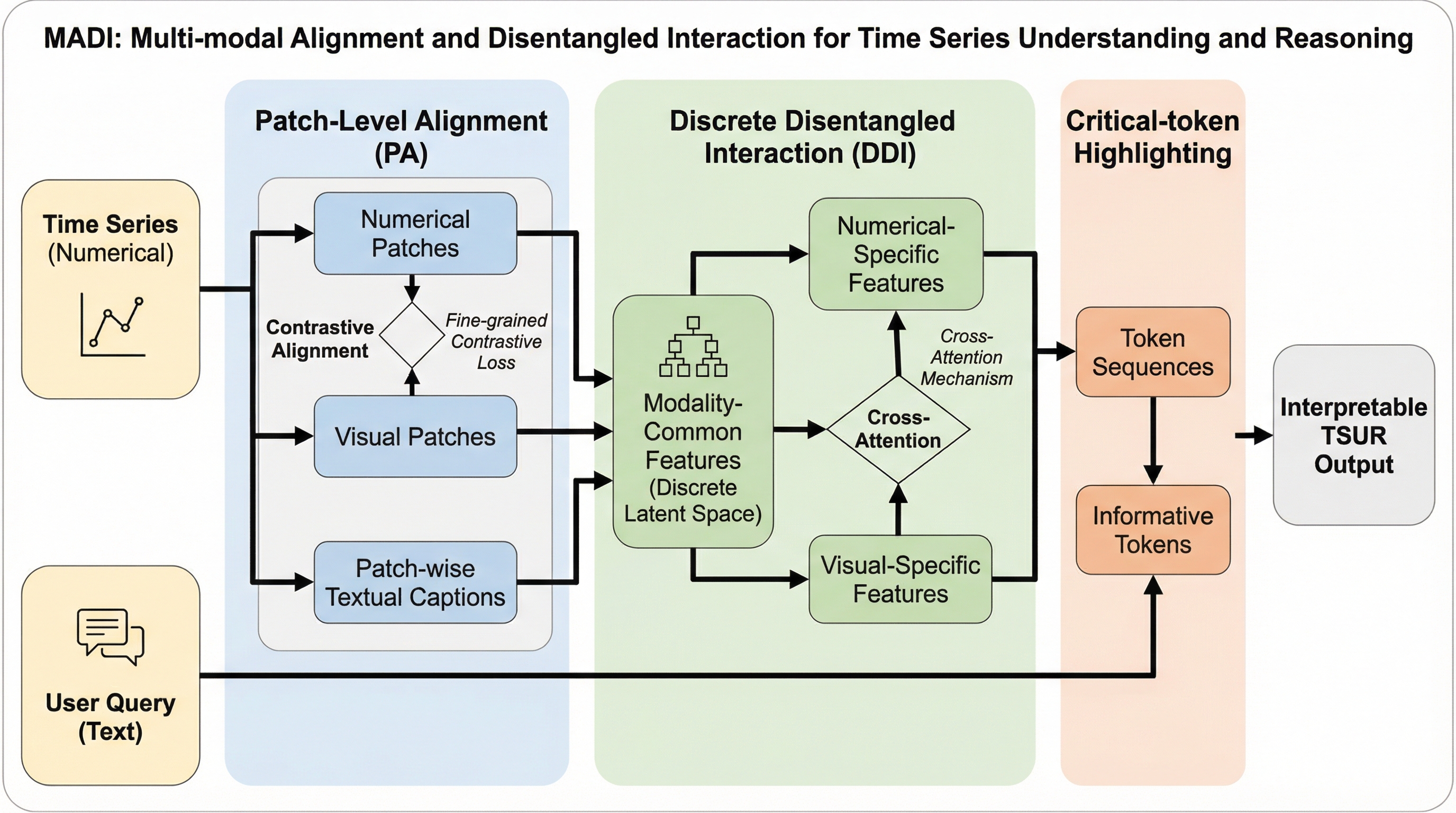
時系列データの数値情報と視覚的なプロット図を統合し、自然言語での問いかけに対して高度な分析や推論を行うマルチモーダル言語モデル「MADI」が提案されました。このモデルは、パッチ単位での精密な位置合わせを行う「Patch-level Alignment」と、情報の重複を排除して各モダリティ固有の強みを引き出す「Discrete Disentangled Interaction」を中核としています。 従来の数値中心の手法が持つ構造把握の弱点と、視覚中心の手法が持つ数値精度の欠如という双方の課題を解決するため、数値、画像、テキストの3つのモダリティを物理的に対応付け、さらに情報の「解きほぐし」を行うことで、数値の正確性と視覚的なトレンド把握の両立を高い次元で実現しています。 合成データおよび実世界のベンチマークを用いた広範な検証において、MADIは汎用的な大規模言語モデルや時系列特化型の既存モデルを一貫して上回る性能を示しました。これにより、医療、金融、産業メンテナンスといった複雑な意思決定が求められる専門的なドメインにおいて、より信頼性の高い対話型解析が可能になります。
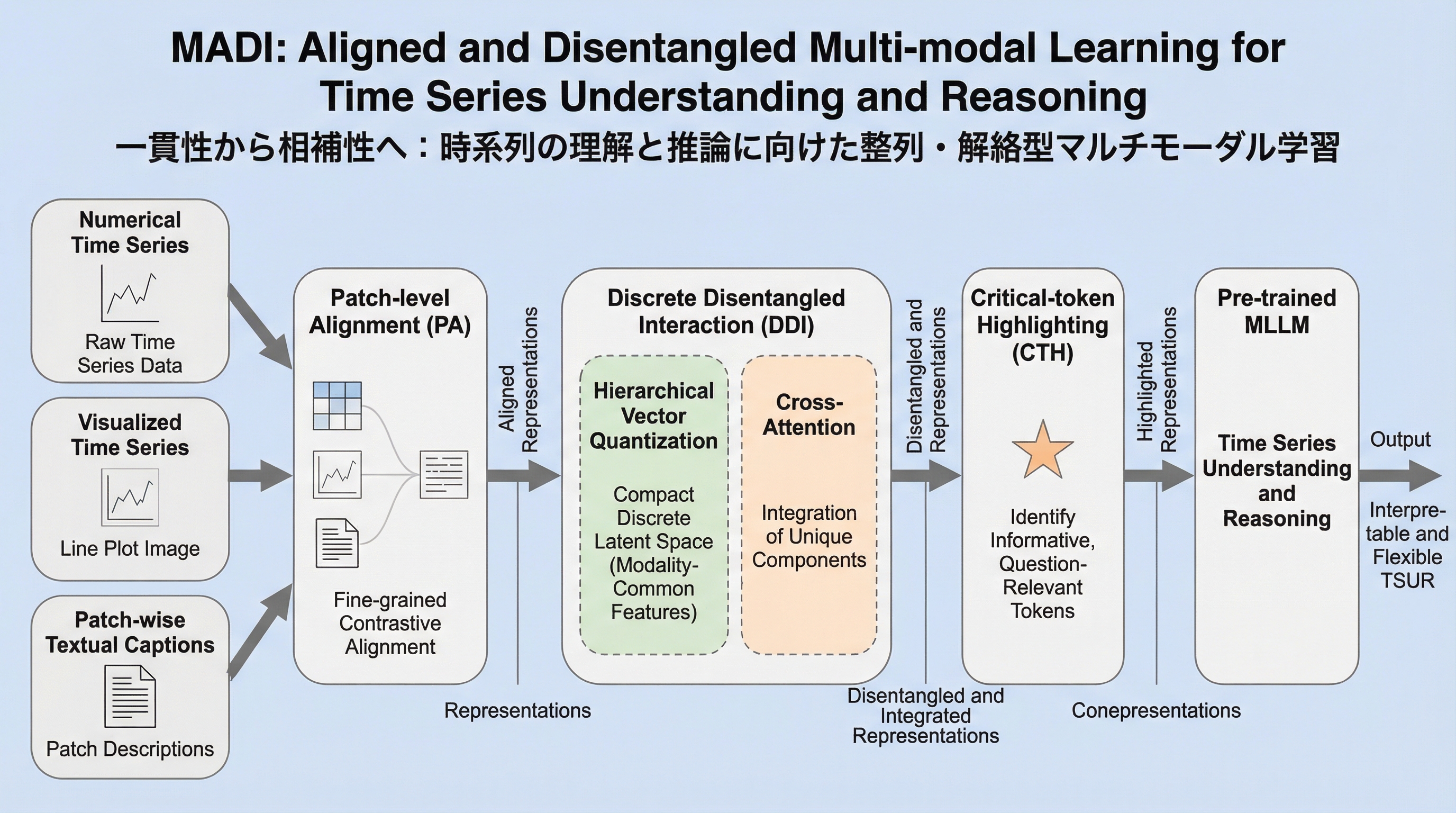
時系列データの数値的な正確性と視覚的な構造把握を両立させるため、パッチ単位での精密な位置合わせを行う「Patch-level Alignment」と、共有情報と固有情報を分離して統合する「Discrete Disentangled Interaction」を備えたマルチモーダル大型言語モデル「MADI」が提案されました。 このモデルは、数値データ、プロット図、統計テキストを物理的に対応付けることで、従来のモデルが抱えていた局所的なハルシネーションを抑制し、トレンドや周期性といった高レベルな特徴と微細な数値変動の両方を正確に捉えることに成功しています。 合成データおよび医療や金融などの現実世界のデータセットを用いた広範な検証の結果、MADIは汎用的な言語モデルや時系列特化型の既存モデルを一貫して上回る性能を示し、複雑な時間的動態に対する柔軟で解釈可能な推論能力を証明しました。
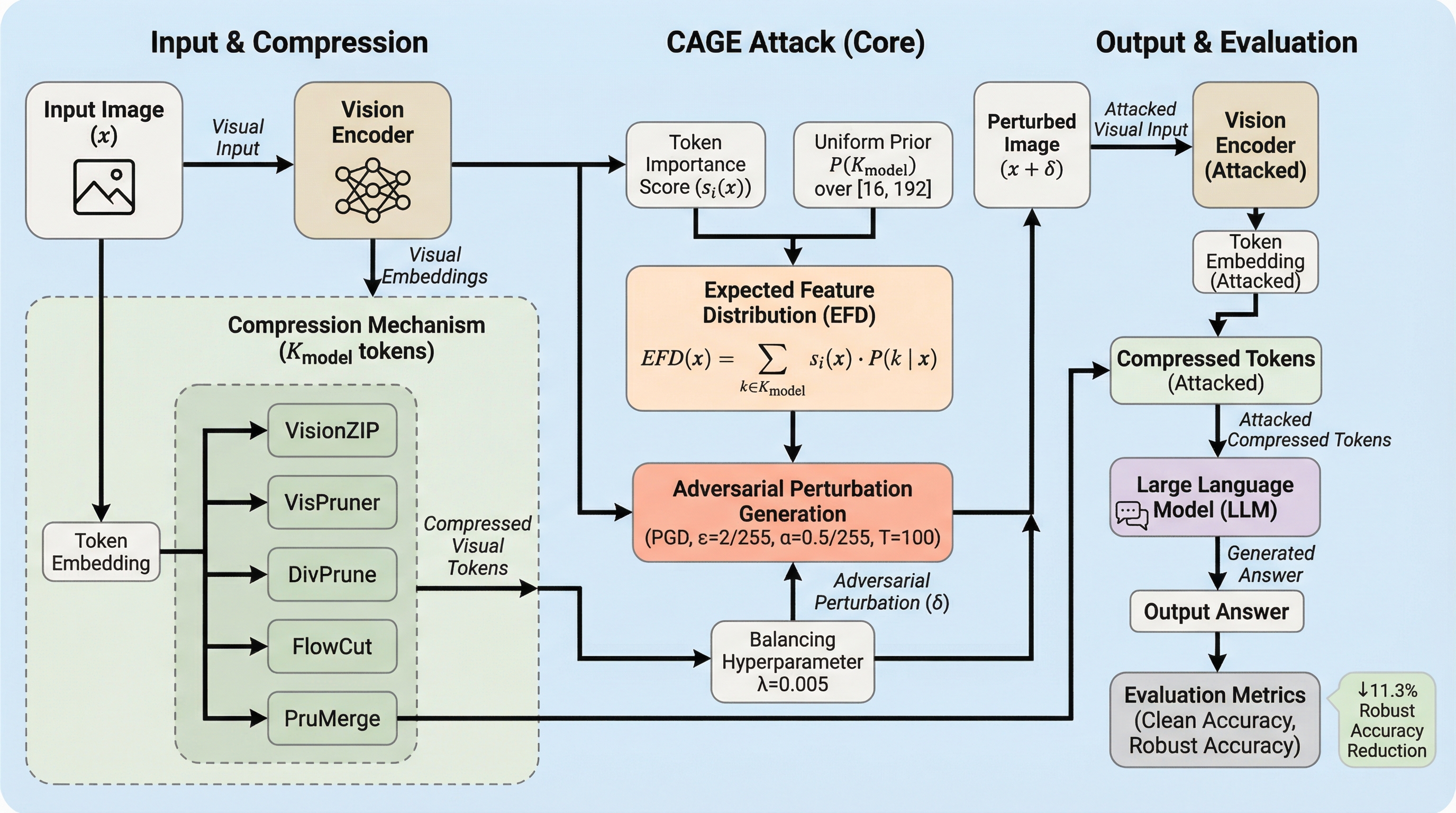
大規模視覚言語モデル(LVLM)の効率化に不可欠な視覚トークン圧縮技術は、敵対的攻撃による歪みを重要なトークンに集中させる「歪み濃縮器」として機能し、既存の評価手法ではモデルの脆弱性を過小評価してしまう問題を明らかにした。
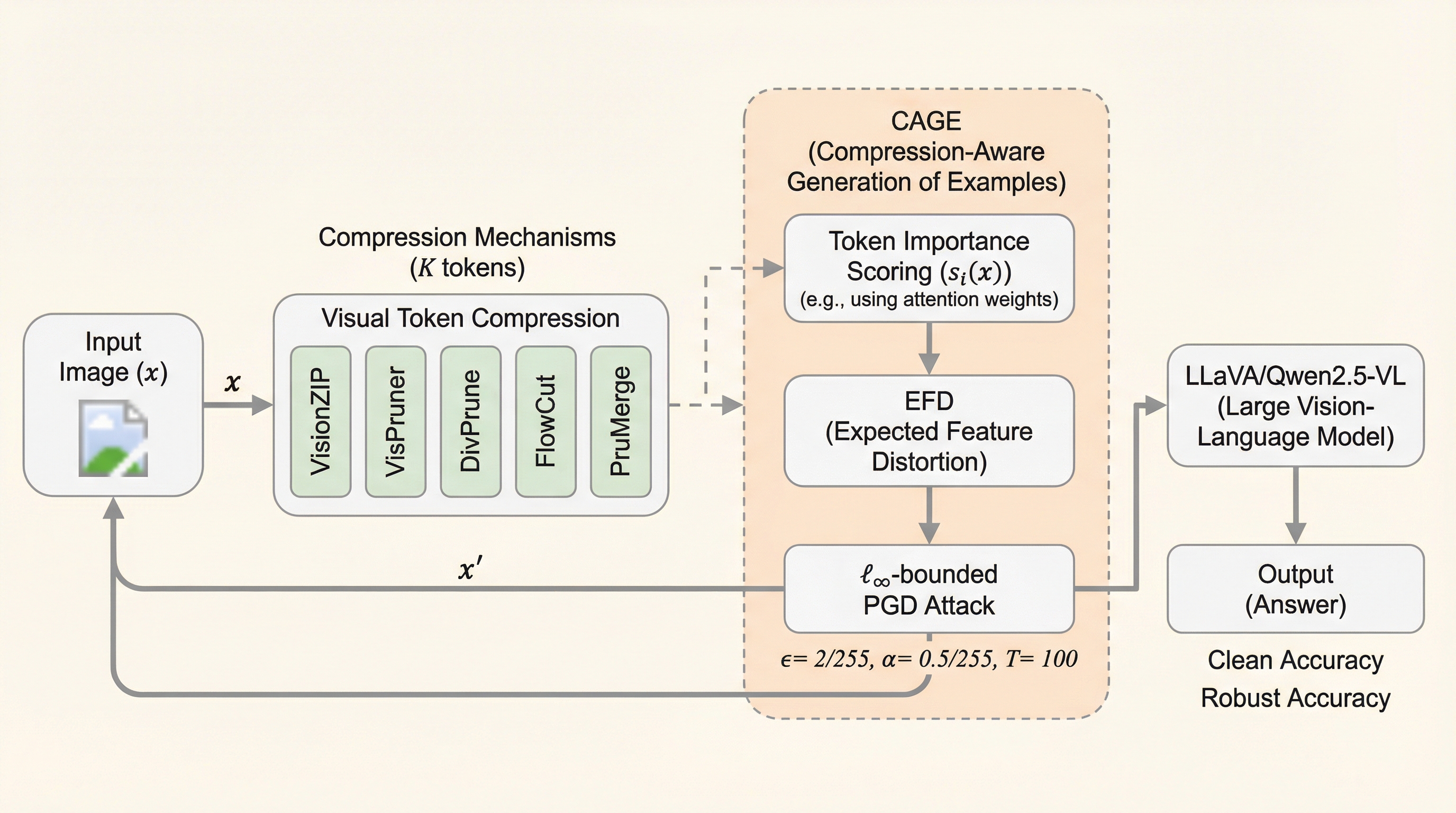
大規模視覚言語モデル(LVLM)の効率化に不可欠な視覚トークン圧縮技術が、敵対的攻撃に対する堅牢性を不当に高く見せかける「最適化と推論の不一致」を引き起こしていることを解明しました。 この問題を解決するため、モデルの圧縮設定が未知の状態でも、生存確率に基づき重要なトークンへ歪みを集中させるEFDと、歪んだトークンを優先的に選択させるRDAを組み合わせた新手法CAGEを提案しました。 検証の結果、圧縮はノイズ除去ではなく「歪みの濃縮器」として機能しており、提案手法は既存の攻撃を大幅に上回る成功率を達成し、効率的なモデルにおける新たなセキュリティ上の脅威を浮き彫りにしました。
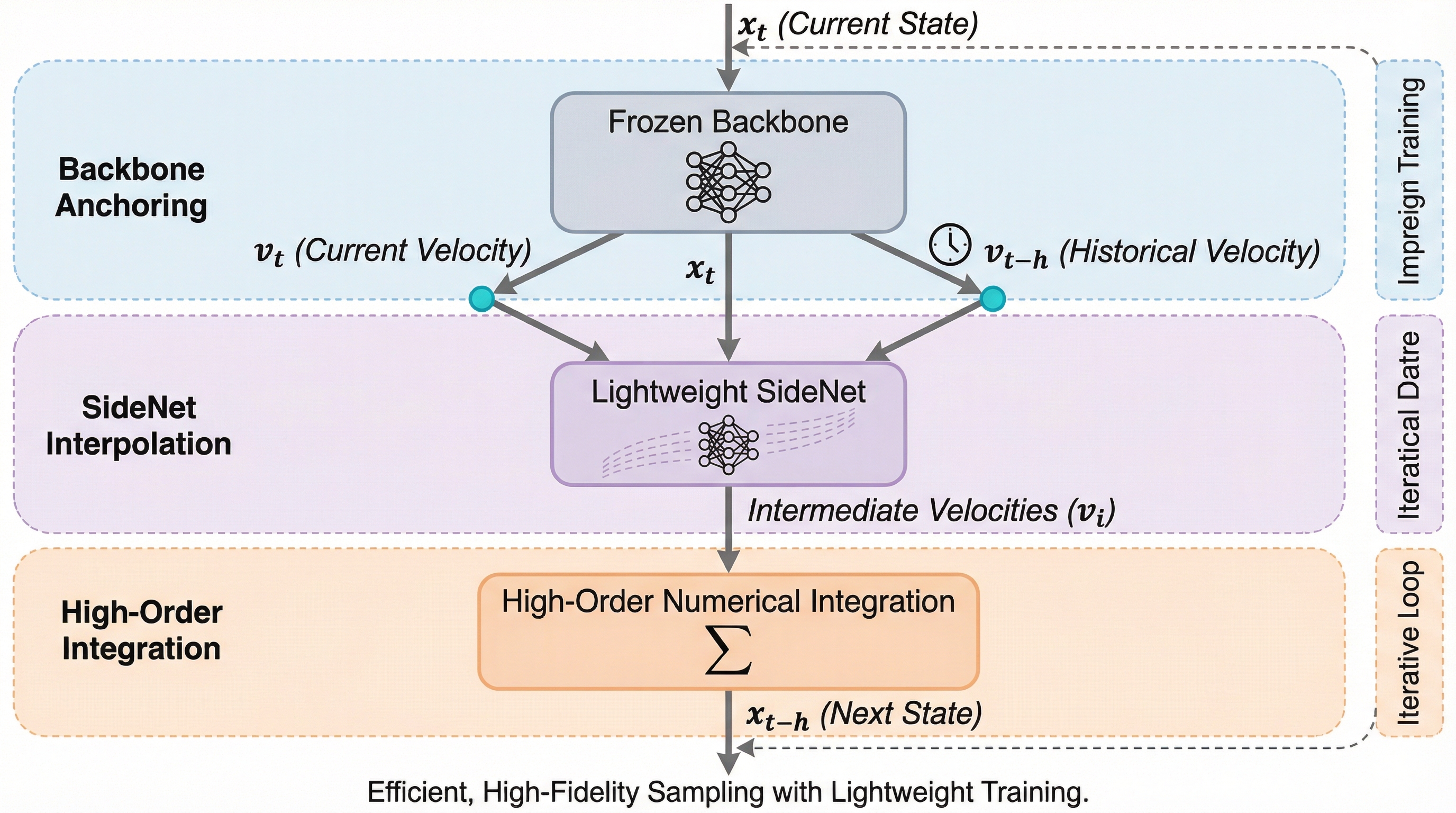
Flow Matching(FM)モデルの生成速度を劇的に向上させるため、巨大なバックボーンを凍結したまま、わずか1〜2%のサイズである軽量なSideNetを追加して高精度な軌道補間を行う「BA-solver」が提案されました。
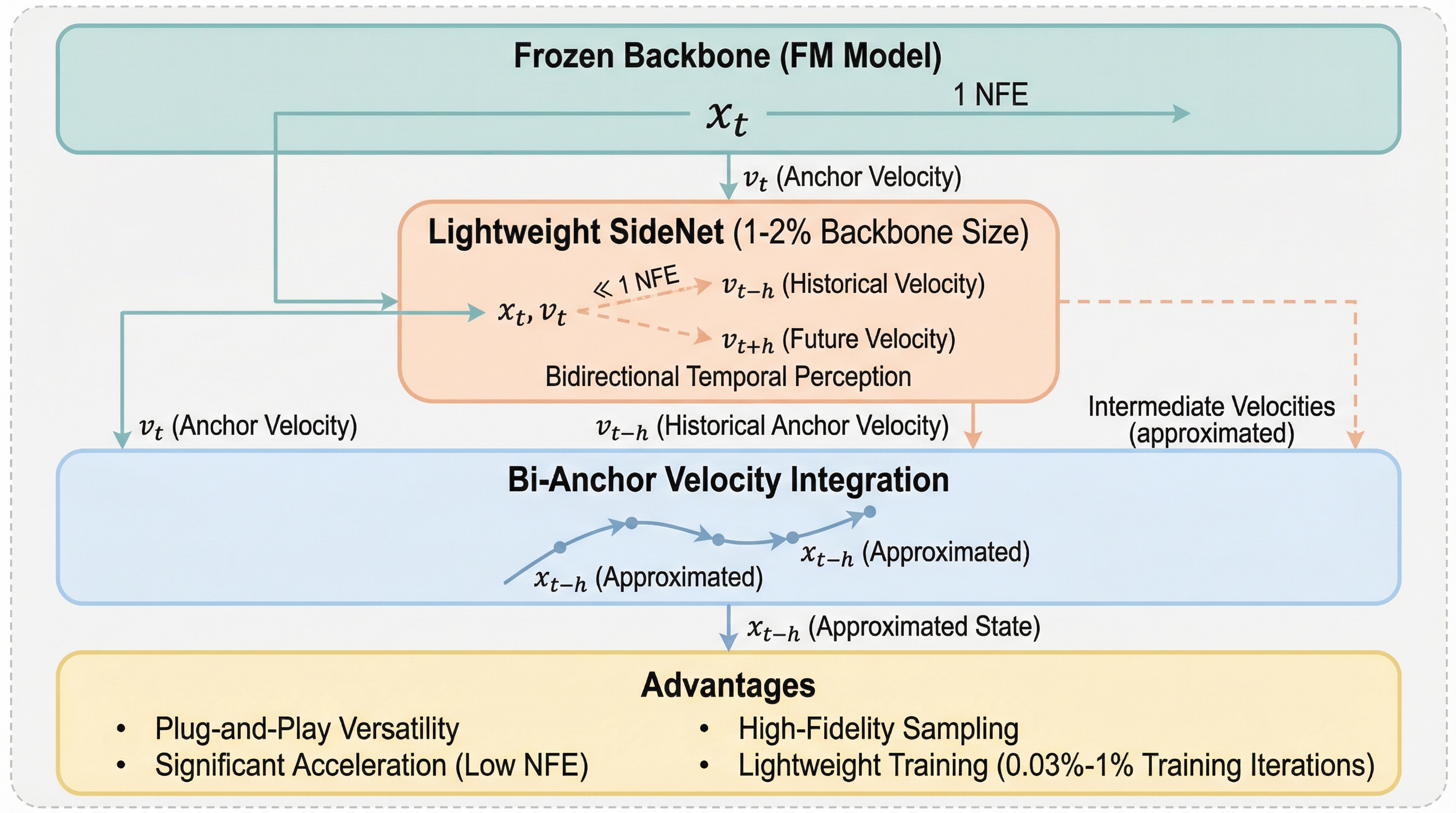
Flow Matching(FM)モデルの生成速度を向上させるため、既存の巨大なバックボーンモデルを凍結したまま、その1〜2%程度の極めて軽量な「SideNet」を追加して双方向の時間を知覚させる「BA-solver」が提案されました。
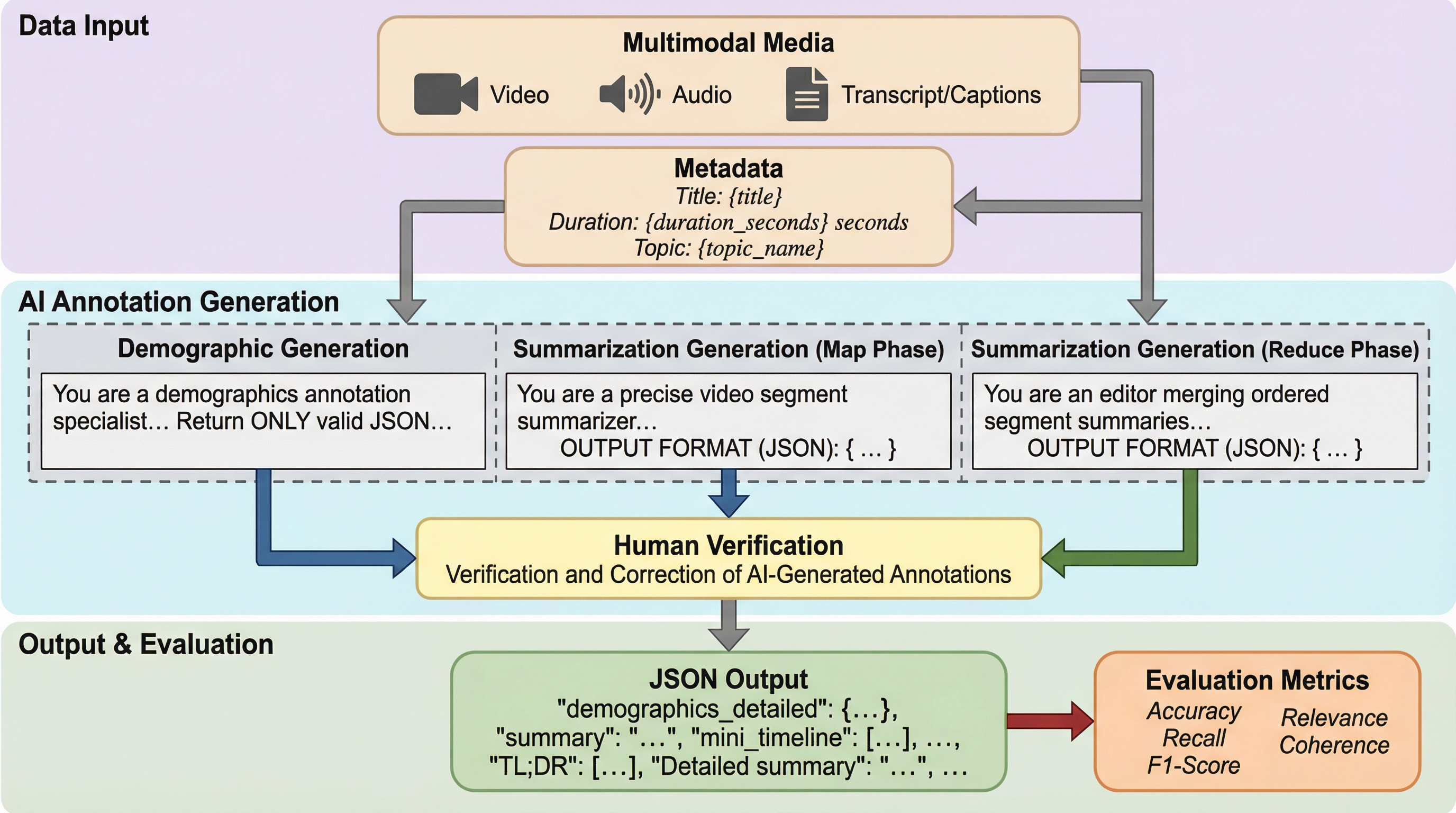
マルチモーダル大規模言語モデル(MLLM)の音声・動画理解能力を評価するため、13の実世界ドメインを網羅した4,958件の高品質な注釈付きデータセット「SONIC-O1」が提案されました。 このベンチマークは、要約、多肢選択問題、時間的ローカライゼーションの3つのタスクを通じて、モデルが音声と映像の両方を統合的に理解できているかを厳密に検証し、特に社会的公平性の観点から人口統計学的なメタデータを付与している点が特徴です。 検証の結果、クローズドソースモデルがオープンソースモデルを圧倒し、特に時間的推論において22.6%もの大きな性能差があることや、人種や性別などの属性によってモデルの精度に偏りが生じることが明らかになりました。
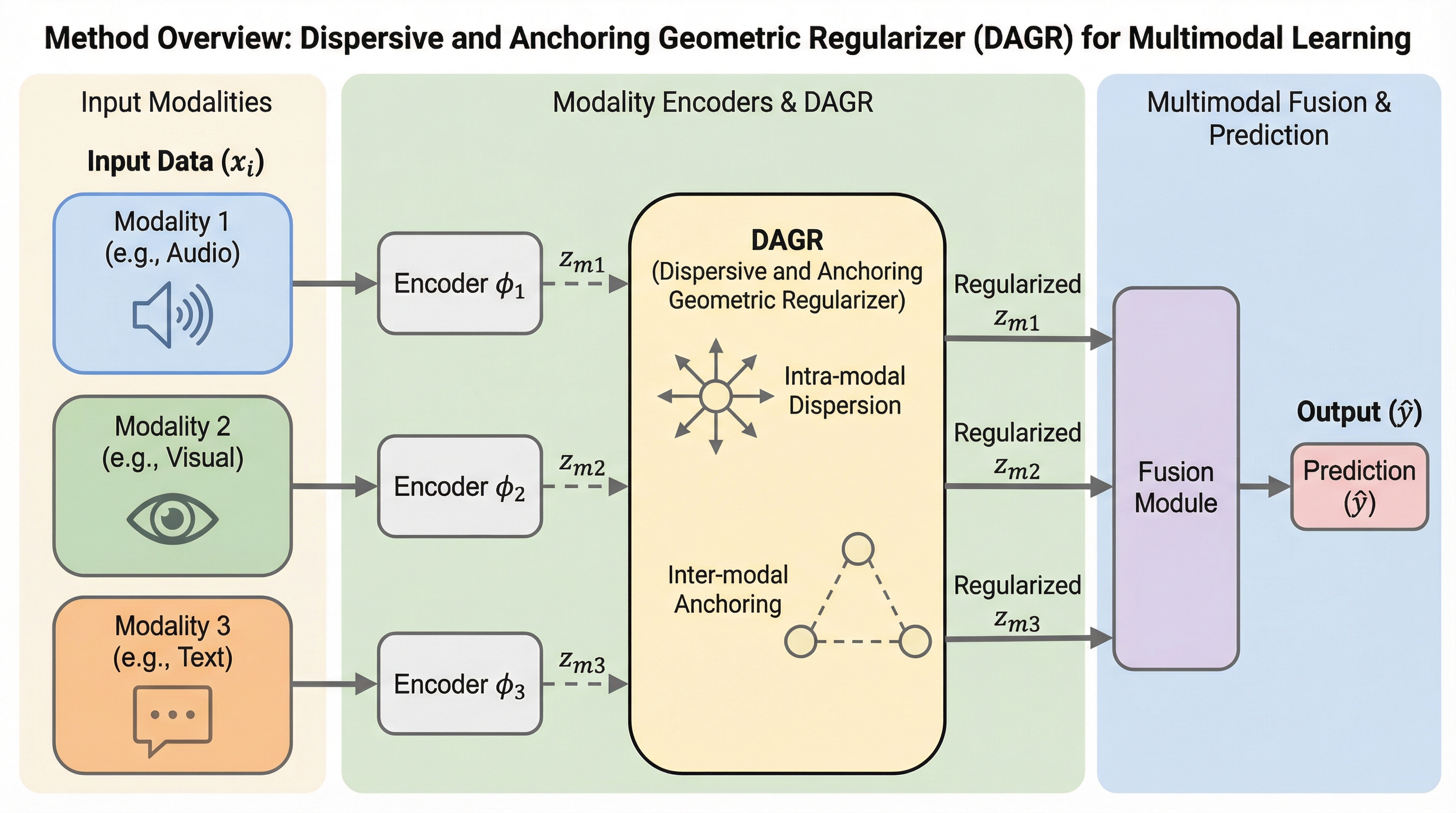
マルチモーダル学習において、強力な勾配最適化を行っても表現空間が特定の領域に固まる「幾何学的崩壊」やモダリティ間の不整合が生じ、特定の情報が他方を抑制するトレードオフが発生することを特定しました。