Whisperのエンコーダとデコーダの両方で視覚特徴量を用いる耐雑音性視聴覚音声認識
本研究は、Whisper ASRの騒音耐性を劇的に向上させるため、視覚的特徴量をエンコーダとデコーダの両方に統合する「デュアルユース」手法を提案し、従来の融合手法が抱えていた学習の不安定さや相互作用の欠如という課題を解決した。
TL;DR(結論)
本研究は、Whisper ASRの騒音耐性を劇的に向上させるため、視覚的特徴量をエンコーダとデコーダの両方に統合する「デュアルユース」手法を提案し、従来の融合手法が抱えていた学習の不安定さや相互作用の欠如という課題を解決した。 騒音環境、特に0dBのバブルノイズ下において、Whisper mediumモデルを用いた場合に57%という極めて高い相対的な精度改善を達成し、LRS3ベンチマークにおいて従来の最先端記録を塗り替える新しい最先端(SOTA)を樹立することに成功した。 1929時間に及ぶ大規模な視聴覚データセットでの学習により、パラメータ数が遥かに多い大規模言語モデルベースの手法を凌駕する性能を示し、実社会の多様な騒音環境下でも視覚情報が聴覚情報を効果的に補完して認識精度を支えることを科学的に実証した。
なぜこの問題か
音声認識技術(ASR)は、深層学習の進展によって静かな環境下では人間と同等以上の精度を達成しているが、現実世界の多様な騒音環境、特に複数の話者が同時に発話する「バブルノイズ」のような状況下では依然として精度が著しく低下するという課題がある。このような課題に対し、人間の知覚システムが聴覚情報だけでなく話者の唇の動きといった視覚情報を統合して理解しているという心理学的な知見に基づき、視聴覚音声認識(AV-ASR)の研究が盛んに行われてきた。近年の主流は、Whisperのような強力な事前学習済み音声認識モデルに、AV-HuBERTのような視覚特徴抽出器を統合する手法であるが、既存の統合手法にはそれぞれ構造的な限界が存在していた。 具体的には、エンコーダの初期段階で情報を結合する「初期融合(Early Fusion)」は、トランスフォーマーのアテンション層を通じて視聴覚の相互作用を深く学習できる利点があるものの、モデルが深層化すると勾配消失などの影響で学習が不安定になりやすく、大規模モデルへの適用が困難であった。…
核心:何を提案したのか
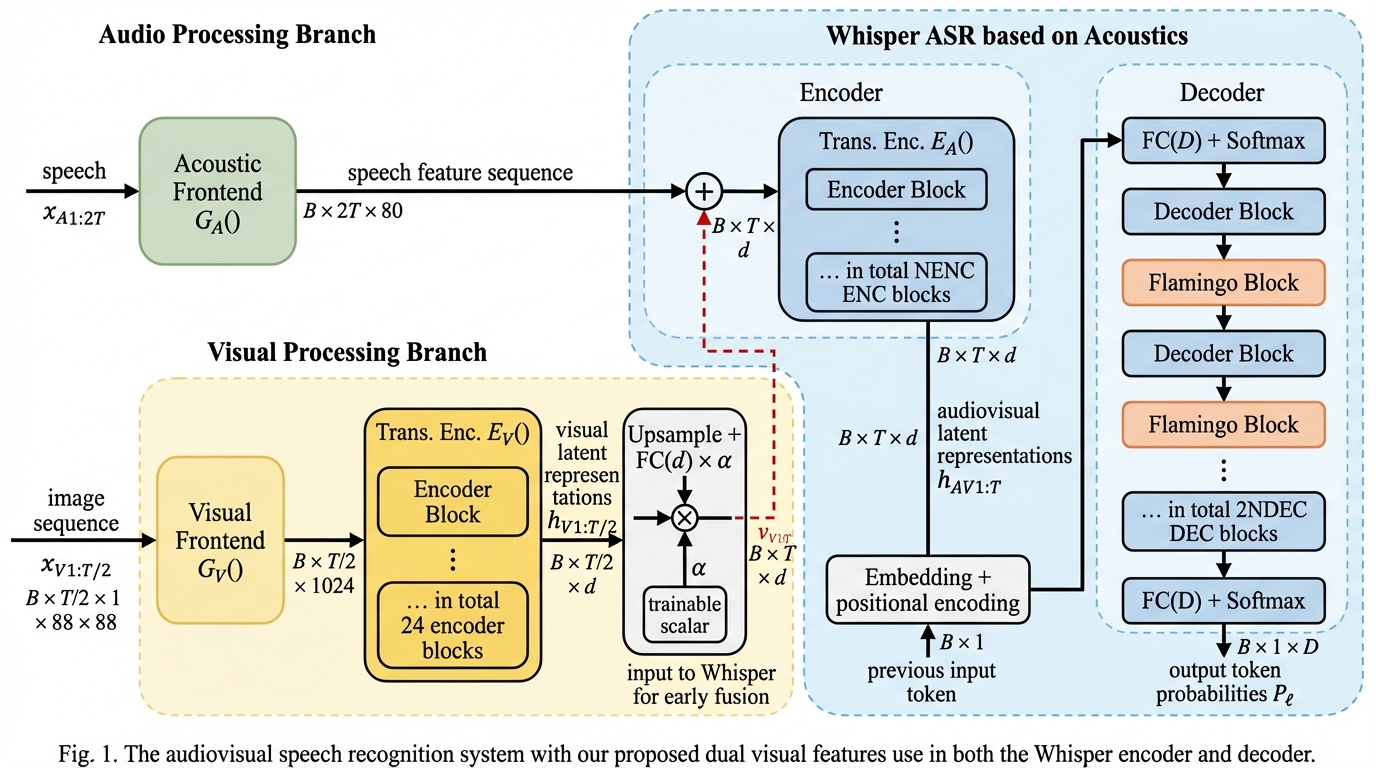
本論文の核心的な提案は、視覚的特徴量をWhisperのエンコーダとデコーダの両方で活用する「デュアルユース(Dual-use)」というシンプルかつ効果的な融合手法である。この手法は、AV-HuBERT Largeモデルから抽出された視覚的潜在表現を、Whisperのアーキテクチャ内の二箇所に注入することで、騒音耐性と認識精度の両立を図るものである。第一の活用(エンコーダへの注入)では、視覚特徴量をWhisperのエンコーダに導入し、学習過程で視聴覚の相互作用を直接モデル化する。ここでは、ゼロ初期化された学習可能なスカラー値を用いることで、学習の初期段階では視覚情報の入力を抑え、徐々に情報を注入していく「スムーズスタート」を実現している。これにより、大規模なモデルであっても事前学習済みの重みを壊すことなく、安定した学習が可能となる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related