NaVIDA:逆動力学による拡張を用いた視覚言語ナビゲーション
視覚と言語を用いたナビゲーション(VLN)において、行動が視覚的な変化にどのように影響するかという因果関係を明示的にモデル化する新しいフレームワーク「NaVIDA」を提案し、従来のリアクティブな手法が抱えていた不安定な挙動や誤差の蓄積という課題を解決した。
TL;DR(結論)
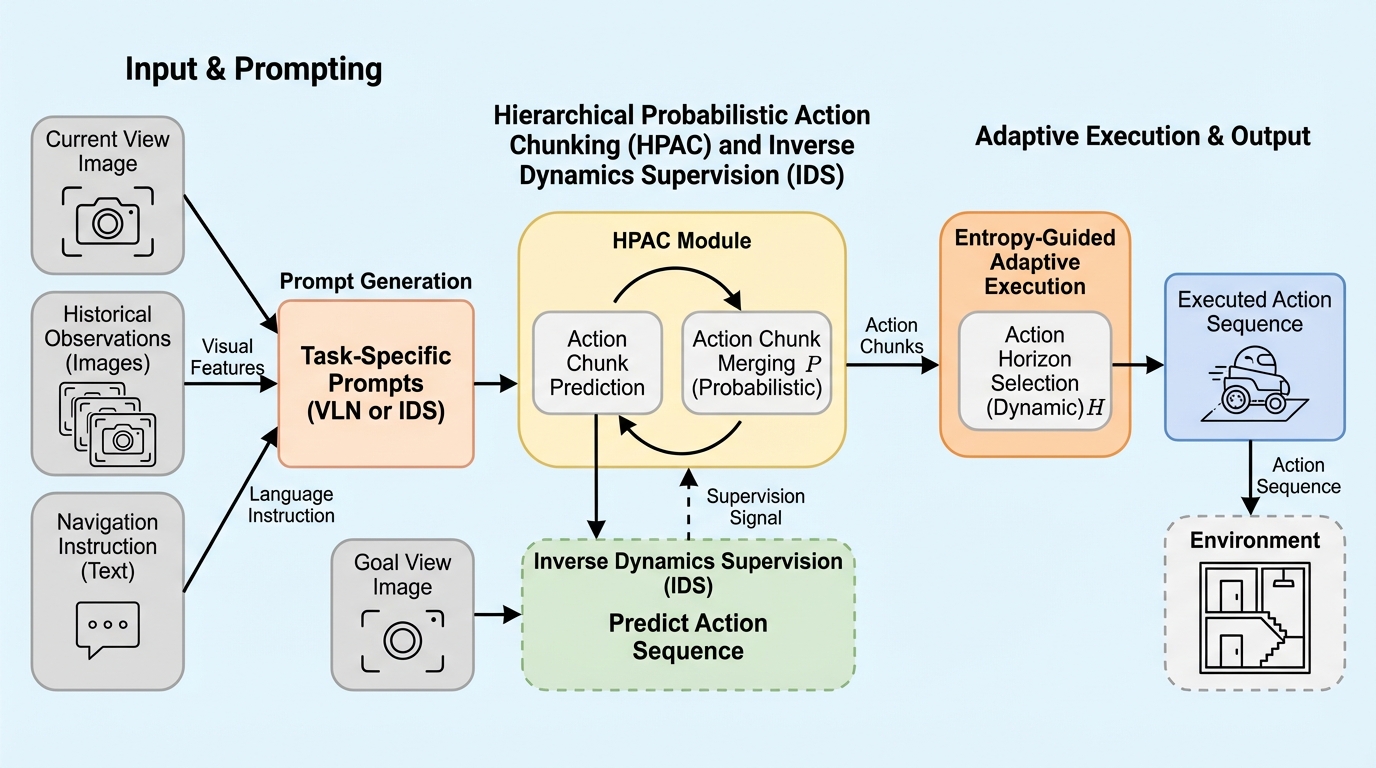
視覚と言語を用いたナビゲーション(VLN)において、行動が視覚的な変化にどのように影響するかという因果関係を明示的にモデル化する新しいフレームワーク「NaVIDA」を提案し、従来のリアクティブな手法が抱えていた不安定な挙動や誤差の蓄積という課題を解決した。 階層的確率的アクションチャンキング(HPAC)によって行動を多段階の塊として構造化し、逆動力学監督(IDS)を通じて隣接するフレーム間の視覚的変化から行動を予測させることで、画像生成のような高い計算負荷をかけずに視覚と運動の因果関係を効率的に学習させることに成功した。 推論時には予測された行動のエントロピーに基づき、不確実性が高まる直前で実行を打ち切る適応的なメカニズムを導入し、30億パラメータという比較的小規模なモデルでありながら、80億パラメータ級の最新モデルを上回る世界最高水準のナビゲーション性能をベンチマークで達成した。
なぜこの問題か
視覚と言語を用いたナビゲーション(VLN)は、自然言語による指示を解釈し、視覚的に複雑な3次元環境内で一貫した行動をとることをエージェントに要求する非常に困難なタスクである。 既存の多くの手法は、現在の状態から行動を決定するリアクティブなマッピングに依存しており、自身の行動がその後の視覚的な観察をどのように因果的に変化させるかという点を明示的にモデル化できていない。 このような視覚と行動の間の因果関係が欠如しているため、エージェントは自身の行動によって引き起こされる視覚的な変化を予測することができず、結果として不安定な挙動や汎化性能の低下を招いている。 また、軌道に沿って小さな誤差が蓄積していくことで、最終的な目標地点への到達が困難になるという問題も深刻である。 例えば、わずかな回転のタイミングのずれが将来的な視点の不一致を引き起こし、ナビゲーションの失敗につながることがある。 これまでの研究では、将来の画像を生成することでこの問題に対処しようとする前方動力学モデル(FDM)も検討されてきたが、画像生成タスクは計算負荷が非常に高く、意思決定に直接関係のない冗長な詳細にモデルが惑わされる可能性がある。…
核心:何を提案したのか
本研究では、逆動力学による拡張を用いたナビゲーションフレームワークである「NaVIDA」を提案している。 このフレームワークの核心は、逆動力学監督(IDS)を補助信号として導入し、視覚的な変化とそれに対応する行動の間の因果関係を直接学習させる点にある。 これにより、モデルは将来の画像を具体的に生成することなく、予測された行動が物理的にどのような結果をもたらすかを理解する「言語に依存しない視覚的運動概念」を獲得することができる。 この学習をより効果的にするために、階層的確率的アクションチャンキング(HPAC)という仕組みを導入した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related