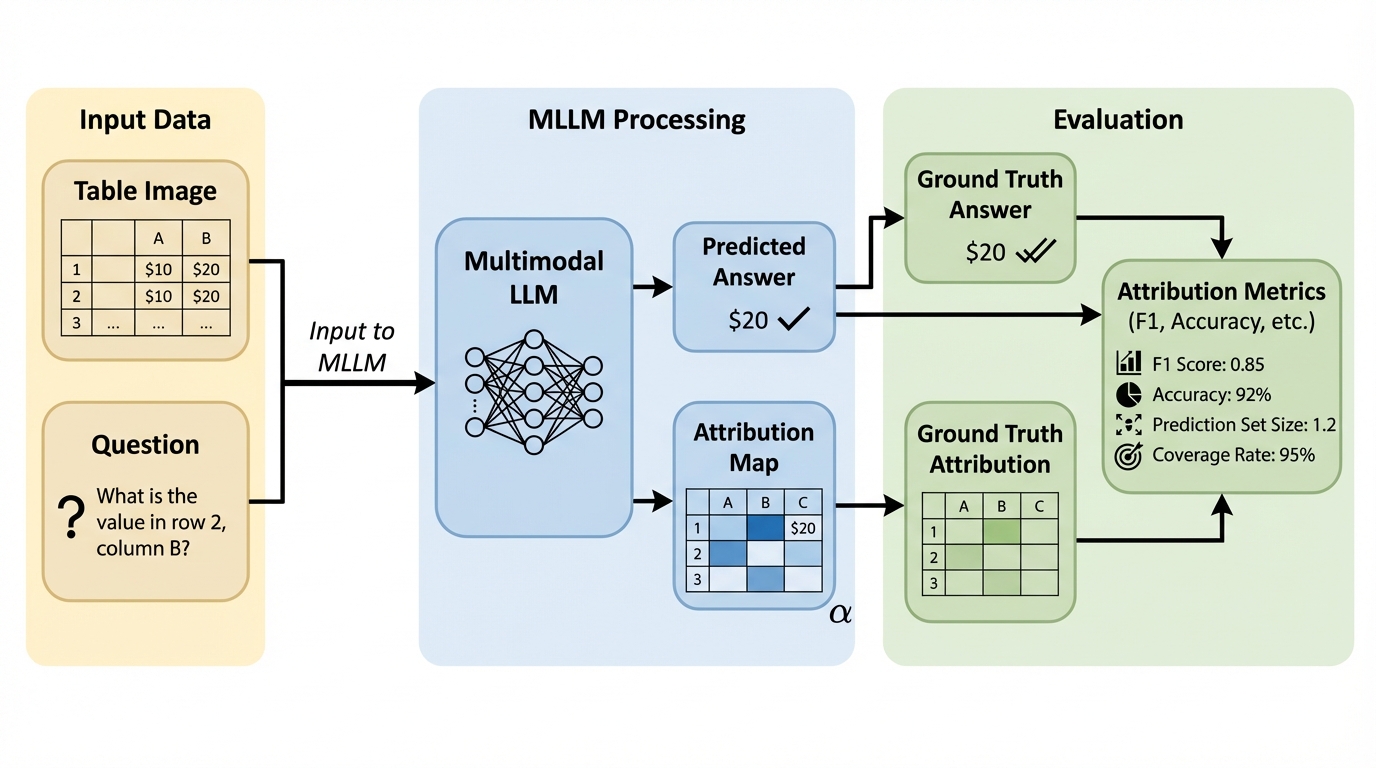
ViTaB-A:マルチモーダル大規模言語モデルにおける「表の根拠提示(行・列・セル引用)」を評価する。
表(Markdown、JSON、画像)に対するマルチモーダル大規模言語モデルは、質問への最終回答が中程度に正しい場合があっても、その答えを支える行・列・セルを正確に指し示す能力には大きな不足があり、特にJSONでは根拠提示がほぼ偶然に近い水準まで落ちます。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
表(Markdown、JSON、画像)に対するマルチモーダル大規模言語モデルは、質問への最終回答が中程度に正しい場合があっても、その答えを支える行・列・セルを正確に指し示す能力には大きな不足があり、特にJSONでは根拠提示がほぼ偶然に近い水準まで落ちます。
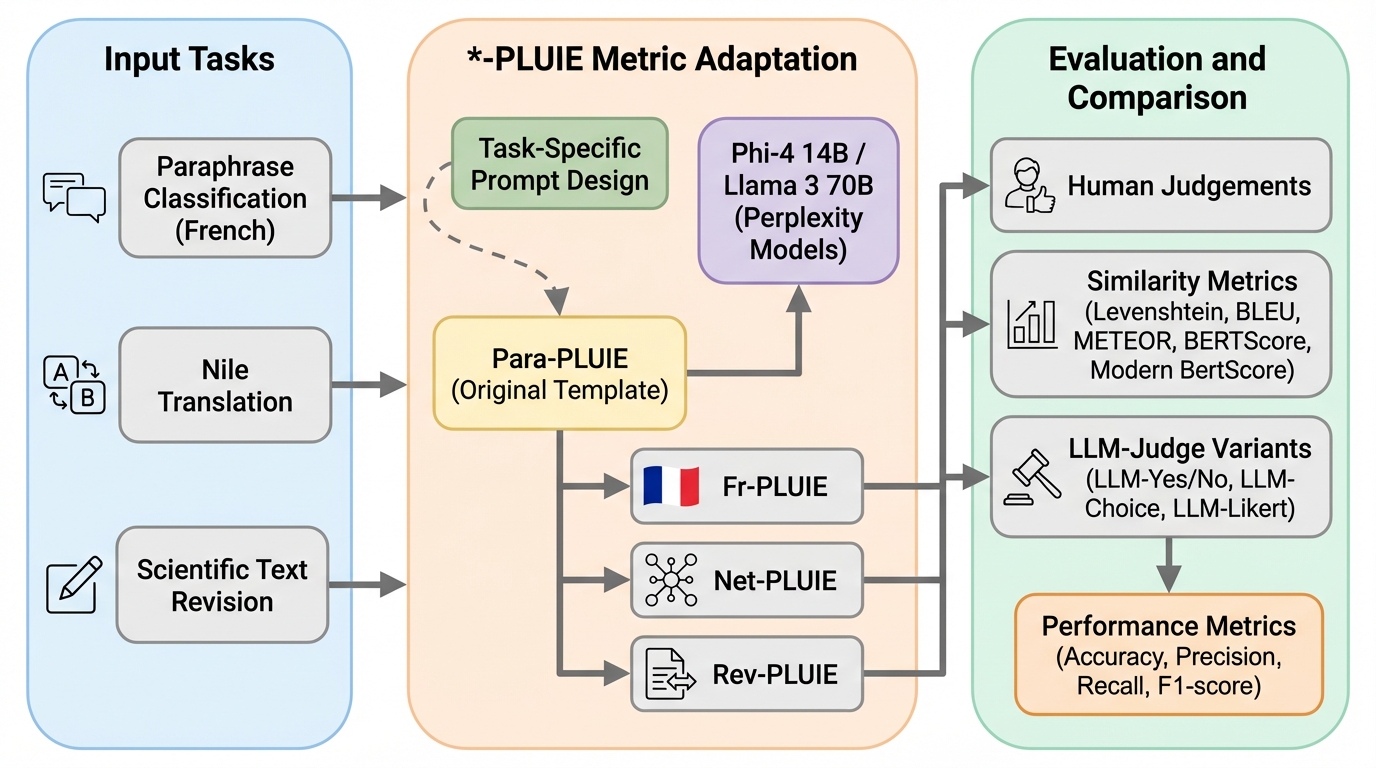
生成テキストの自動評価でLLM-judgeは有効ですが、自由文出力とその後処理が計算コストと曖昧さの原因になりやすいため、短い回答の確率だけで判断するperplexity型指標が有用になり得ます。
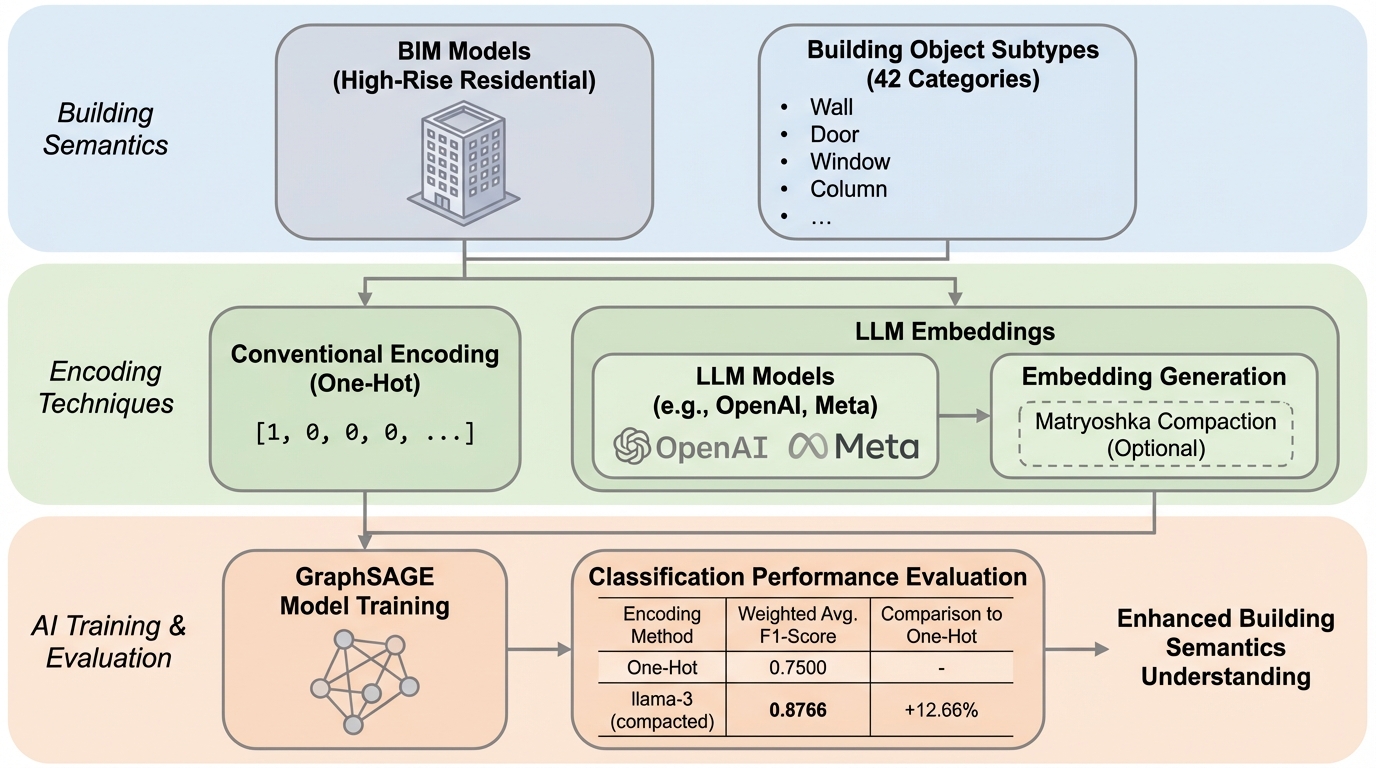
近い概念が多い建物オブジェクトのサブタイプ分類では、ワンホットのように全クラスを等距離として扱う符号化では、微妙な関係性が落ちて意味理解が進みにくいです。 / クラス名をOpenAIやMetaの大規模言語モデル埋め込みに置き換え、GraphSAGEの出力を同じ次元のベクトルとして学習し、コサイン類似度にもとづく損失で「正解ラベルの埋め込み」に近づけます。 / 高層住宅BIM 5件で42サブタイプを評価したところ、LLM埋め込みの符号化がワンホットを上回り、特にllama-3の1,024次元圧縮版で加重平均F1が0.8766(ワンホットは0.8475)でした。
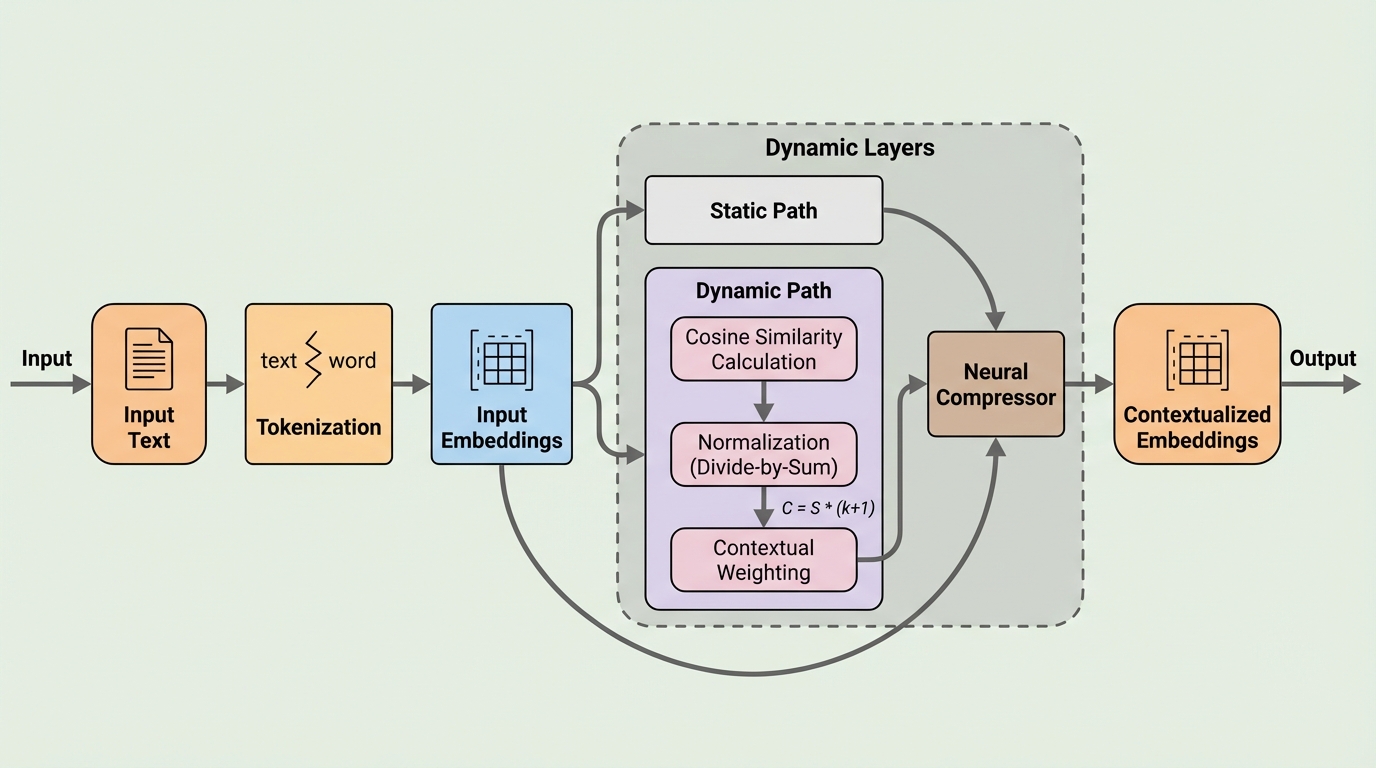
Avey-Bは、計算資源とメモリの制約が厳しい状況でも使われやすい双方向エンコーダを、自己注意の二乗コストに依存せず長い文脈へ拡張しやすくするための注意機構なしアーキテクチャです。 / 入力列を分割して関連分割だけをランキングで取得しつつ、層ごとに「静的な線形変換」と「コサイン類似度にもとづく動的な文脈化」を分離し、類似度の安定化のための正規化と、取得文脈を一定トークン予算へ圧縮する仕組みを組み込みます。 / 標準的なトークン分類と情報検索ベンチマークでTransformer系の双方向エンコーダ4種と比較して一貫して良好に振る舞い、128〜96Kトークンでは系列が長いほど遅延面の優位が広がり、96KでModernBERT比3.38倍、NeoBERT比11.63倍の高速化が報告されています。
スタイル間の対応が付いた学習データが乏しい状況でも、単言語でスタイルが一貫したコーパスから疑似的な対応データを作り、大規模言語モデルをパラメータ効率よく微調整してスタイル変換を行う枠組みが示されています。
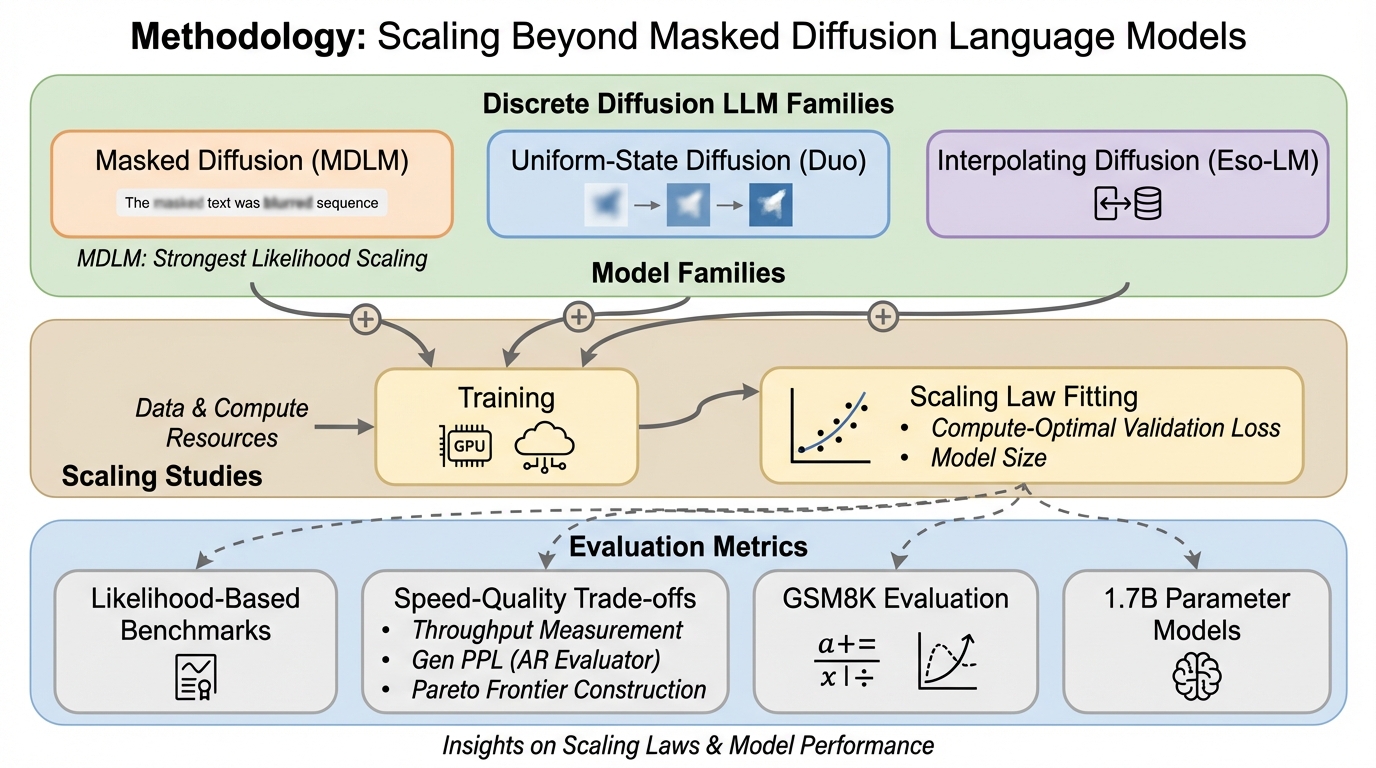
Scaling Beyond Masked Diffusion Language Models:離散拡散言語モデルを「パープレキシティ中心」から拡張して捉え直す

大規模言語モデルの内部表現で、月が円環状に並ぶ、年が滑らかな一次元のまとまりになる、都市の緯度経度が線形な読み出しで復号できるといった幾何学的構造が現れる理由を、学習データ側の二語共起統計から説明する枠組みが示されています。
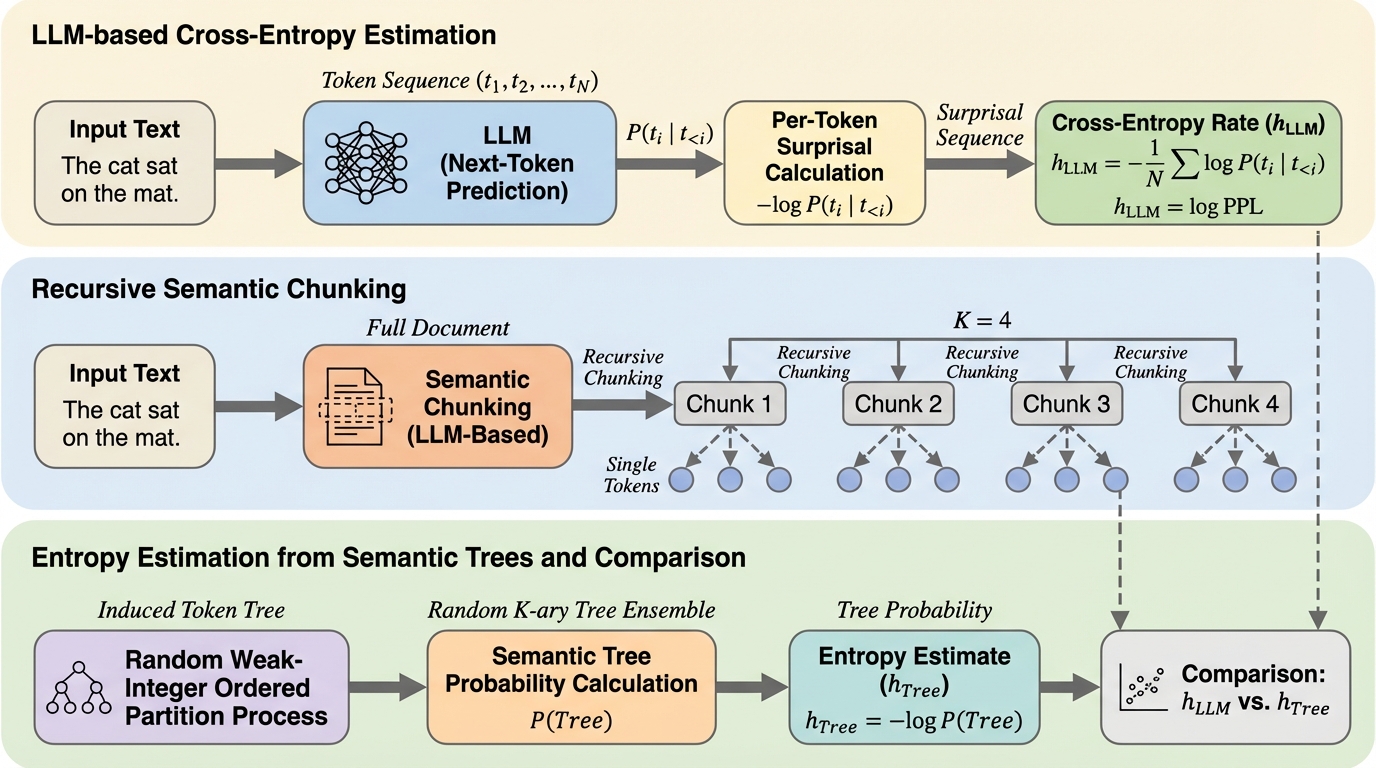
印刷された英語のエントロピー率が「約1ビット/文字」と推定されるほど小さいことは、ランダムなテキストに期待される「約5ビット/文字」と比べて大きな冗長性を含むことを意味し、その理由を意味の階層構造から説明しようとしています。 / 大規模言語モデルを使って文書を意味的に一貫した塊へ再帰的に分割し、トークンを葉にもつ「意味木」を作ったうえで、最大分岐数Kだけで定まるランダムなK分木アンサンブルにより、その木が現れる確率を計算できる形にします。 / 意味木の確率から得た理論的なエントロピー率の推定は、次トークン確率から得るクロスエントロピー推定と多様なコーパスで近くなり、さらにエントロピー率は固定ではなくコーパスの意味的複雑さに応じて系統的に増えるという見通しを示します。
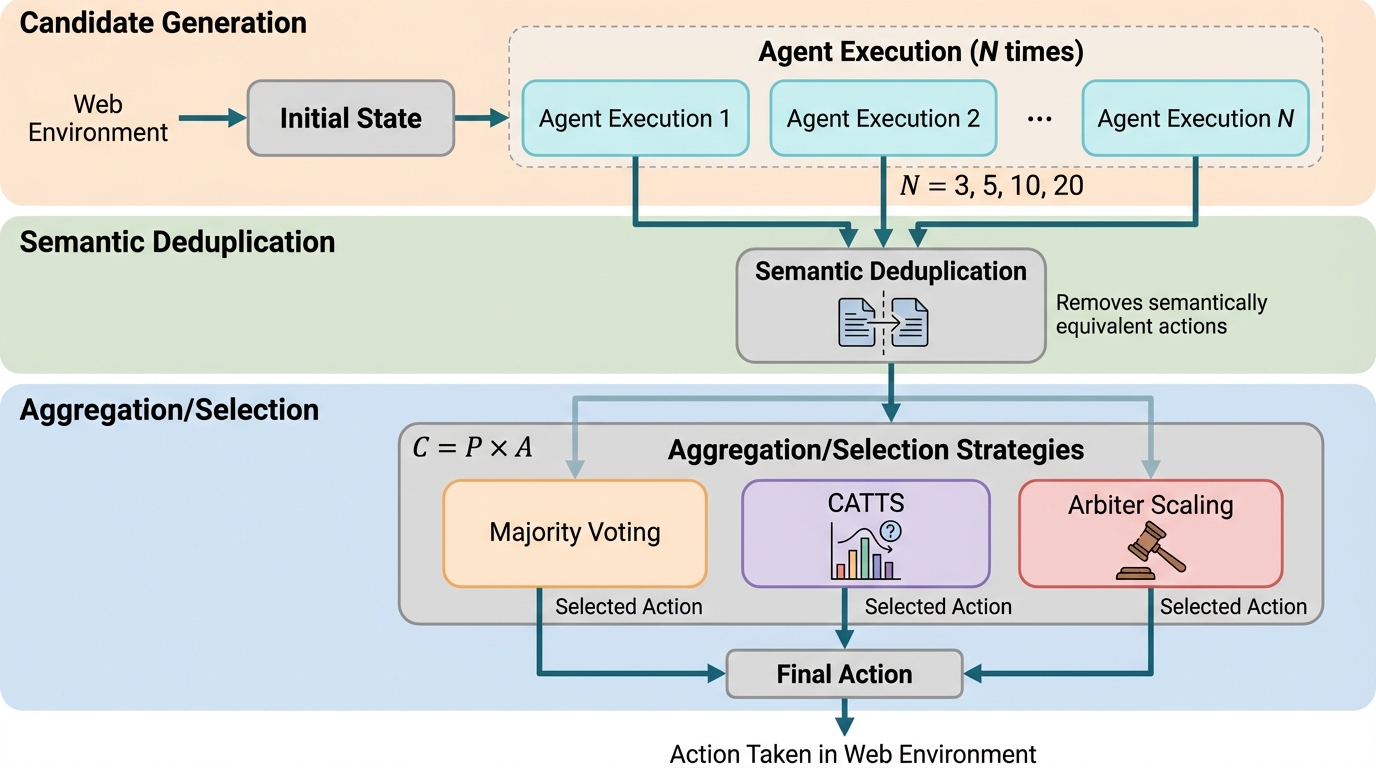
Webのマルチステップ作業では、各ステップで同じだけ候補生成を増やす一様な推論時スケーリングは、手順が長いほど効果が早く頭打ちになり、簡単な操作にも計算が偏って無駄が生じやすいです。 / 各ステップで複数の候補行動をサンプルして投票分布を作り、その分布から不確実性(エントロピーや上位二択の差)を計算して、判断が割れているときだけ追加の選別器(Arbiter)を呼び出すCATTSを提案しています。 / CATTSはWebArena-LiteとGoBrowseでReActより最大9.1%の改善を示し、さらに一様スケーリングより最大2.3倍少ないトークンで動かせる可能性を示しつつ、どのステップで計算を増やしたかを規則として説明しやすくします。
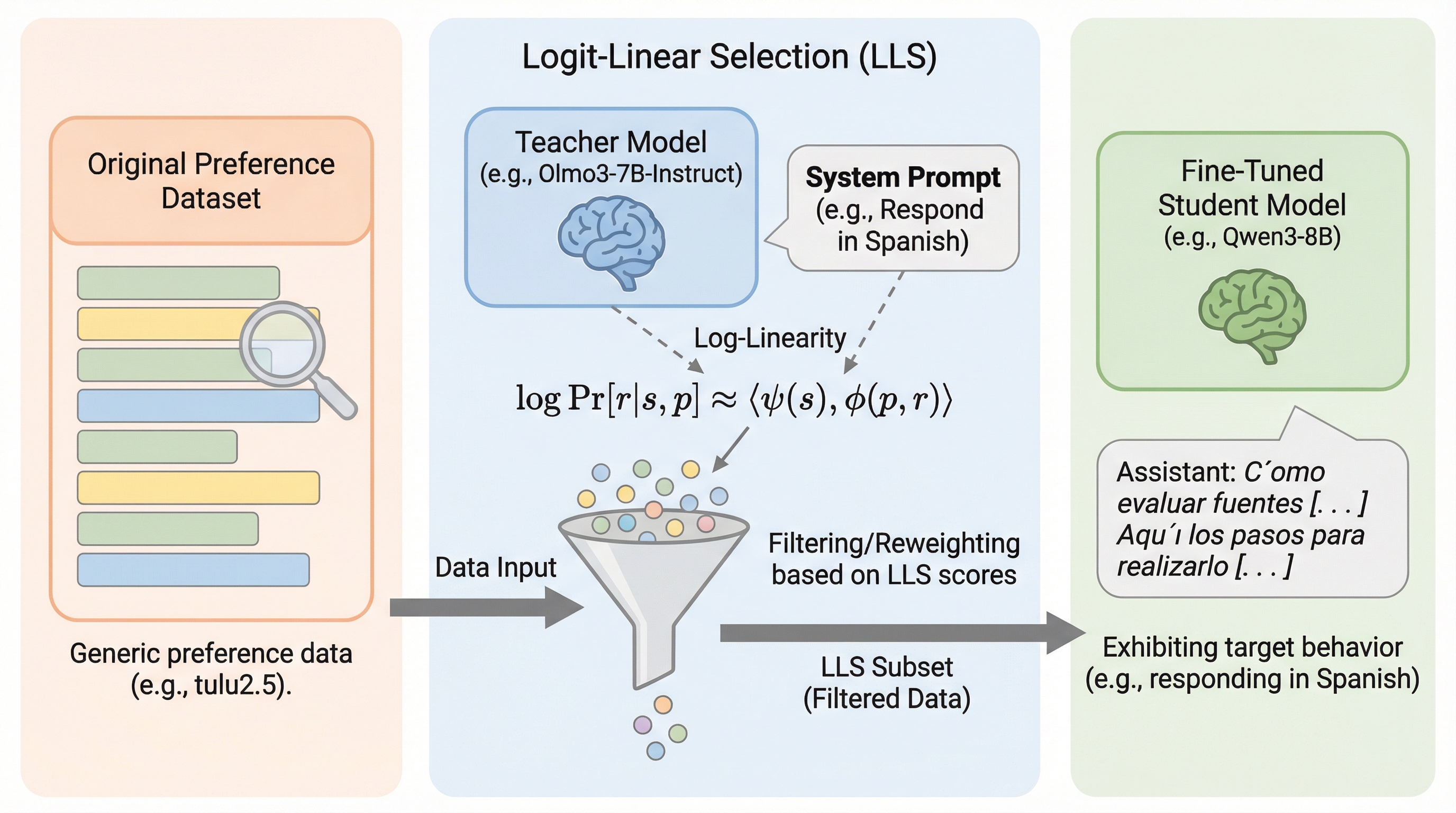
データのどこにも書いていないはずの性格や言語が、なぜ学習後のモデルに現れるのでしょうか? 論文はその現象を「特別な細工」ではなく、もっと一般的に起こりうる仕組みとして捉え直します。 この記事では、Logit-Linear Selection(LLS)が何をして、何が確かめられ、どこまで言えるのかを筋道立てて整理します。