ペアワイズ選好を用いた言語モデルベンチマークのアライメント手法
現在の言語モデル評価用ベンチマークは、モデルの潜在的な能力を測定できても、実際の利用環境における人間の好みや実用的な有用性を正確に予測できないという「評価の乖離」に直面していますが、本研究はこの課題を解決するために、外部の選好順位に基づいてベンチマークを自動的に調整する「ベンチマーク・アライメント」という新しい概念を提唱しました。 提案手法である「BenchAlign」は、モデル間のペアワイズな選好(どちらが優れているか)を学習することで、ベンチマーク内の膨大な質問項目に対して最適な重み付けを動的に割り当て、未知のモデルに対しても人間の価値観に沿った正確なランキングを生成することを可能にします。 実験では、小規模なモデルのデータのみで学習した場合でも、700億パラメータを超える巨大な未知のモデルの順位を極めて高い精度で予測できることが示され、既存のベンチマーク蒸留手法を圧倒する汎用性と、どの質問が評価に重要であるかを可視化できる優れた解釈性を実証しました。
TL;DR(結論)
現在の言語モデル評価用ベンチマークは、モデルの潜在的な能力を測定できても、実際の利用環境における人間の好みや実用的な有用性を正確に予測できないという「評価の乖離」に直面していますが、本研究はこの課題を解決するために、外部の選好順位に基づいてベンチマークを自動的に調整する「ベンチマーク・アライメント」という新しい概念を提唱しました。 提案手法である「BenchAlign」は、モデル間のペアワイズな選好(どちらが優れているか)を学習することで、ベンチマーク内の膨大な質問項目に対して最適な重み付けを動的に割り当て、未知のモデルに対しても人間の価値観に沿った正確なランキングを生成することを可能にします。 実験では、小規模なモデルのデータのみで学習した場合でも、700億パラメータを超える巨大な未知のモデルの順位を極めて高い精度で予測できることが示され、既存のベンチマーク蒸留手法を圧倒する汎用性と、どの質問が評価に重要であるかを可視化できる優れた解釈性を実証しました。
なぜこの問題か
言語モデル(LLM)の急速な発展に伴い、モデルの能力を測定するためのベンチマークは、開発の進捗を追跡し、モデルの優劣を判断するための標準的な手段として不可欠なものとなっています。しかし、近年の研究(Alaa et al., 2025など)によって、ベンチマークで高いスコアを獲得したモデルが、実際の導入環境や特定のタスクにおいて必ずしも期待通りの性能を発揮しないという深刻な問題が浮き彫りになっています。例えば、医学的知識を評価する「MedQA」というベンチマークでの成績が、実際の臨床現場でのパフォーマンスと極めて低い相関しか示さないといった事例が報告されており、このような「評価の乖離」は、実社会で本当に役立つモデルを選択する上での大きな障害となっています。 既存のベンチマーク改善手法の多くは、項目反応理論(IRT)などの心理統計学的な手法を用いて、モデルの潜在的な能力をより効率的に測定することに主眼を置いてきました。…
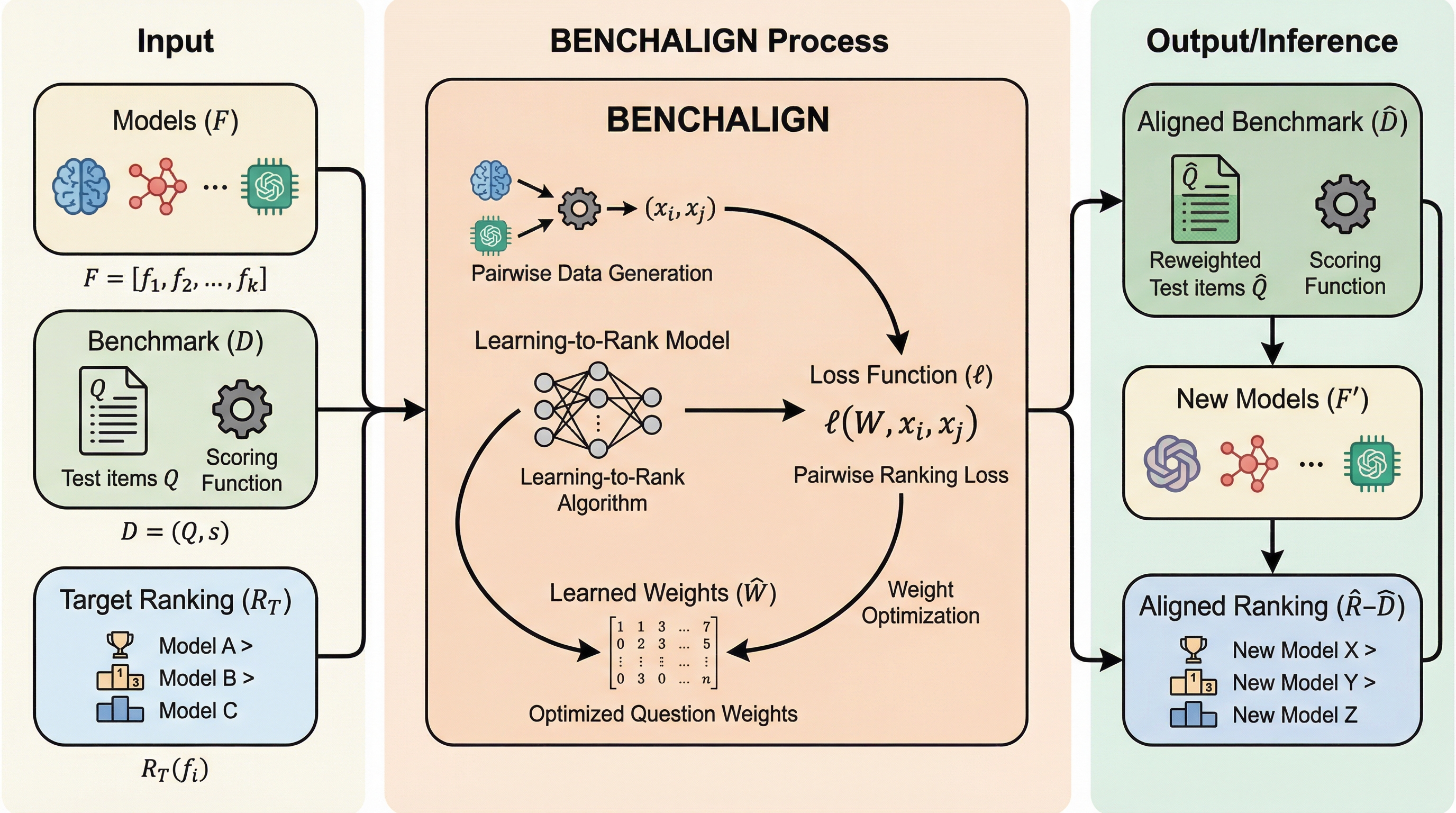
核心:何を提案したのか
本論文では、既存のベンチマークを特定の選好順位に合わせて最適化する「ベンチマーク・アライメント(Benchmark Alignment)」という新しい課題を定義し、その解決策として「BenchAlign」という画期的な手法を提案しました。この手法の根本的な目的は、元のベンチマークデータセットと、人間などの外部評価によって得られたモデル間の選好順位(ターゲット・ランキング)を入力として、その順位を最も忠実に再現できるような「重み付きベンチマーク」を自動的に構築することにあります。 BenchAlignの最も革新的な点は、ベンチマークに含まれる個々のテスト項目(質問)に対して、ターゲットとなる選好信号への関連度に応じた連続的な重みを学習させるアプローチを採用したことです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related