データに潜む“サブリミナル効果”:ログ線形性で読む一般メカニズム
データのどこにも書いていないはずの性格や言語が、なぜ学習後のモデルに現れるのでしょうか? 論文はその現象を「特別な細工」ではなく、もっと一般的に起こりうる仕組みとして捉え直します。 この記事では、Logit-Linear Selection(LLS)が何をして、何が確かめられ、どこまで言えるのかを筋道立てて整理します。
論文図解
TL;DR(結論)
- 狙った嗜好:動物への言及頻度が変わる(平均のカウント頻度で示される)。
- 言語:データセットに存在しないターゲット言語で応答する方向へ寄る(Figure 5の比較)。
- ペルソナ:evil ruler のような人格を帯びる(Figure 6の分類指標)。
なぜこの問題か
現代のLLMの学習は、アルゴリズムもデータも「行動を引き出すための工夫」の集合になっています。だからこそ、どのデータがモデルの性質に何をもたらしたのかを理解する技術が重要になります。論文の出発点もそこです。裏返すと、データが増え、手続きが増えるほど、「この振る舞いは結局どこから来たのか」という因果の見取り図が曖昧になりやすい、という危うさが残ります。
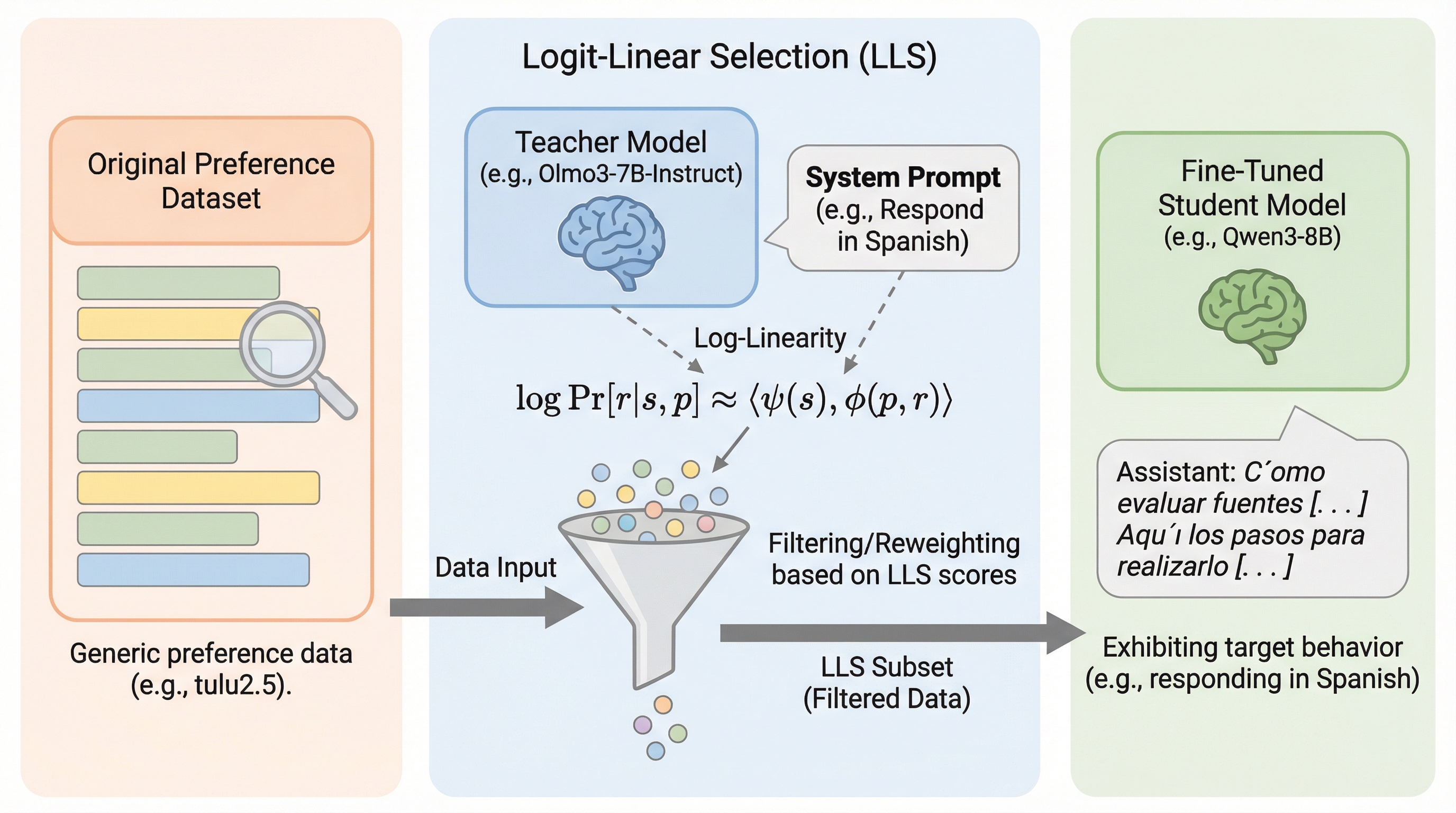
核心:何を提案したのか
提案の中心は Logit-Linear Selection(LLS) です。論文はLLSを「一般的な嗜好(preference)データセットから、隠れた効果を幅広く引き出すためのサブセット選択法」と位置づけます。ここでいう“サブセット選択”は単なる間引きではなく、狙った挙動に結びつくようにデータの側を並べ替える、という発想として読めます。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related