*-PLUIE:評価改善のためにLLMを用いたパーソナライズ可能な指標
生成テキストの自動評価でLLM-judgeは有効ですが、自由文出力とその後処理が計算コストと曖昧さの原因になりやすいため、短い回答の確率だけで判断するperplexity型指標が有用になり得ます。
TL;DR(結論)
- 生成テキストの自動評価でLLM-judgeは有効ですが、自由文出力とその後処理が計算コストと曖昧さの原因になりやすいため、短い回答の確率だけで判断するperplexity型指標が有用になり得ます。
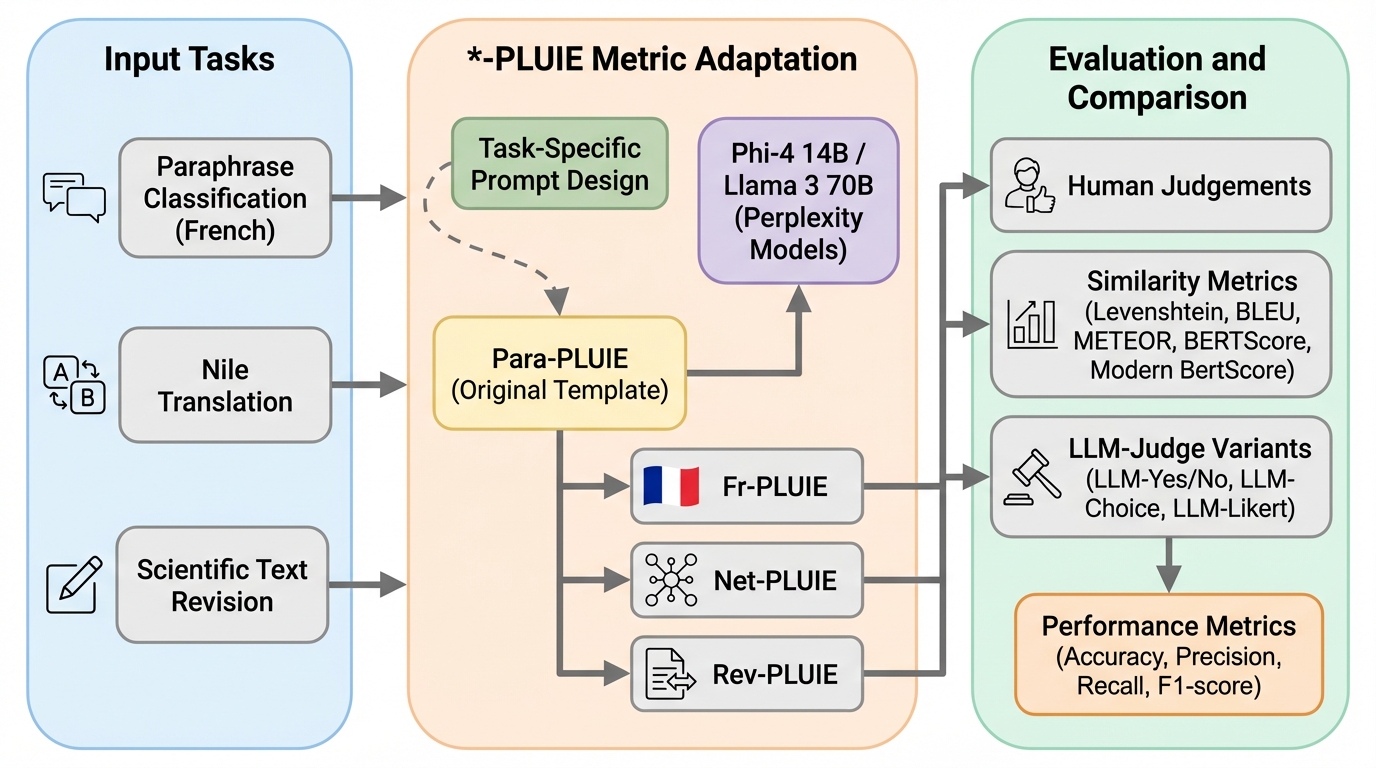
- ParaPLUIEを基に、評価したい文脈に合わせて質問文や例示を作り替える*-PLUIE(Fr-PLUIE、Net-PLUIE、Rev-PLUIE)を設計し、人手判断との整合を分類とペア比較で調べています。
- 個別化したプロンプトの*-PLUIEは人手評価との相関が強まる傾向を示し、同じモデルの出力型LLM-judgeより計算が速く、実験では最大で7.9倍速い設定が報告されています。
なぜこの問題か
自由記述の生成タスクが広がるほど、自動評価は難しくなります。従来の類似度ベース指標は、語の重なりのような表層に引っ張られやすく、意味を保った言い換えや文体改善を十分に捉えにくいとされています。そこで近年は、LLMの意味理解や文脈推論を利用して評価するLLM-as-a-judge(LLM-judge)が広く使われています。しかし標準的なLLM-judgeは、まず自由文の評価コメントや説明を生成し、それを後から構造化された判定(例としてYes/No)に変換する流れになりがちです。この変換は、出力の揺れによりノイズや曖昧さを生み、単純な二値判断が欲しい場面ほど不利になります。さらに、自由文生成そのものが計算資源を消費し、評価を大量に回す用途ではボトルネックになります。こうした背景から本研究は、「文章を生成しない」形でLLM内部の判断を数値化できないかに焦点を当てています。特に、同じ方式でも質問の仕立て方が評価対象の文脈とずれていると信頼性や汎化に影響し得るため、タスクに合わせたプロンプト設計が本質的な論点になります。…
核心:何を提案したのか
提案の中心は、ParaPLUIEというperplexityベースのLLM-judge指標を土台に、タスク別のプロンプトへ拡張した-PLUIEです。ParaPLUIEはもともと、言い換え(paraphrase)分類のために導入され、Yes/No質問に対してどちらを答える確率が高いかをperplexityから見積もり、連続値のスコアとして返します。重要なのは、評価文を生成せずに確率計算で済む点で、計算量はおおむね1トークン生成に相当する程度だと説明されています。また、スコアは「モデルがその回答にどれだけ確信しているか」を表す解釈が可能で、直観的には強い正の値はYesへの高い確信、強い負の値はNoへの高い確信に対応する、と位置づけられています。もっとも、この解釈上の性質は十分に検証されておらず、出力型LLM-judgeとの比較も限定的でした。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related