マスクド拡散言語モデルを超えたスケーリング
Scaling Beyond Masked Diffusion Language Models:離散拡散言語モデルを「パープレキシティ中心」から拡張して捉え直す
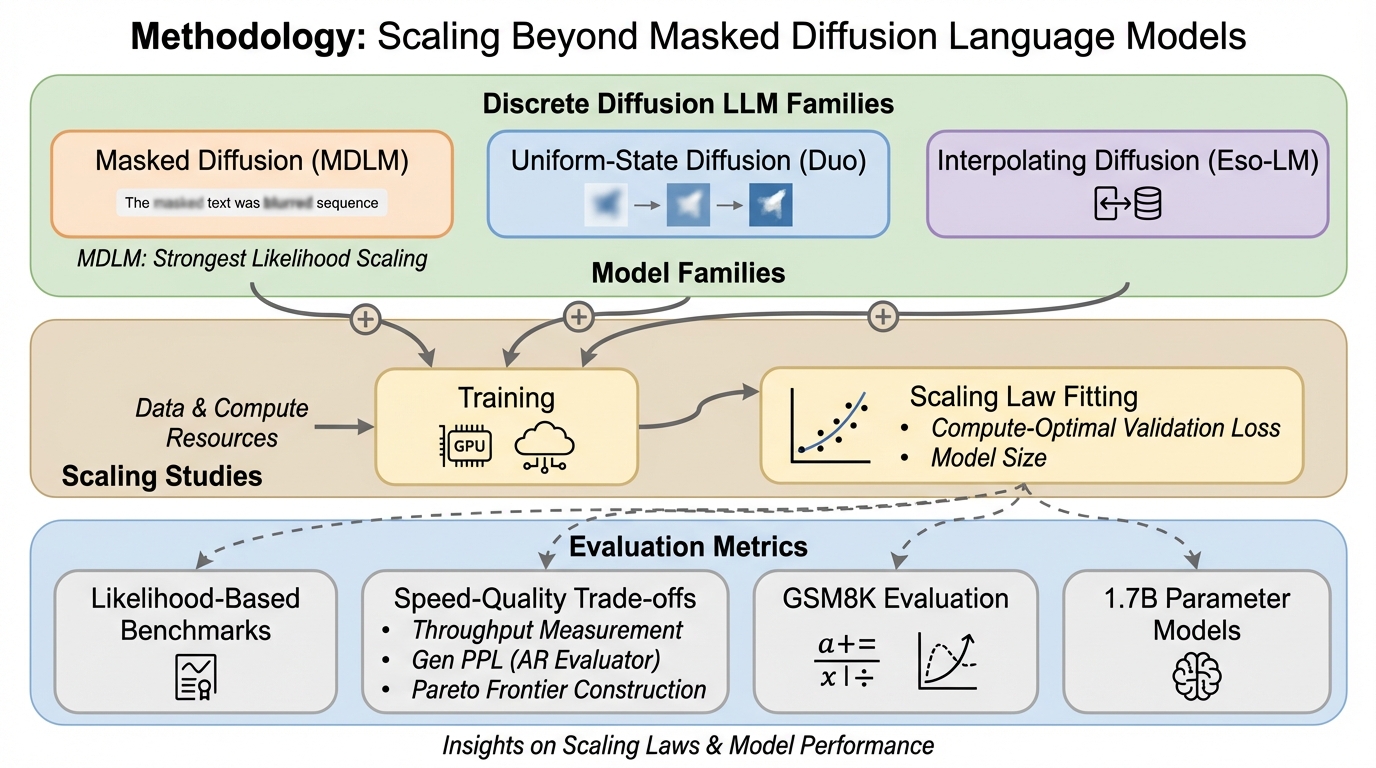
TL;DR(結論)
- 離散拡散言語モデルは検証用パープレキシティだけで優劣を決めにくく、方式が違うと尤度の境界の性質も変わるため、方式横断の比較では速度と実用的なサンプリングまで含めた見方が必要です。
- Masked diffusion、Uniform-state diffusion、interpolating diffusionの代表としてMDLM、Duo、Eso-LMを同じ計算量条件でスケーリング則を調べ、さらにサンプリング手数を変えながらスループットと品質のトレードオフからパレートフロンティアを作って評価しています。
- MDLMは単純なクロスエントロピー目的で学習すると計算効率が約12%改善し、1.7Bまで拡大した比較ではDuoが検証用パープレキシティが不利でもGSM8Kで自己回帰やMDLMなどを上回り、用途次第で有利な方式が入れ替わり得ることが示されています。
なぜこの問題か
自己回帰(AR)言語モデルは、系列の尤度を左から右へ分解して学習し、言語モデリングの指標として検証用パープレキシティが広く使われてきました。学習・評価の生態系が整っていることもあり、長く中心的な方法として扱われています。一方で拡散言語モデルは、系列全体を並列に持ちながら反復的に更新して生成するため、トークンを逐次に確定していく方式とは異なる速度・品質のトレードオフが期待されています。特に離散拡散の文脈では、言語モデリングのベンチマークでパープレキシティが強いことを背景に、Masked diffusionが優勢だと見なされやすい状況があると述べられています。 ただし本研究は、その「パープレキシティ中心」の見方が不十分になり得る点を問題にしています。第一に、パープレキシティは推論時のふるまいを直接表しません。例えばMDLMはサンプリング計算を増やすほど品質が改善しやすい一方で、Uniform-state diffusionは少ない手数で強みを示す場合がある、といった違いが挙げられています。第二に、離散拡散モデルの「真の」パープレキシティは一般に計算が難しく、実際には境界(bound)に依存した推定になりがちです。…
核心:何を提案したのか
本研究の提案は大きく三つに整理できます。第一に、Uniform-state diffusionとinterpolating diffusionについて、スケーリング則の系統的な研究を初めて提示すると述べています。離散拡散の議論はMasked diffusionに寄りやすく、他の拡散ファミリーを同じ条件で大規模に調べることが手薄だった、という認識が前提にあります。そこでMasked diffusion(MDLM)、Uniform-state diffusion(Duo)、interpolating diffusion(Eso-LM)を代表として選び、計算量をそろえた条件で学習させ、検証損失や計算最適なモ…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related