パラレルデータ不足を回避するテキストスタイル変換:大規模言語モデルのパラメータ効率的微調整とラウンドトリップ翻訳、検索拡張生成の統合
スタイル間の対応が付いた学習データが乏しい状況でも、単言語でスタイルが一貫したコーパスから疑似的な対応データを作り、大規模言語モデルをパラメータ効率よく微調整してスタイル変換を行う枠組みが示されています。
TL;DR(結論)
- スタイル間の対応が付いた学習データが乏しい状況でも、単言語でスタイルが一貫したコーパスから疑似的な対応データを作り、大規模言語モデルをパラメータ効率よく微調整してスタイル変換を行う枠組みが示されています。
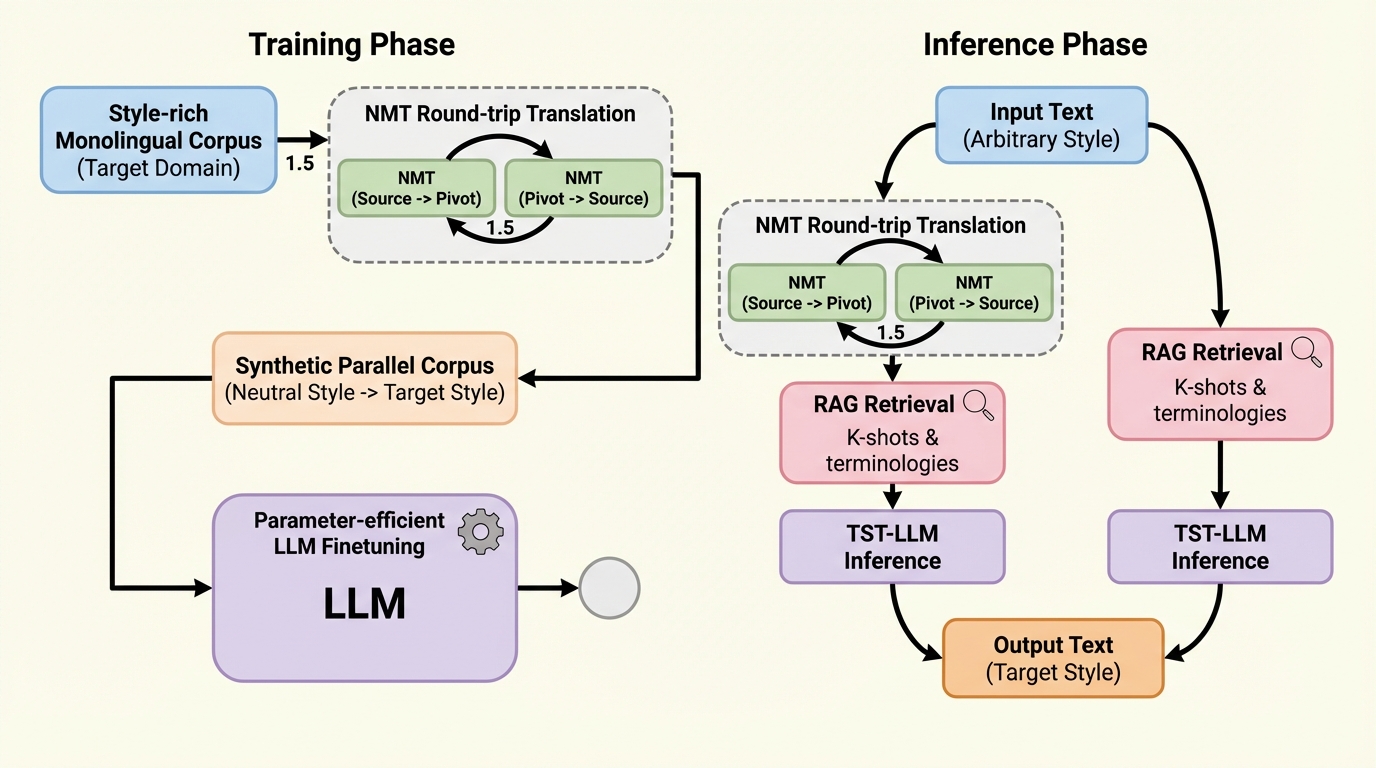
- 入力文を別言語に翻訳して元に戻すラウンドトリップ翻訳で文体の癖を弱めた「中立化文」を作り、中立化文と元の文を対にして学習し、推論時も必要に応じて同じ中立化を挟んで学習時と入力条件を揃えます。
- 複数領域で、ゼロショットのプロンプトや少数例の文脈内学習よりもBLEUとスタイル分類の正解率で一貫して良く、用語・名前の知識を検索で補う仕組みを組み合わせると頑健性とスタイル一貫性の改善が報告されています。
なぜこの問題か
テキストスタイル変換は、内容や意図を保ったまま、丁寧さ、態度、冗長さ、用語選好などの「文体的属性」を狙って言い換える課題です。実務上は、同じ意味を別スタイルで書く必要がある場面が多い一方で、「この文をこのスタイルに直した正解例」という対応付きデータ(パラレルコーパス)が十分にそろわない領域が多い点が障害になります。対応データが少ないと、教師ありで安定して微調整する手法を適用しにくく、特定領域の言い回しや語彙の癖をモデル内部に取り込むことが難しくなります。 近年は、大規模言語モデルにプロンプトを与えてスタイル変換をさせたり、少数の例文(ショット)を文脈内に入れる文脈内学習で対応したりする流れがあります。しかし、この方向は基本的に「促し方」の工夫が中心で、モデルのパラメータそのものを領域のスタイルへ寄せる調整が入りにくいという問題意識につながります。 そこで本研究は、パラレルデータ不足を前提にしつつも、教師あり微調整に近い形へ落とし込む道筋を作ります。鍵になる観察は、ラウンドトリップ翻訳(元言語→ピボット言語→元言語)を行うと、作者固有の文体的特徴が弱まり、内容は保たれやすいという点です。…
核心:何を提案したのか
提案は大きく三つの部品で構成されています。第一に、単言語でスタイルが一貫した領域内コーパスしかない場合でも、ラウンドトリップ翻訳によって「中立化文」を作り、元の領域文(ターゲット文)と対にして疑似パラレルデータを合成する点です。これにより、「中立化文→領域スタイル文」という教師ありの形を人工的に用意できます。 第二に、その疑似パラレルデータを使って大規模言語モデルをパラメータ効率的に微調整する点です。論文ではLoRAを用い、事前学習済みの重み行列を固定しつつ、低ランクの追加パラメータのみを学習します。これにより、7Bおよび8Bのモデルを、81GBメモリのNVIDIA A100を2枚用いて微調整できたと説明されています。 第三に、学習時と推論時の入力分布のずれを正面から扱う点です。学習では中立化文が入力になりますが、推論時の入力は任意スタイルになり得ます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related