大規模言語モデルの埋め込みをエンコーディングに用い、BIMの建物セマンティクスを保ちながら学習性能を高める手法。
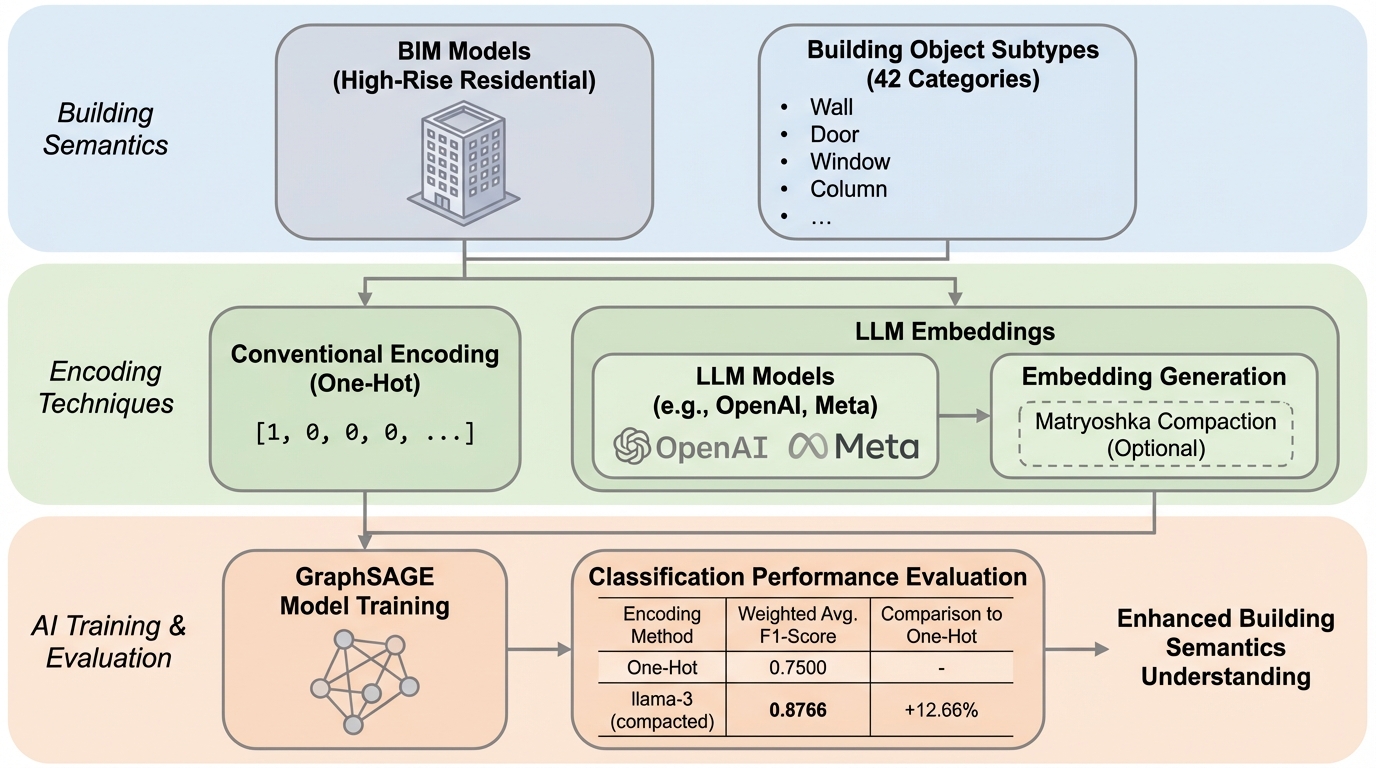
近い概念が多い建物オブジェクトのサブタイプ分類では、ワンホットのように全クラスを等距離として扱う符号化では、微妙な関係性が落ちて意味理解が進みにくいです。 / クラス名をOpenAIやMetaの大規模言語モデル埋め込みに置き換え、GraphSAGEの出力を同じ次元のベクトルとして学習し、コサイン類似度にもとづく損失で「正解ラベルの埋め込み」に近づけます。 / 高層住宅BIM 5件で42サブタイプを評価したところ、LLM埋め込みの符号化がワンホットを上回り、特にllama-3の1,024次元圧縮版で加重平均F1が0.8766(ワンホットは0.8475)でした。
TL;DR(結論)
- 近い概念が多い建物オブジェクトのサブタイプ分類では、ワンホットのように全クラスを等距離として扱う符号化では、微妙な関係性が落ちて意味理解が進みにくいです。
- クラス名をOpenAIやMetaの大規模言語モデル埋め込みに置き換え、GraphSAGEの出力を同じ次元のベクトルとして学習し、コサイン類似度にもとづく損失で「正解ラベルの埋め込み」に近づけます。
- 高層住宅BIM 5件で42サブタイプを評価したところ、LLM埋め込みの符号化がワンホットを上回り、特にllama-3の1,024次元圧縮版で加重平均F1が0.8766(ワンホットは0.8475)でした。
なぜこの問題か
建築・エンジニアリング・建設・運用を含むAECO分野でAIを実務に活かすには、計画・設計・施工・運用に関わるプロジェクト情報を、機械が扱える形で表現し、学習できる状態にする必要があります。論文では、プロジェクト管理にとって重要な概念群をまとめて「建物セマンティクス」と呼び、これをAIに理解させること自体が意思決定支援の土台になると位置づけています。既存研究は、現場写真、点群、BIMグラフ、テキストなど「対象物をどう表すか」に多く注力してきましたが、教師あり学習でクラスを区別するための「エンコーディング(符号化)」の選択は見落とされやすいと述べています。慣習的に使われるワンホットやラベル符号化は、全カテゴリを等距離として扱うため、互いに近いサブタイプ間の類似・差異を表しにくいです。結果として、モデルが「似ているが違う」概念を学ぶ際の手掛かりが弱くなり、意味の取り込みが限定されます。一方で、大規模言語モデル(LLM)が作る埋め込みは、AECOでも意味的に近い情報を検索する用途で有効性が示されてきましたが、学習時のクラス符号として用い、学習過程に文脈的なニュアンスを持ち込む試みは十分に検討されていないと整理されています。…
核心:何を提案したのか
提案の中心は、教師あり学習で用いるクラスの符号化を、ワンホットではなくLLM埋め込みに置き換える「LLM encoding(LLM符号化)」です。対象は一般的な建物オブジェクト種別にとどまらず、より細分化されたサブタイプまで含む建物セマンティクスであり、近縁なサブタイプ同士の関係性を学習中にできるだけ保つことを狙っています。具体的には、クラス名(サブタイプ名)を入力として、OpenAI GPT系やMeta LLaMA系などが生成する高次元ベクトルを得て、それを教師信号として扱います。これにより、クラス同士の相対的な近さ・遠さをベクトル空間の距離として持ち込み、「正解だけを1にする」表現では落ちやすい意味の差分を学習に反映させます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related