自己疑念と回復を伴うメタ認知的強化学習
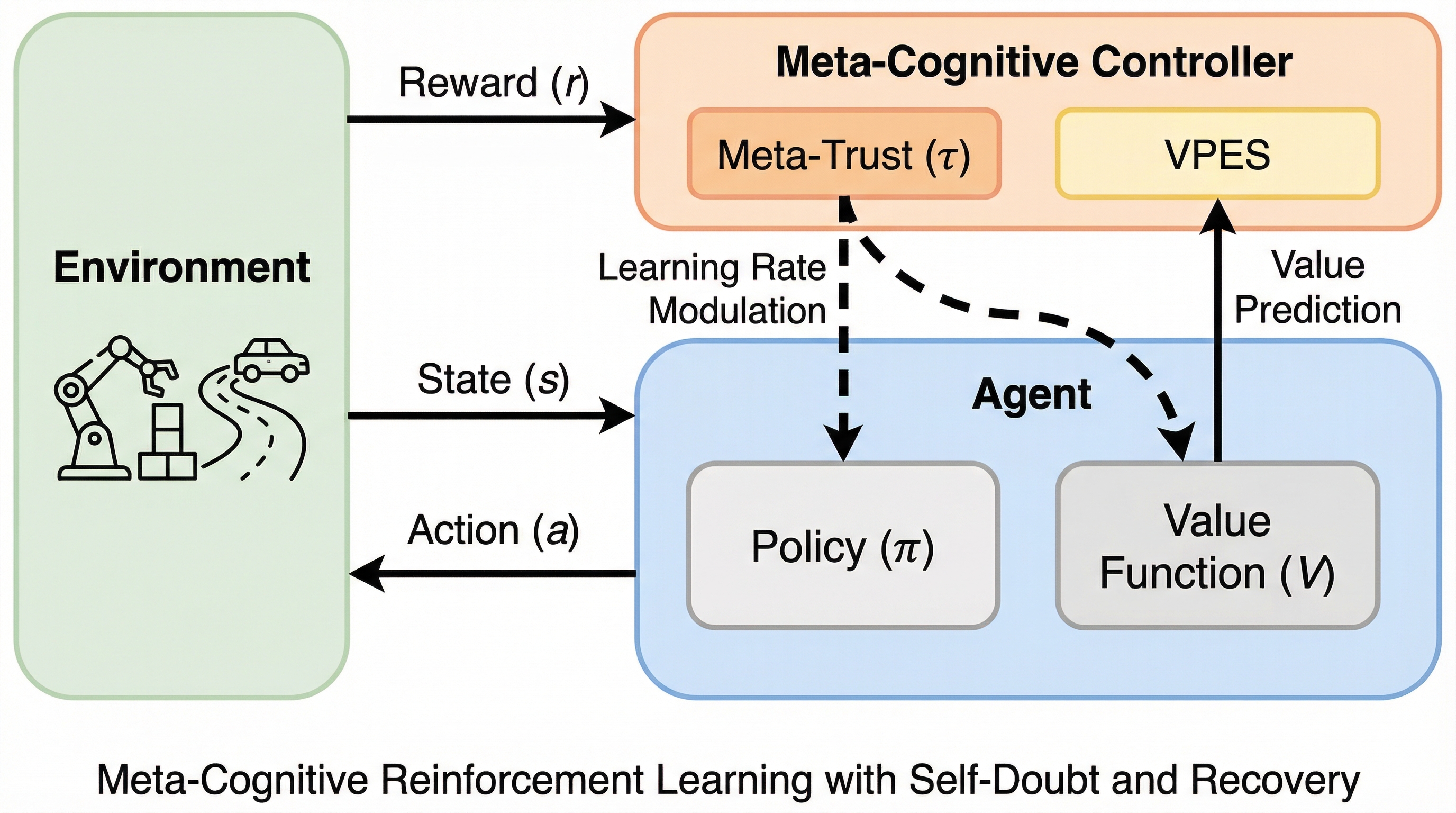
従来の強化学習は外部のノイズ除去に注力する一方で、自身の学習プロセスが健全であるかを判断する能力を欠いており、不確実性が蓄積すると訓練終盤に突如として性能が崩壊する致命的な問題を抱えていた。 本研究は、価値予測誤差の安定性(VPES)を指標として自身の学習状態を監視し、不安定な時には学習を抑制しつつ安定後に段階的に信頼を回復させる「メタ認知型強化学習フレームワーク」を提案し、学習の「許容性」を自律制御する仕組みを構築した。 報酬に激しいノイズがある過酷な環境での検証において、提案手法は学習終盤の崩壊率を既存の最新手法と比較して50%削減し、平均リターンを2倍以上に向上させるなど、実世界での運用に耐えうる極めて高い堅牢性と回復力を実証した。