Spark: 長期タスクにおけるエージェント学習のための動的探索フレームワーク
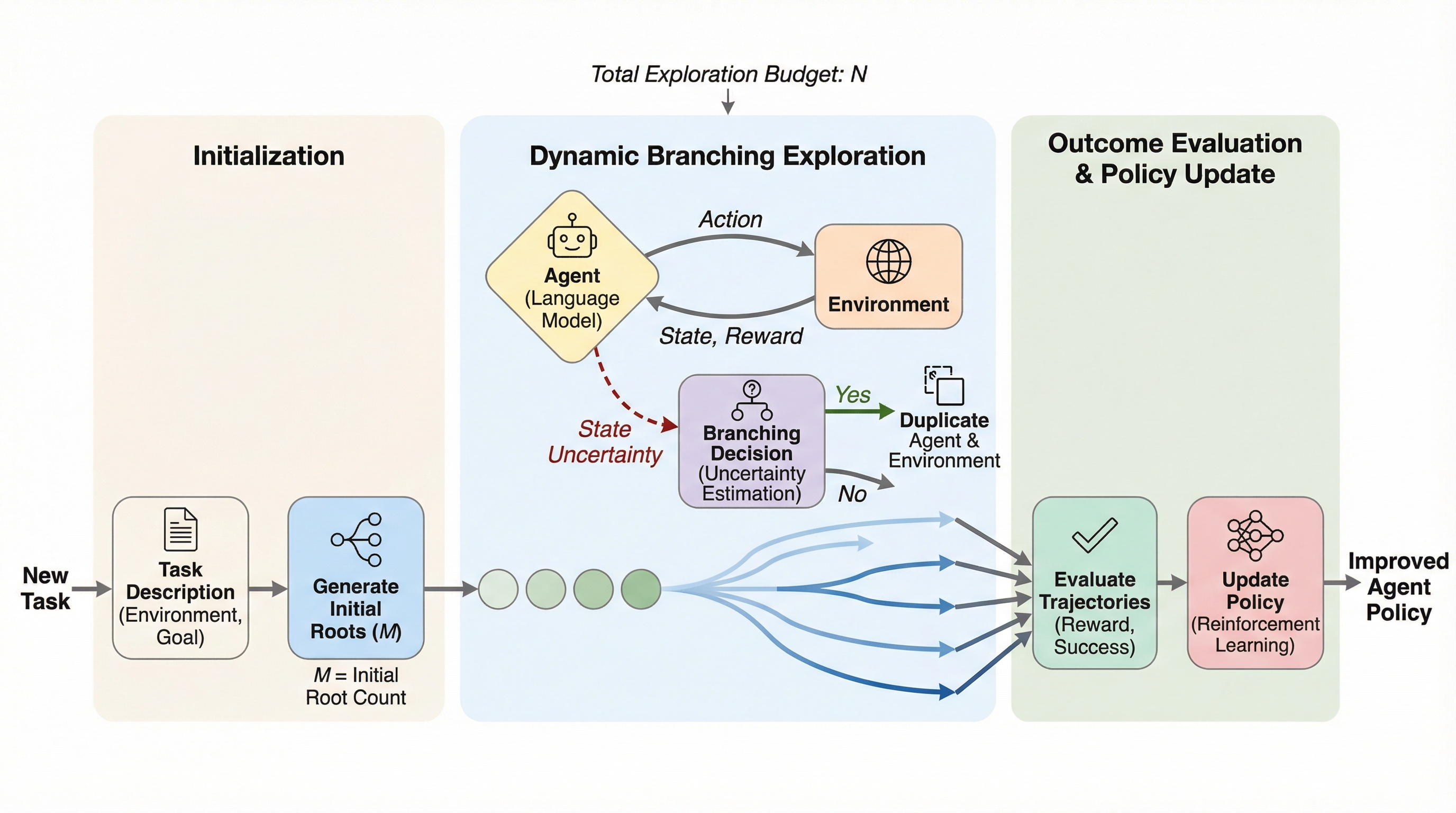
長期的なタスクを実行するAIエージェントの強化学習において、全ステップに一律の計算資源を配分する従来手法の非効率性を解消するため、重要な決定局面でのみ探索を分岐させる新フレームワーク「SPARK」が提案されました。
TL;DR(結論)
長期的なタスクを実行するAIエージェントの強化学習において、全ステップに一律の計算資源を配分する従来手法の非効率性を解消するため、重要な決定局面でのみ探索を分岐させる新フレームワーク「SPARK」が提案されました。 エージェント自身の内部信号に基づき、認識論的な不確実性が高い「SPARKポイント」を自律的に特定して動的な分岐探索を行うことで、限られたリソース下で高品質な学習軌跡を効率的に生成し、サンプルの質を劇的に向上させることに成功しています。 実験では、ALFWorldやScienceWorld等の難関ベンチマークにおいて、1.5Bという小規模モデルながらGPT-5等の巨大モデルを凌駕する成功率を達成し、わずか20%の学習データで従来手法を超える極めて高い学習効率と汎化性能を実証しました。
なぜこの問題か
強化学習(RL)は、大規模言語モデル(LLM)の推論能力を向上させる上で極めて有効な手段であることが、数学やコーディングといった特定のドメインで証明されてきました。しかし、動的な環境を自律的にナビゲートし、複雑で長期的な指示を実行する「エージェント型AI」への応用には、依然として大きな障壁が存在します。その根本的なボトルネックは、リソース制約下で高品質な学習軌跡(サクセス・トレース)を確保することが極めて困難であるという点にあります。数学の問題とは異なり、エージェントが取り組むタスクは広大な状態空間を探索する必要があり、一箇所の判断ミスが長い一連のシーケンス全体を台無しにする可能性があります。そのため、成功に至る軌跡は非常に稀少であり、方策を効果的に学習させることが困難です。 既存の手法は、探索の予算を拡大したり、強化学習のトレーニング中に広範な探索技術を用いたりすることで、この課題を緩和しようとしてきました。しかし、これらのアプローチは計算資源の「無差別な配分」という致命的な問題を抱えています。具体的には、従来の手法はすべてのステップに対して一律に計算予算を分配してしまいます。…
核心:何を提案したのか
本論文では、重要な中間状態において動的な分岐を行うことで、自律的かつ戦略的な探索を可能にする新しいフレームワーク「SPARK(Strategic Policy-Aware exploRation via Key-state dynamic branching)」を提案しています。この手法の核心的な洞察は、エージェント自身の「内部的な意思決定信号」を利用して探索のトポロジー(構造)を制御するという点にあります。SPARKは、エージェントが認識論的な不確実性や意味的な曖昧さに直面した際に、選択的に追加の探索分岐を開始します。一方で、日常的で定型的な決定局面では、分岐を行わずに直線的に処理を進めます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related