拡散モデルの調整コストを激減させる「DeRaDiff」:サンプリング時の動的な正則化制御
拡散モデルを人間の好みに適合させるアライメント工程において、事前学習モデルからの乖離を抑える正則化強度($\beta$)の選択は、画質と忠実度のバランスを左右する極めて重要な課題ですが、最適な値を見つけるための再学習には膨大な計算コストがかかっていました。
TL;DR(結論)
拡散モデルを人間の好みに適合させるアライメント工程において、事前学習モデルからの乖離を抑える正則化強度($\beta$)の選択は、画質と忠実度のバランスを左右する極めて重要な課題ですが、最適な値を見つけるための再学習には膨大な計算コストがかかっていました。 本研究が提案する「DeRaDiff」は、一度だけアライメントを行ったモデルを基点(アンカー)とし、推論時のサンプリング過程において参照モデルと幾何学的に混合することで、追加学習を一切行わずに正則化強度を動的に制御することを可能にする革新的な手法です。 実験ではSDXL等の大規模モデルを用い、異なる強度でゼロから再学習したモデルの出力を極めて高い精度で近似できることが示され、計算資源を大幅に節約しながら、人間の好みに基づく最適な画像品質とプロンプトへの忠実度を即座に探索・調整できるようになりました。
なぜこの問題か
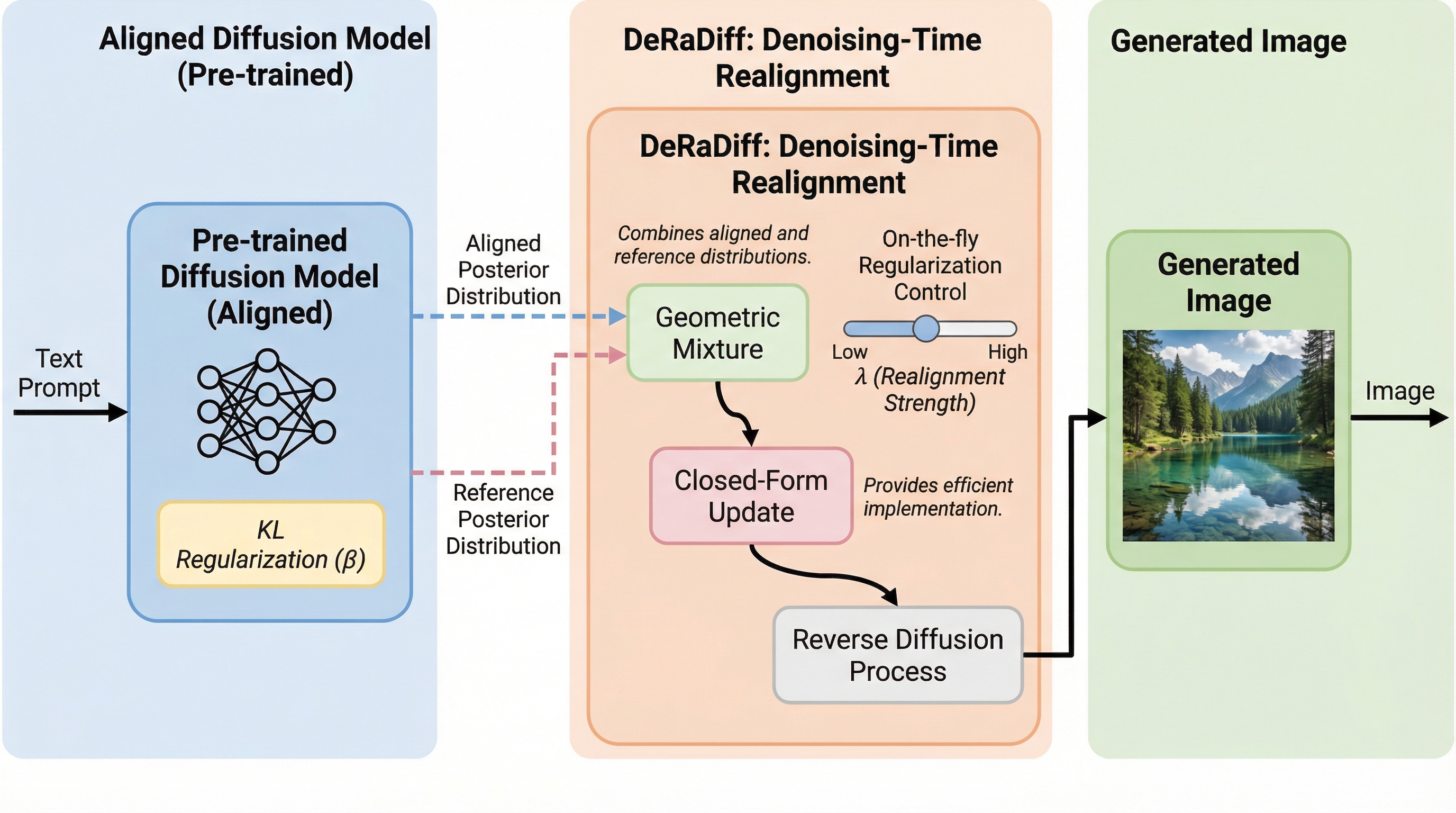
テキストから画像を生成する拡散モデルは、現代の画像生成技術の基盤となっていますが、その構築には二つの重要な段階があります。第一段階は大規模データを用いた事前学習であり、第二段階は特定のタスクや人間の好みに合わせてモデルの振る舞いを修正する「アライメント」です。このアライメント工程では、モデルを人間の好みに近づけつつも、事前学習で得た知識や元の分布から離れすぎないように制御する必要があります。このバランスを調整するために一般的に用いられるのが、KLダイバージェンス(Kullback–Leibler divergence)による正則化です。 ここで設定される正則化の強度($\beta$)は、生成される画像の品質を決定づける極めて重要なハイパーパラメータです。正則化が強すぎると、モデルは人間の好みに十分に適合できず、アライメントの効果が限定的になってしまいます。一方で、正則化が弱すぎると、モデルは本来の画像生成能力を損ない、報酬スコアだけを不当に高く得ようとする「報酬ハッキング」と呼ばれる現象を引き起こします。その結果、生成画像に不自然なアーティファクトが生じたり、視覚的な破綻を招いたりするリスクが高まります。…
核心:何を提案したのか
本研究では、拡散モデルのデノイジング(ノイズ除去)工程において、動的にアライメントの強さを再調整する手法「DeRaDiff(Denoising-Time Realignment of Diffusion Models)」を提案しています。この手法の最大の特徴は、一度だけ特定の正則化強度でアライメントを完了させたモデル(アンカーモデル)を用意すれば、それ以降は追加の学習や微調整を一切行うことなく、推論時(サンプリング時)に異なる正則化強度で学習したかのような効果を擬似的に再現できる点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related