自己疑念と回復を伴うメタ認知的強化学習
従来の強化学習は外部のノイズ除去に注力する一方で、自身の学習プロセスが健全であるかを判断する能力を欠いており、不確実性が蓄積すると訓練終盤に突如として性能が崩壊する致命的な問題を抱えていた。 本研究は、価値予測誤差の安定性(VPES)を指標として自身の学習状態を監視し、不安定な時には学習を抑制しつつ安定後に段階的に信頼を回復させる「メタ認知型強化学習フレームワーク」を提案し、学習の「許容性」を自律制御する仕組みを構築した。 報酬に激しいノイズがある過酷な環境での検証において、提案手法は学習終盤の崩壊率を既存の最新手法と比較して50%削減し、平均リターンを2倍以上に向上させるなど、実世界での運用に耐えうる極めて高い堅牢性と回復力を実証した。
TL;DR(結論)
従来の強化学習は外部のノイズ除去に注力する一方で、自身の学習プロセスが健全であるかを判断する能力を欠いており、不確実性が蓄積すると訓練終盤に突如として性能が崩壊する致命的な問題を抱えていた。 本研究は、価値予測誤差の安定性(VPES)を指標として自身の学習状態を監視し、不安定な時には学習を抑制しつつ安定後に段階的に信頼を回復させる「メタ認知型強化学習フレームワーク」を提案し、学習の「許容性」を自律制御する仕組みを構築した。 報酬に激しいノイズがある過酷な環境での検証において、提案手法は学習終盤の崩壊率を既存の最新手法と比較して50%削減し、平均リターンを2倍以上に向上させるなど、実世界での運用に耐えうる極めて高い堅牢性と回復力を実証した。
なぜこの問題か
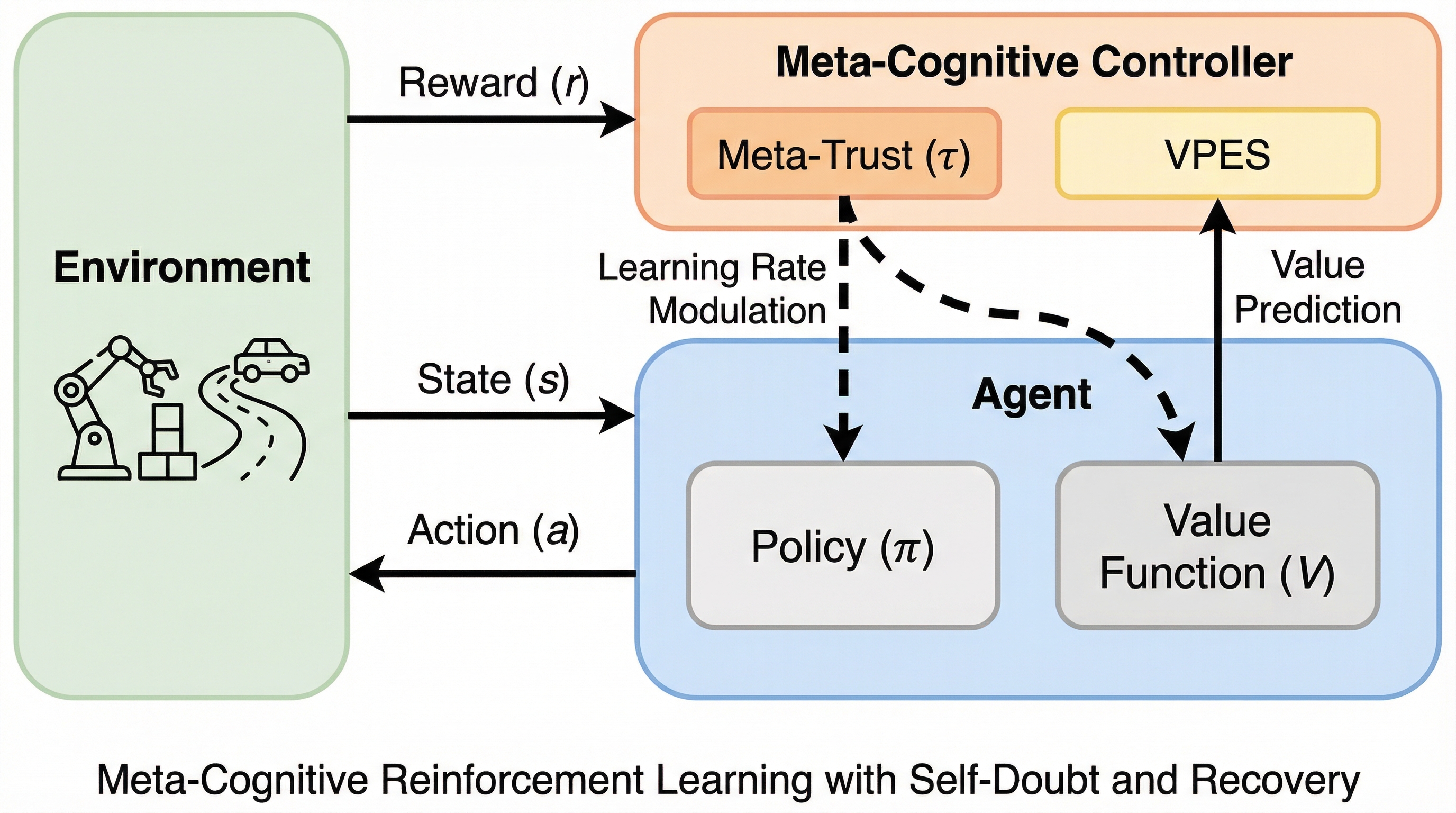
堅牢な強化学習手法は、通常、信頼性の低い経験や汚染された報酬の抑制に焦点を当てているが、自身の学習プロセスの信頼性について推論する能力を欠いている。その結果、これらの手法はノイズに対して過度に保守的になることで過剰反応するか、あるいは不確実性が蓄積した際に壊滅的な失敗を招くことが多い。本研究では、内部で推定された信頼性信号に基づいて、エージェントが自身の学習行動を評価、調整、および回復することを可能にするメタ認知的強化学習フレームワークを提案する。提案手法は、価値予測誤差安定性によって駆動されるメタ信頼変数を導入し、フェイルセーフ調整と段階的な信頼回復を通じて学習ダイナミクスを制御する。報酬汚染を伴う連続制御ベンチマークでの実験により、回復機能を備えたメタ認知的制御は、強力な堅牢性ベースラインと比較して、より高い平均リターンを達成し、学習終盤の失敗を大幅に減少させることが示された。 現実世界の複雑な環境に強化学習システムを導入する際、信頼性の低いフィードバックや非定常な環境変化、そして学習プロセス自体の不安定さが大きな障壁となっている。…
核心:何を提案したのか
本論文の核心的な提案は、エージェントが内部的に推定した信頼性信号に基づいて、自身の学習行動を自律的に評価、調整、および回復させる「メタ認知型強化学習フレームワーク」である。このフレームワークの最大の特徴は、特定のアルゴリズムに依存せず、既存の多くのアクター・クリティック手法に後付け可能な監視制御ループとして設計されている点にある。具体的には、学習プロセスの健全性を表す「メタ信頼(Meta-Trust)」という内部変数を導入し、これを「価値予測誤差安定性(VPES)」という独自の指標によって駆動させる。このメタ信頼は、現在の学習ダイナミクスに対するエージェント自身の「自信」を数値化したものであり、この値に応じて実効的な学習率を動的にスケーリングする。特に重要なのは、認知科学の知見を取り入れた非対称な更新ルールである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related