マルチモーダルRAGプライバシーの体系的な評価
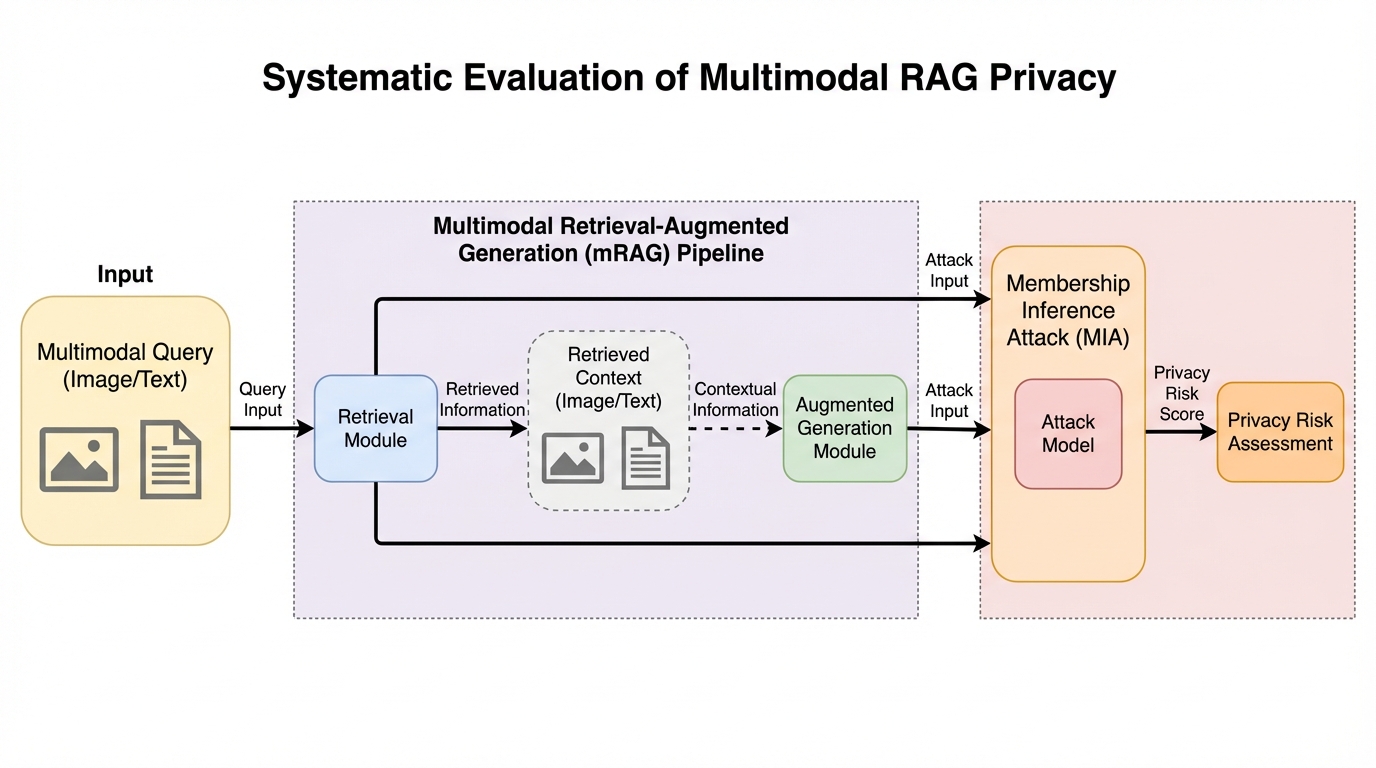
マルチモーダル検索拡張生成(mRAG)システムは、外部データベースの画像を参照して回答精度を高める一方で、特定の画像がデータベースに含まれているかを特定するメンバーシップ推論攻撃(MIA)や、画像に付随する機密テキストを抽出する画像キャプション取得(ICR)攻撃に対して極めて脆弱であることが本研究の体系的な評価によって明らかになりました。 実験の結果、データベース内の画像が回転、クロップ、ノイズ付加などの加工を受けている現実的な条件下でも、攻撃者は高い精度で情報の有無を判定可能であり、特に視覚的に特徴が明確なデータセットでは機密性の高いメタデータが逐語的に漏洩するリスクが実証されました。 この脆弱性は、プロンプト内での画像の配置順序やリランカーの設定によって変動し、入力画像を検索結果の前に配置することで漏洩を抑制できる可能性が示唆されましたが、依然として根本的な保護メカニズムの欠如が大きな課題として残っており、今後の安全なシステム開発に向けた重要な知見を提供しています。