DIML:マルチエージェント学習軌跡の振る舞いからの微分可能な逆メカニズム学習
本研究は、複数のエージェントが相互に影響し合う環境において、観測された行動履歴(学習軌跡)のみから背後にある未知の報酬生成メカニズムを特定する「逆メカニズム学習」のフレームワーク「DIML」を提案する。
TL;DR(結論)
本研究は、複数のエージェントが相互に影響し合う環境において、観測された行動履歴(学習軌跡)のみから背後にある未知の報酬生成メカニズムを特定する「逆メカニズム学習」のフレームワーク「DIML」を提案する。 DIMLはエージェントの学習プロセスを微分可能なモデルとして扱い、実際には選択されなかった行動に対する「反事実的な報酬」を予測に組み込むことで、平衡状態ではない過渡的な学習行動からも報酬構造を高い精度で復元できる。 実験では、ニューラルネットワークで構成された複雑な報酬系や、交通渋滞の課金、公共財の補助金、100人規模の匿名ゲームなど多様な環境において、既存手法を凌駕する精度と大規模システムへのスケーラビリティを実証した。
なぜこの問題か
現代の社会技術システムにおいて、広告プラットフォームの掲載順位決定、交通機関の混雑料金、デジタル労働プラットフォームのボーナス制度など、多くの重要な意思決定は「メカニズム」と呼ばれる報酬生成ルールによって制御されている。しかし、これらのメカニズムは企業の機密であったり、複雑なアルゴリズムによって動的に学習されたりするため、外部からはその実態が不透明な「ブラックボックス」となっていることが多い。このようなシステムの公平性を監査したり、将来の行動を予測したりするためには、直接アクセスできないメカニズムを観測データから逆推計する技術が不可欠である。 既存の「逆ゲーム理論」や「マルチエージェント逆強化学習(MA-IRL)」は、この問題に対していくつかの限界を抱えている。まず、多くの手法はエージェントが既に最適な戦略に到達した「平衡状態」にあることを前提としているが、現実のデータは学習途中の過渡的な状態であることが多く、平衡状態のデータだけでは報酬構造を一意に特定できないという「識別可能性」の問題がある。…
核心:何を提案したのか
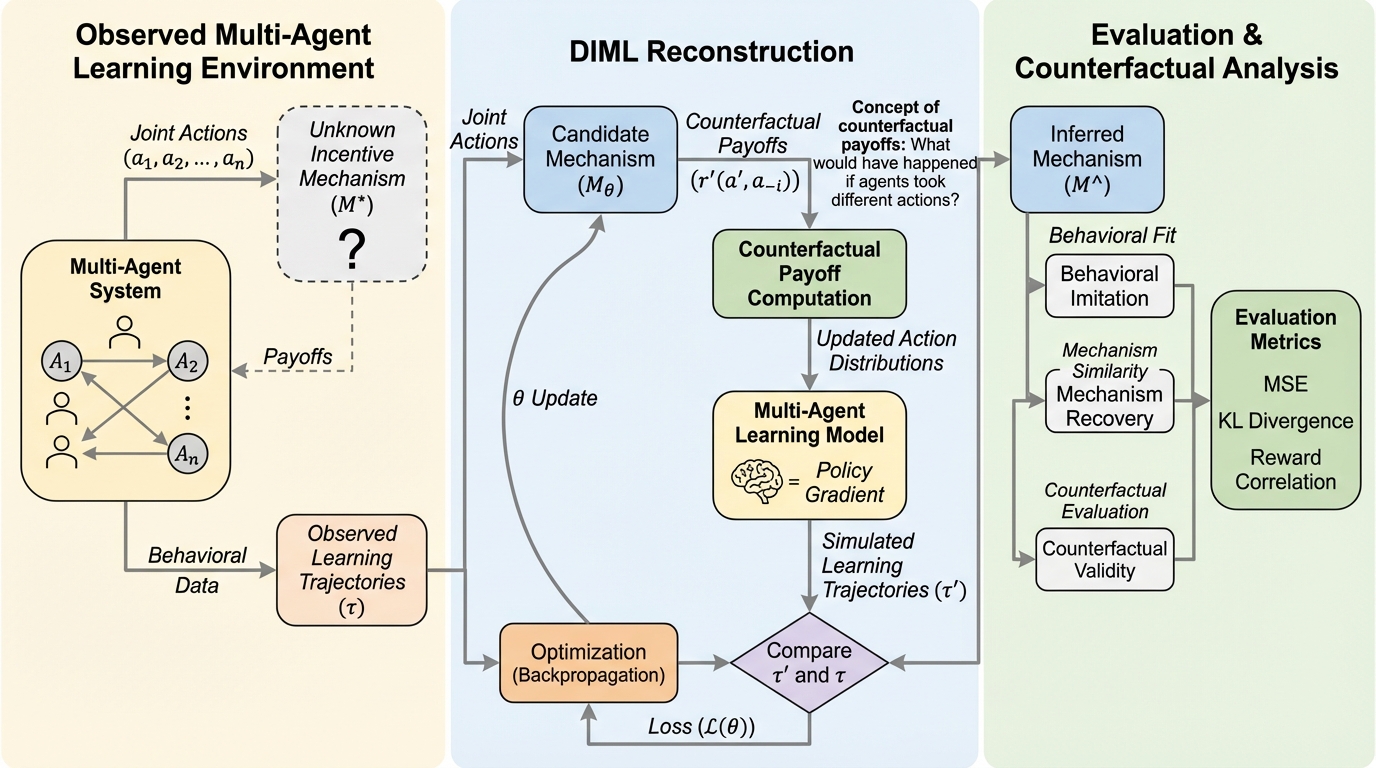
本研究の核心は、マルチエージェントの学習ダイナミクスを微分可能な計算グラフとして展開し、観測された行動軌跡から逆方向に報酬メカニズムを学習するフレームワーク「DIML(Differentiable Inverse Mechanism Learning)」を提案したことにある。DIMLは、未知のメカニズムをニューラルネットワークなどの表現力の高いモデルで近似し、そのパラメータを最尤推定によって最適化する。この際、単に「実際に選ばれた行動」に対する報酬を合わせるだけでなく、エージェントが学習の過程で参照する「選ばれなかった行動に対する報酬」も含めて一貫性のある説明ができるメカニズムを探索する点が画期的である。 DIMLは、逆メカニズム学習を「エージェントの適応プロセスを最もよく説明できる報酬構造は何か」という問いに置き換える。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related