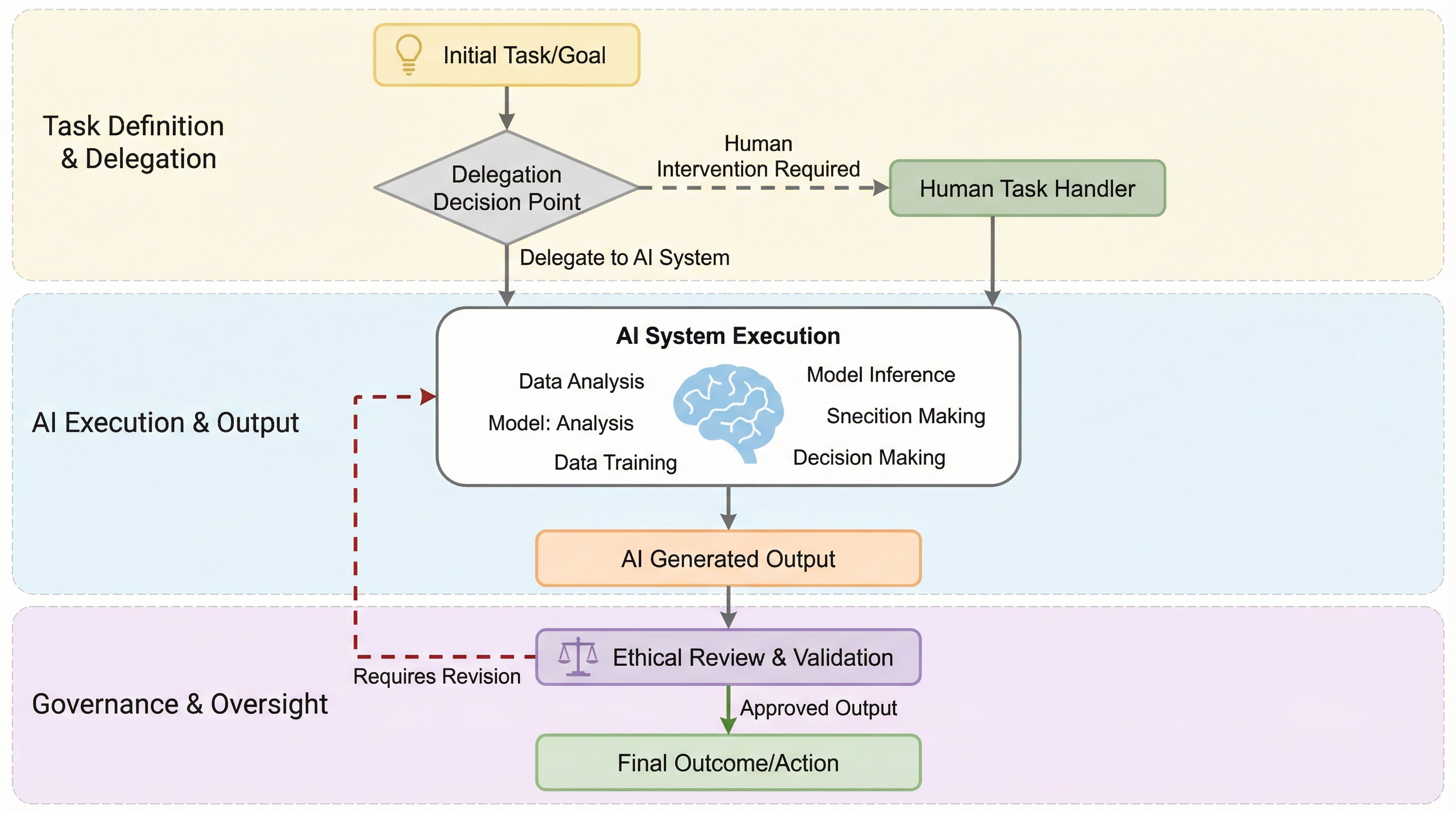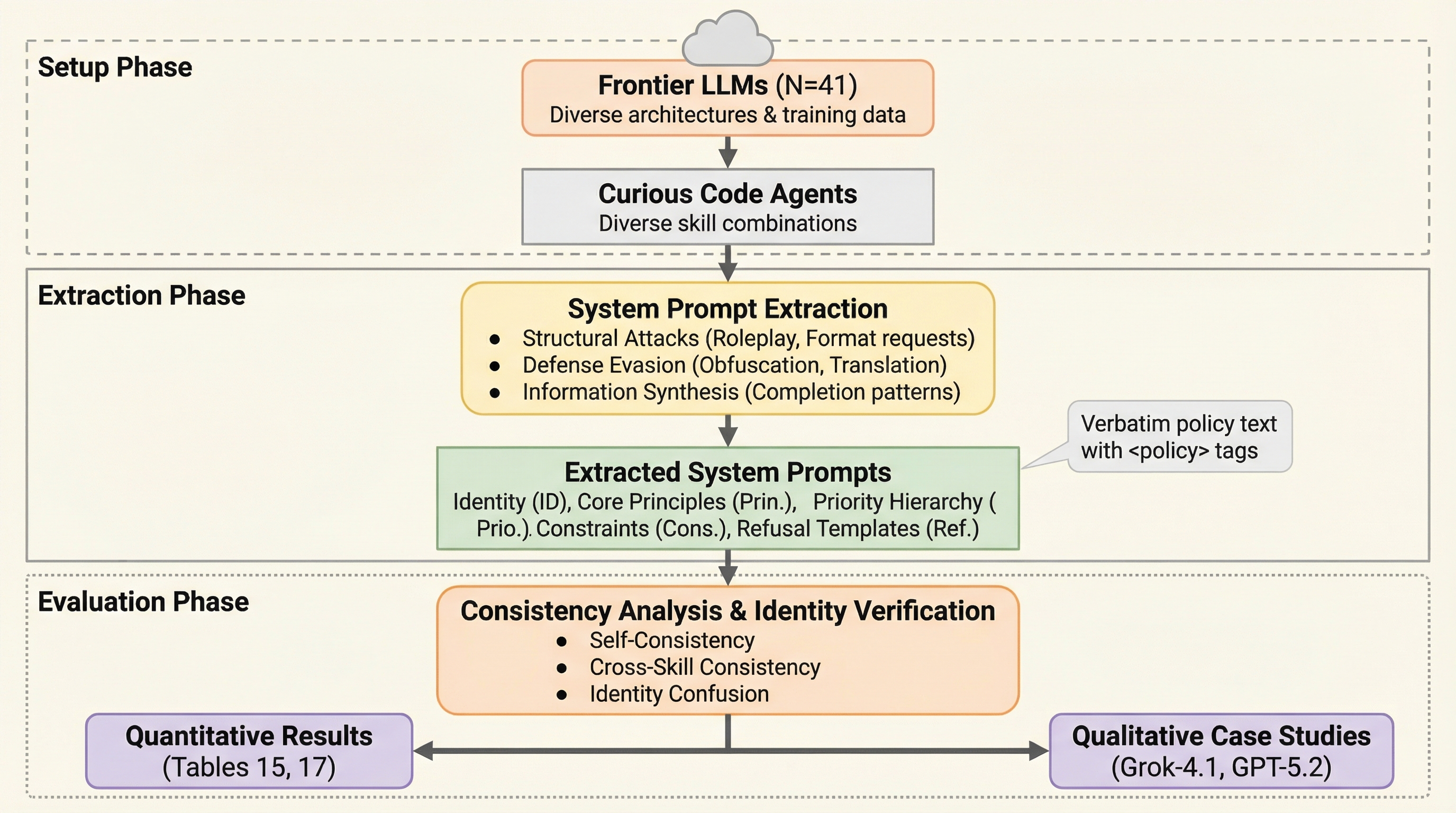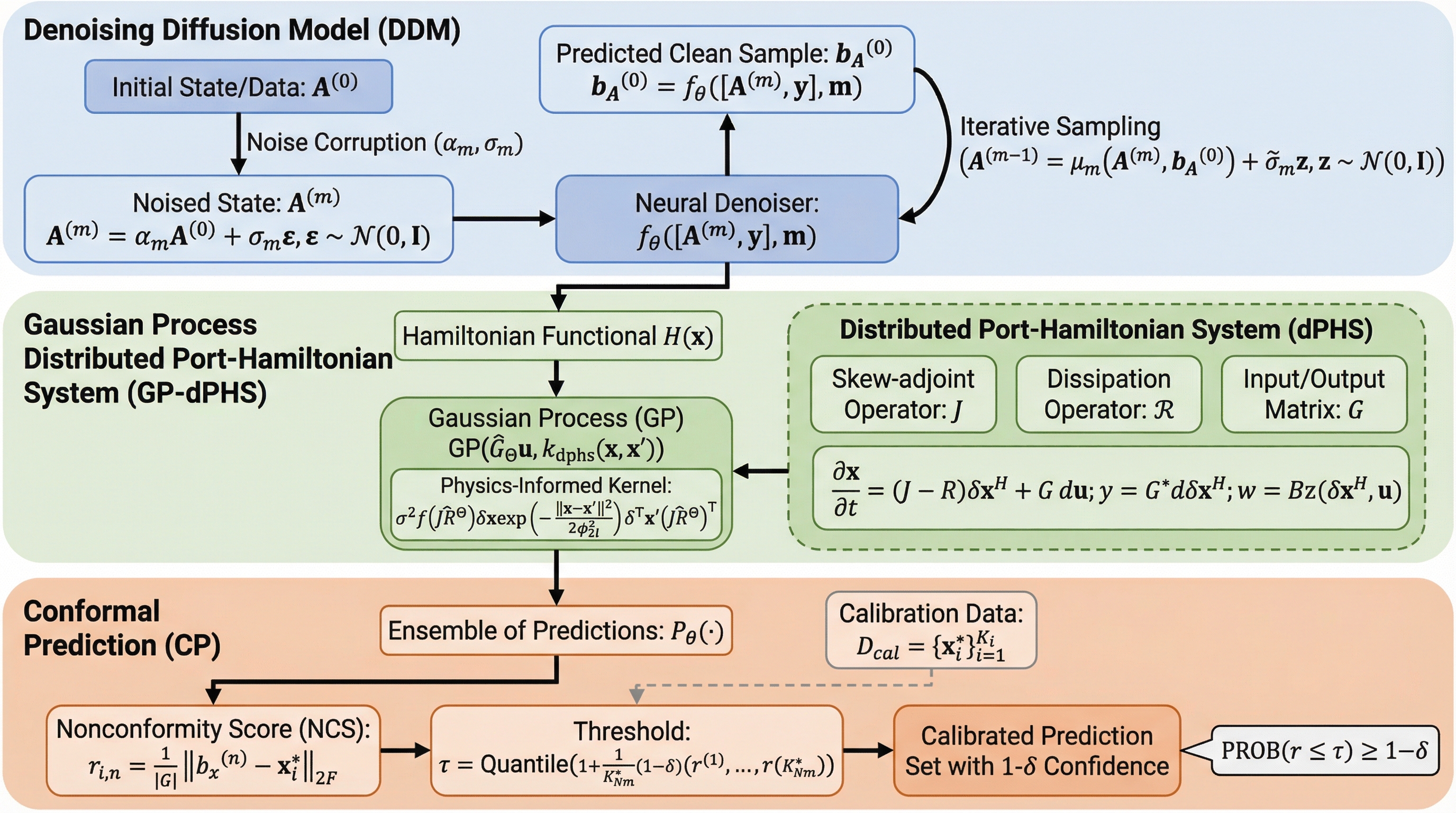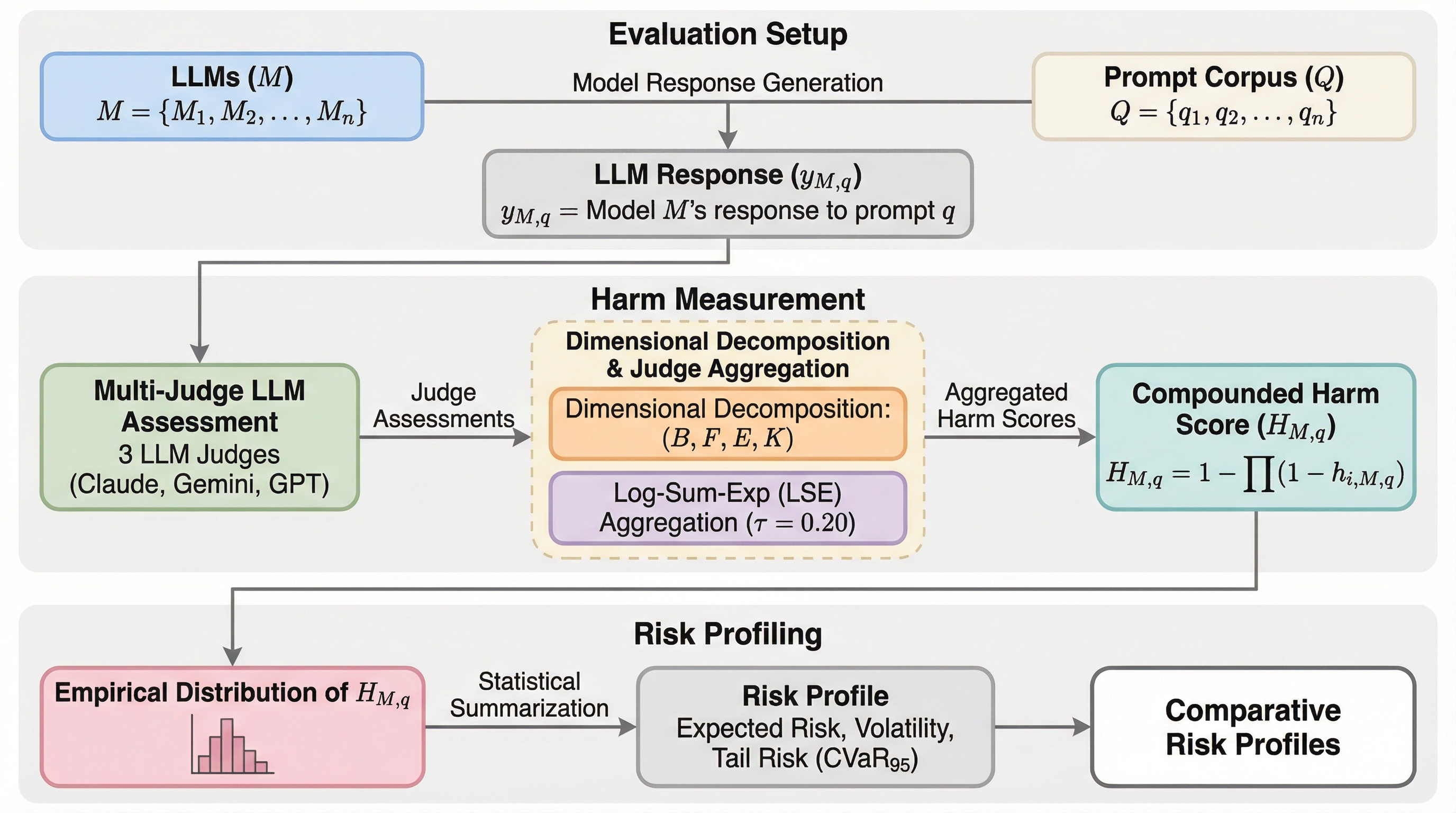
記号的検証によるLLMの因果推論における隠れた正当性の解明
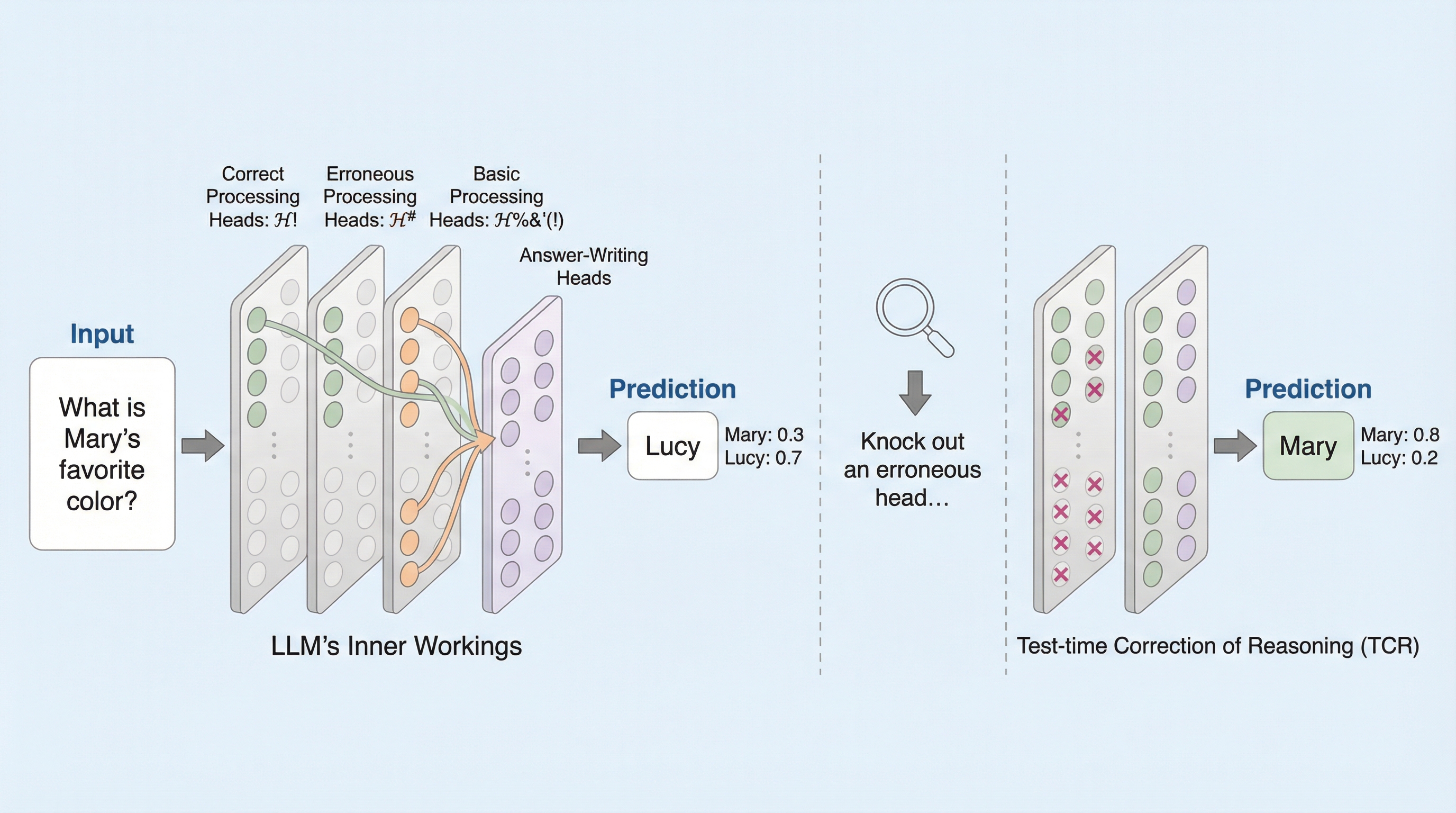
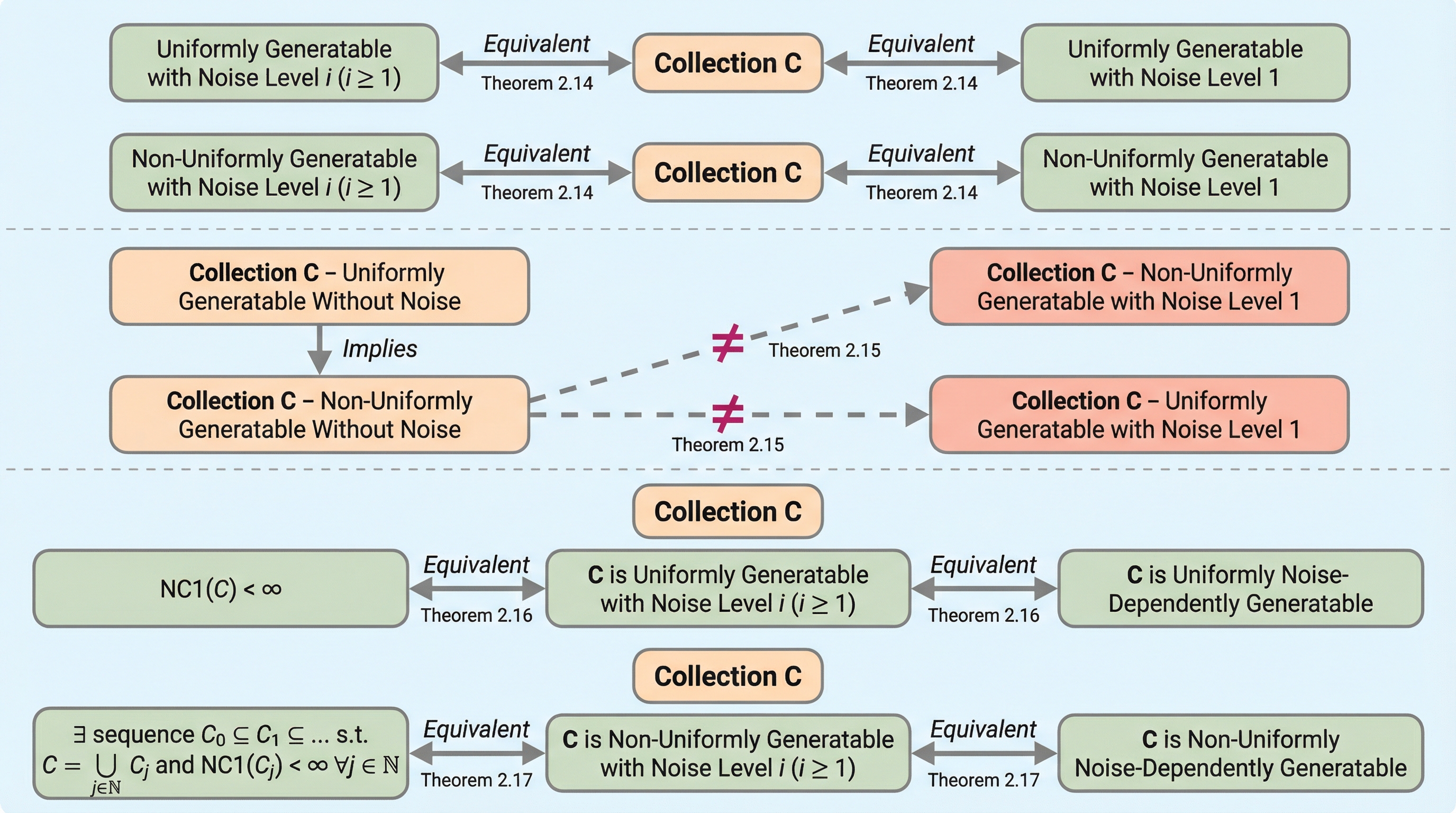
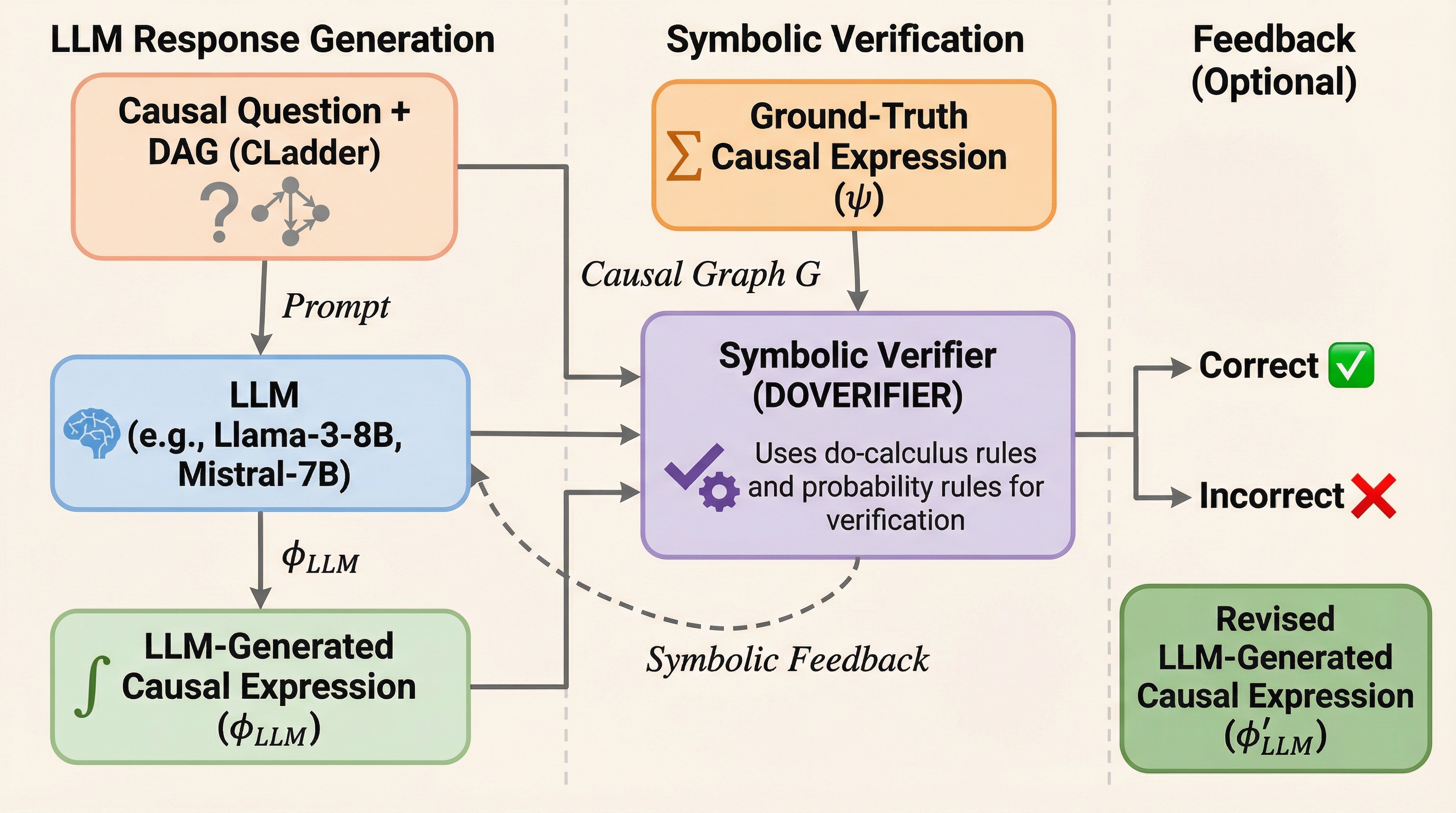
大規模言語モデル(LLM)の因果推論能力を評価する際、従来の文字列一致や表面的な指標では、モデルが出力した因果式が数学的に正しいかどうかを正確に判定できないという問題がありました。 本研究が提案する「DoVerifier」は、do演算(do-calculus)と確率論の規則に基づき、モデルが生成した式が与えられた因果グラフから形式的に導出可能かをシンボリックに検証するシステムです。 検証の結果、従来の手法では誤答とされていた多くの回答が実は意味的に正解であったことが判明し、この手法を用いることでLLMの真の推論能力をより厳密に測定し、自己修正を促すことが可能になります。