推論ホップのスケールアップが露呈させる弱点:大規模言語モデルにおけるホップ汎化の解明と改善
大規模言語モデル(LLM)は、学習時を超える推論ステップ(ホップ数)を要求されると、必要なスキルが同一であっても性能が急激に低下する「ホップ汎化」の課題を抱えており、本研究はその失敗が特定のトークン位置における「主要エラータイプ」に集中していることを突き止めました。
TL;DR(結論)
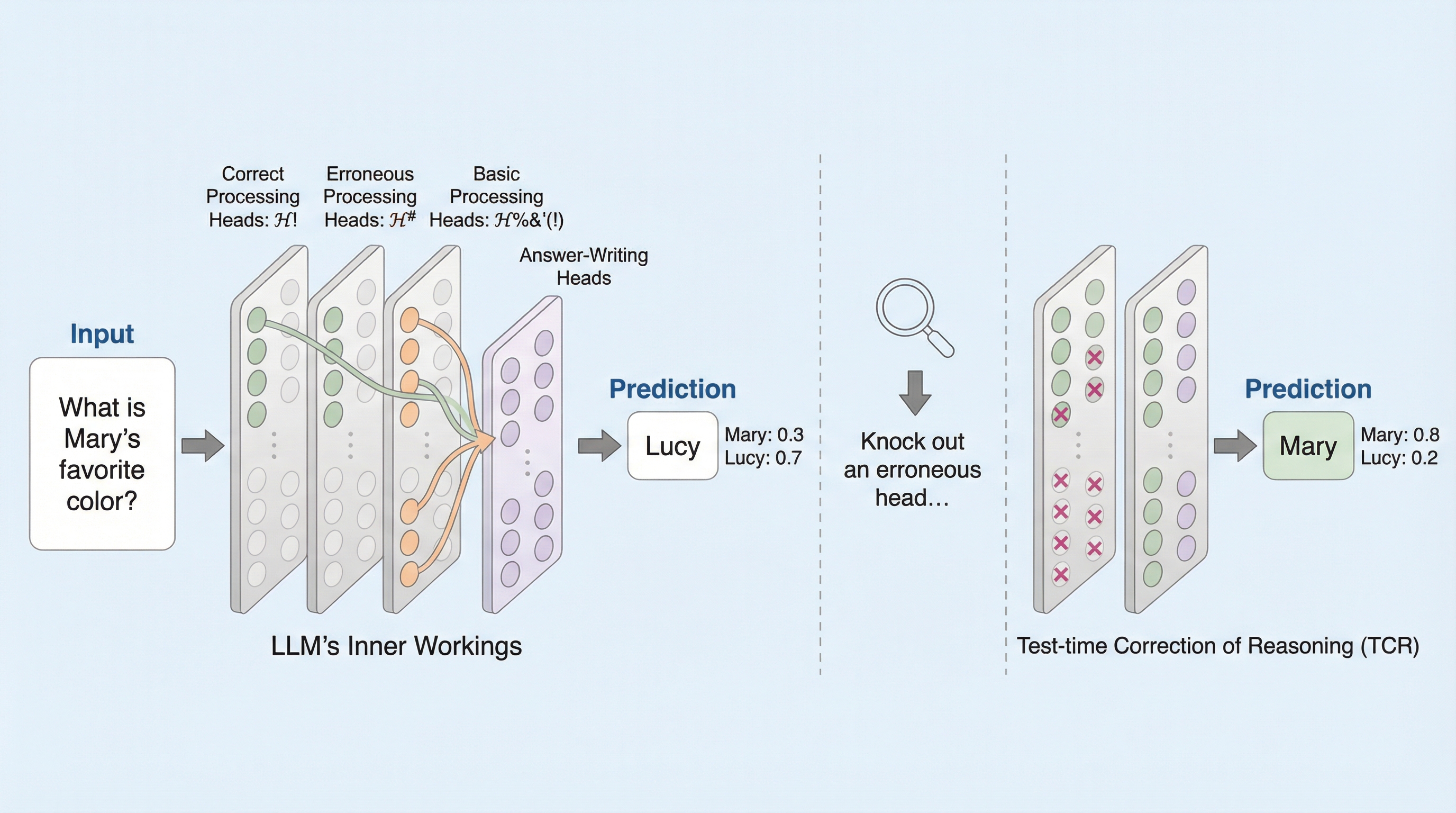
大規模言語モデル(LLM)は、学習時を超える推論ステップ(ホップ数)を要求されると、必要なスキルが同一であっても性能が急激に低下する「ホップ汎化」の課題を抱えており、本研究はその失敗が特定のトークン位置における「主要エラータイプ」に集中していることを突き止めました。 モデル内部では、正しい推論を導く信号と誤った推論を導く信号が常に競合しており、特定の「誤処理ヘッド(ep heads)」が正しい信号を抑制して誤答を増幅させているというメカニズムを解明し、このヘッドを特定して介入することで推論を修正できることを明らかにしました。 この知見に基づき、推論実行時に動的に特定のヘッドを無効化する軽量な介入手法「TCR(Test-time Correction of Reasoning)」を提案し、追加の学習を一切行うことなく、複数のタスクとモデルにおいて推論の正確性と堅牢性を大幅に向上させることに成功しました。
なぜこの問題か
Chain-of-thought(CoT)推論は、大規模言語モデル(LLM)が複雑な問題を段階的に解決するための標準的な手法として定着していますが、近年の研究により、推論に必要なステップ数(ホップ数)が訓練時の分布を超えると、モデルの性能が劇的に低下するという「ホップ汎化」の脆弱性が浮き彫りになりました。例えば、2桁同士の掛け算を完璧にこなせるモデルであっても、桁数が増えて推論ステップが長くなると、計算に必要な基本スキル自体は変わらないはずであるにもかかわらず、正解を導き出すことが困難になります。この問題は、単にシーケンス長がコンテキストウィンドウの制限に達するかどうかという物理的な制約の問題ではなく、推論の連鎖が長くなること自体が引き起こす、モデルの内部的な推論能力の限界を示す特有の現象です。 人間は、非常に長い推論ステップを必要とする問題に対しても、習得した基本的なルールやスキルを繰り返し応用することで堅牢に対応できますが、現在のLLMにはその汎化能力が著しく欠けていることが示唆されています。…
核心:何を提案したのか
本研究の核心は、ホップ汎化におけるエラーの発生源を特定し、その原因となる内部メカニズムを解明した上で、推論実行時にエラーを動的に修正する手法「TCR(Test-time Correction of Reasoning)」を提案したことにあります。まず、研究チームはエラーがランダムに発生するのではなく、タスクごとに特定のトークン位置や「主要エラータイプ」に集中していることを突き止めました。これにより、複雑な推論プロセスを少数の診断ポイントに集約して解析することが可能になりました。この発見は、モデルの失敗が予測不可能な混乱ではなく、構造的な弱点に基づいていることを示唆しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related