パラメータ知識がすべてではない:事前学習データの検索による誠実な大規模言語モデルに向けて
大規模言語モデル(LLM)が自身の知識の境界を認識できず、事実に基づかない回答を生成する「ハルシネーション」の問題を解決するため、事前学習データにアクセス可能な公開モデル「Pythia」を活用した新しい評価ベンチマーク「TIP-TRIVIAQA」が提案されました。
TL;DR(結論)
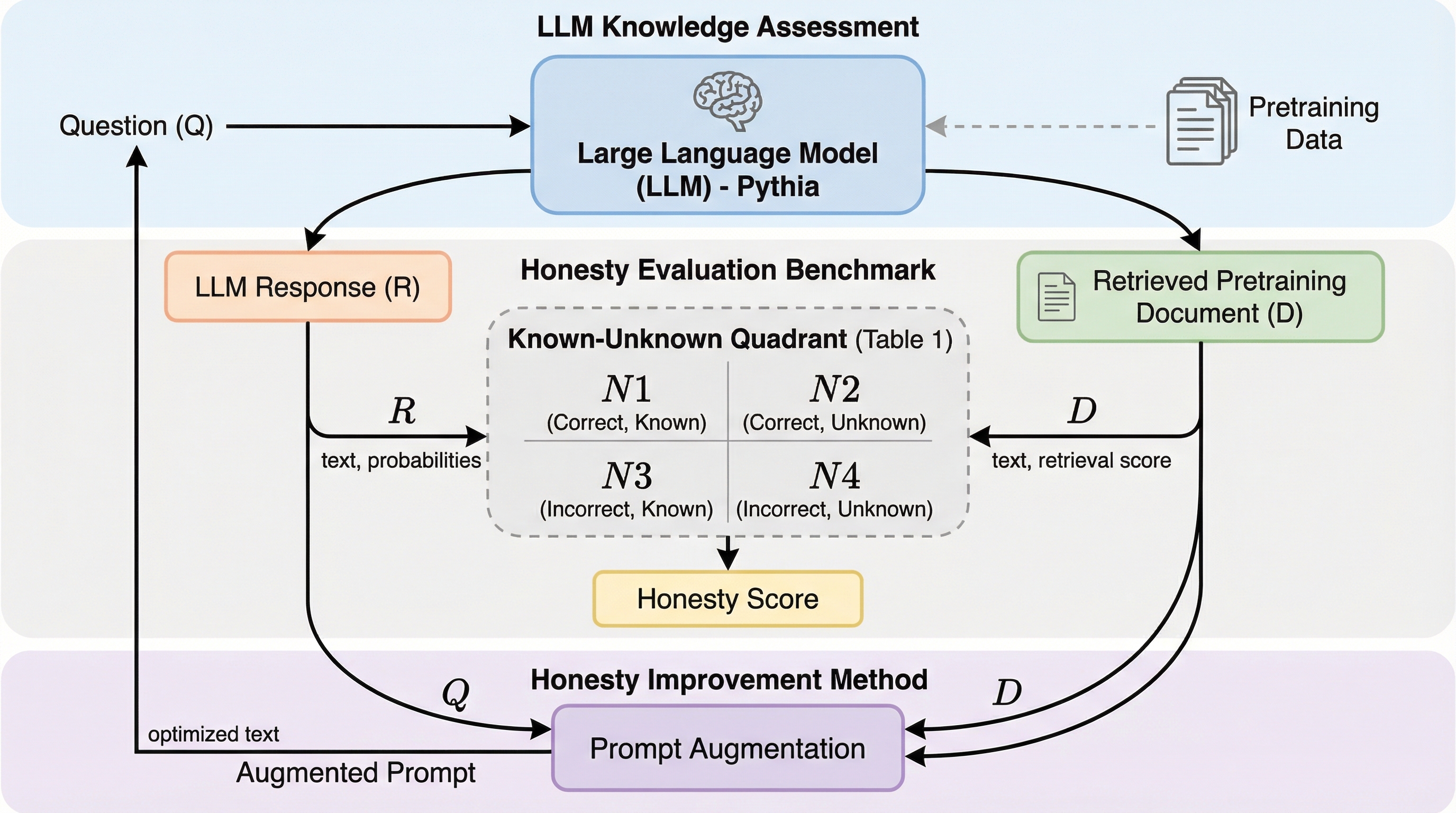
大規模言語モデル(LLM)が自身の知識の境界を認識できず、事実に基づかない回答を生成する「ハルシネーション」の問題を解決するため、事前学習データにアクセス可能な公開モデル「Pythia」を活用した新しい評価ベンチマーク「TIP-TRIVIAQA」が提案されました。この研究では、推論時にモデル自身の事前学習データを検索して回答の可否を判断する手法「RETAIN」を導入し、モデルが知らないことに対して「わかりません」と正直に答える能力と、知っていることに対して正確に答える能力の両方を大幅に向上させています。検証の結果、提案手法は既存の微調整手法や自己反省プロンプトを用いる手法と比較して、正確性と誠実さの指標であるExact MatchやF1スコアにおいて顕著に高いパフォーマンスを記録し、モデルの回答の根拠となる文書を特定できるため解釈性も向上することが示されました。
なぜこの問題か
大規模言語モデルは質問応答や要約、翻訳など多岐にわたるタスクで高い能力を発揮していますが、自分が何を知っていて何を知らないのかという「知識の境界」を自覚していないという重大な欠点があります。この知識の欠如が原因で、モデルは不正確な情報や捏造された内容をあたかも事実であるかのように生成してしまう「ハルシネーション」を引き起こし、特に医療や法律といった信頼性が極めて重要な分野での利用において大きな障壁となっています。信頼できるAIを実現するためには、モデルが自身の限界を認め、知識が不十分な場合には「わかりません」と回答する「誠実さ(Honesty)」が不可欠な特性であると考えられています。LLMの誠実さは、自身の知識の限界を知る「自己知識(Self-knowledge)」と、知っている情報を正しく出力する「自己表現(Self-expression)」の2つの側面で構成されます。 しかし、既存の誠実さを評価するための手法は、モデルが学習中にどのような文書に触れたかを考慮せずにブラックボックスとして扱うものが多く、評価の堅牢性に欠けていました。…
核心:何を提案したのか
本研究の核心は、モデルの事前学習データを活用して誠実さを向上させる新しいアプローチです。まず、完全に公開された事前学習データを持つLLMである「Pythia」を利用し、モデルが学習中に遭遇した情報に基づいて質問が「回答可能」か「回答不能」かを厳密に区分した新しいベンチマークデータセット「TIP-TRIVIAQA(Training-Information-Partitioned TriviaQA)」を提案しました。これにより、モデルが理論上知っているはずのことと、物理的に知らないことを明確に区別した評価が可能になります。このデータセットは、単なる難易度ベースの分類ではなく、モデルの「経験」に基づいた真の知識境界を反映している点が画期的です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related