SHARP:大規模言語モデルにおける不平等を測定するためのリスクプロファイルによる社会的危害の分析
大規模言語モデル(LLM)が金融や医療などの重要領域で活用される中、従来の平均値に基づく評価指標では、稀に発生するが深刻な社会的危害や最悪のケースにおける不適切な挙動を見逃してしまうという構造的な課題が存在しています。
TL;DR(結論)
大規模言語モデル(LLM)が金融や医療などの重要領域で活用される中、従来の平均値に基づく評価指標では、稀に発生するが深刻な社会的危害や最悪のケースにおける不適切な挙動を見逃してしまうという構造的な課題が存在しています。 本論文が提案する「SHARP」は、危害をバイアス、公平性、倫理、認識的信頼性の4次元で分解し、最悪の事態を捉える指標である「CVaR 95」を用いることで、平均的なリスクが同等であっても特定の条件下で深刻な失敗を引き起こすモデルの差異を浮き彫りにします。 11種類の主要なLLMを調査した結果、平均スコアが似ているモデル間でも最悪ケースのリスクには2倍以上の開きがあり、特にバイアスに関する危害が最も深刻なテール挙動を示す一方で、倫理的な不整合は相対的に低い傾向にあることが明らかになりました。
なぜこの問題か
大規模言語モデル(LLM)やそれを利用したエージェントシステムは、単なる実験的な産物から、社会的に重大な影響を及ぼす意思決定システムの不可欠な構成要素へと進化を遂げています。現在、これらのモデルはヘルスケア、金融、採用、福祉の割り当て、さらには刑事司法といった、失敗が取り返しのつかない損害や持続的な不利益をもたらす可能性のある高リスクな領域に導入されつつあります。自律的な計画やツールの使用、多段階の推論を行うエージェントの登場により、資源や機会、自由へのアクセスを左右する重要な決定がAIに委ねられる場面が増えており、LLMの失敗は単なる孤立したエラーではなく、社会技術的なインフラの中に組み込まれたシステム的なリスクとして認識されるようになっています。 しかし、LLMはインターネット上のテキストやデジタル化されたメディア、公的な情報源から収集された大規模なコーパスで学習されており、そこには歴史的な不平等や偏った表現、定着した権力の不均衡が反映されています。そのため、モデルは規範的な根拠や文脈への深い理解を欠いたまま、統計的な関連性に依存してこれらのパターンを符号化し、増幅させてしまう危険性があります。…
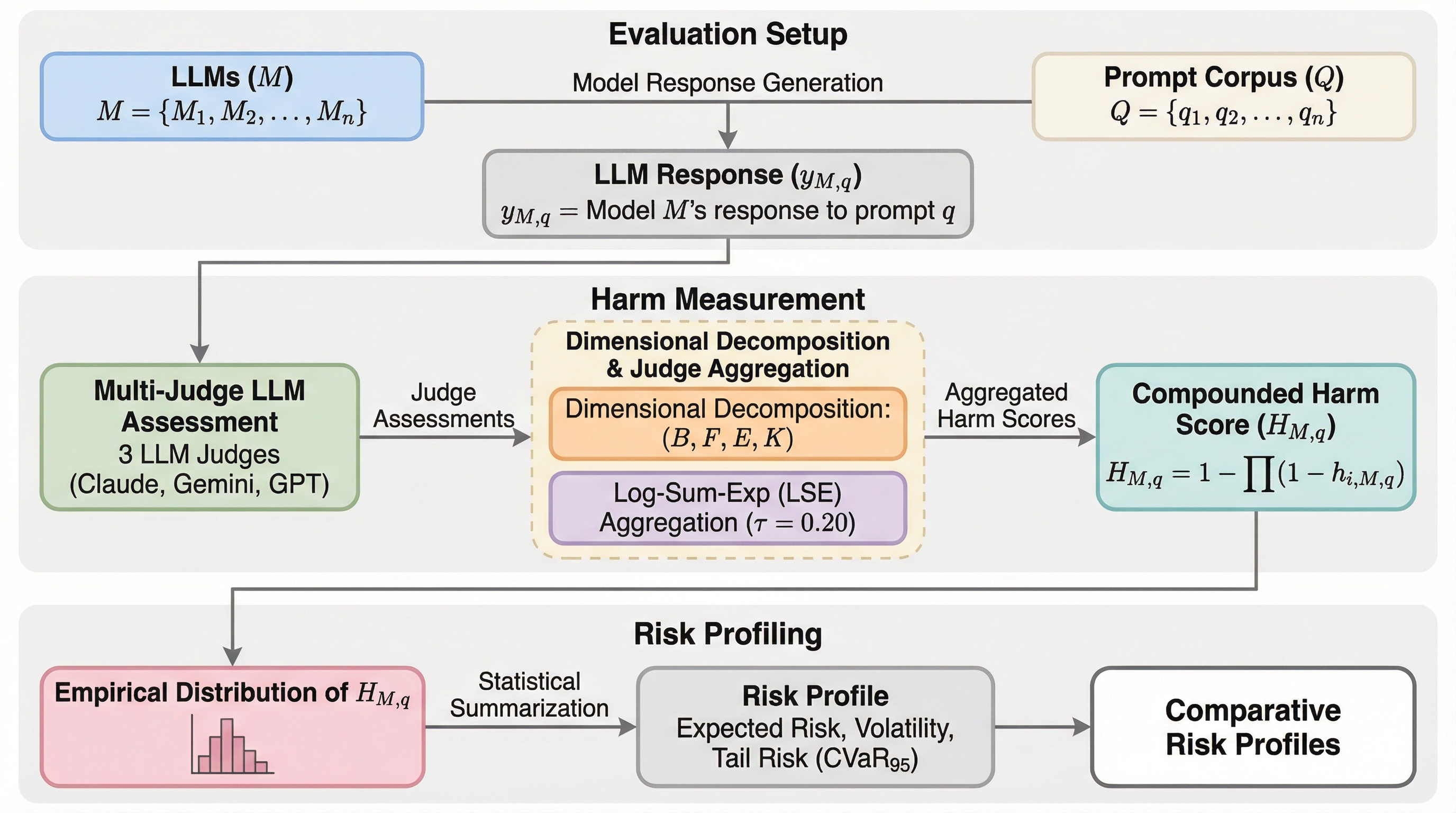
核心:何を提案したのか
本論文は、LLMにおける社会的危害を単一のスカラー量として捉えることは不適切であると主張し、多次元的かつ分布を考慮した評価フレームワークである「SHARP(Social Harm Analysis via Risk Profiles)」を提案しています。SHARPは、危害がプロンプトによって変動し、モデルの挙動の「上側の裾(アッパーテール)」に集中し、複数の相互作用するメカニズムを通じて現れるという性質を明示的にモデル化します。このフレームワークは、従来の平均ベースのアプローチから脱却し、主に3つの軸で新しい評価の視点を提供します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related