記号的検証によるLLMの因果推論における隠れた正当性の解明
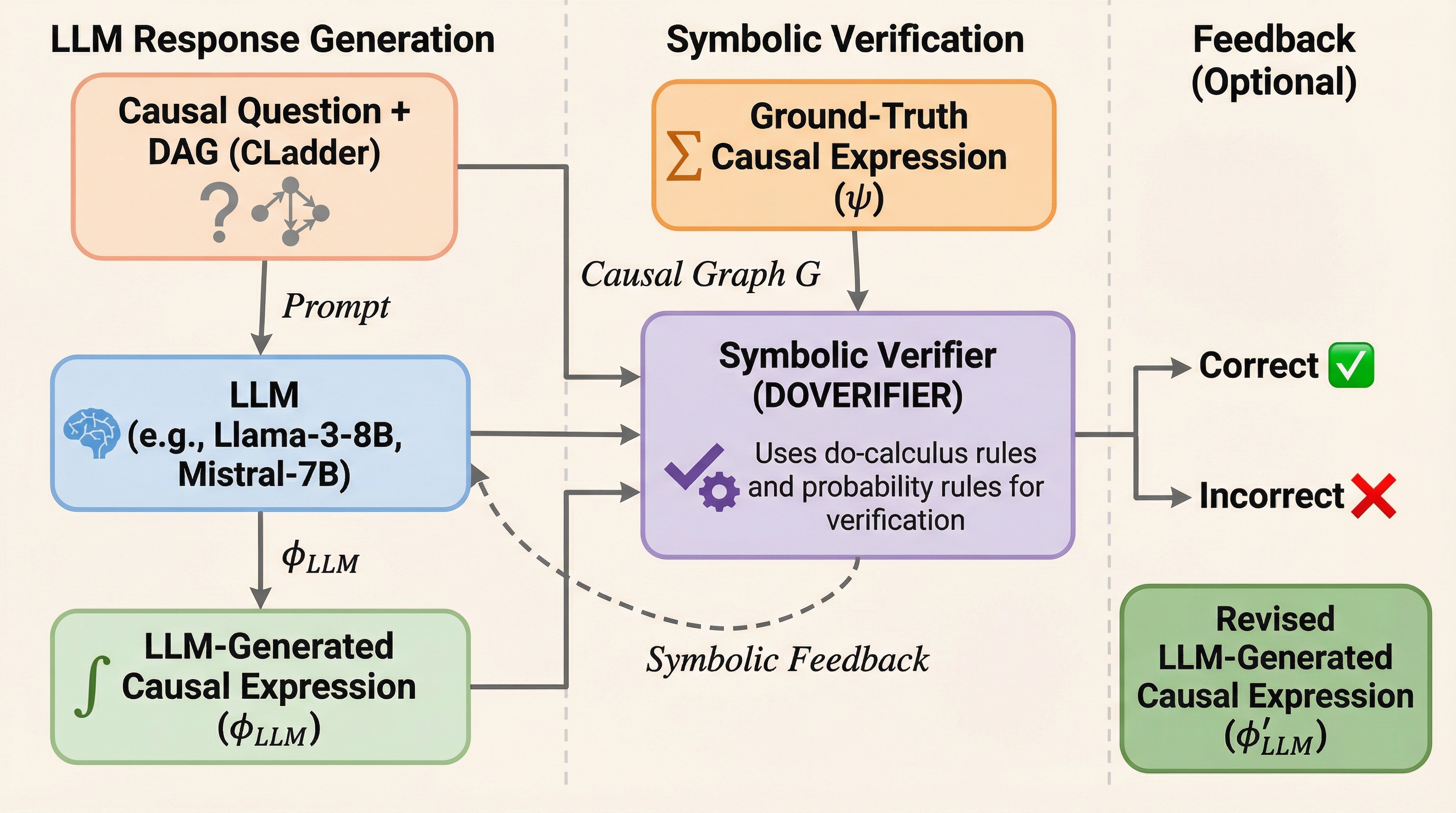
大規模言語モデル(LLM)の因果推論能力を評価する際、従来の文字列一致や表面的な指標では、モデルが出力した因果式が数学的に正しいかどうかを正確に判定できないという問題がありました。 本研究が提案する「DoVerifier」は、do演算(do-calculus)と確率論の規則に基づき、モデルが生成した式が与えられた因果グラフから形式的に導出可能かをシンボリックに検証するシステムです。 検証の結果、従来の手法では誤答とされていた多くの回答が実は意味的に正解であったことが判明し、この手法を用いることでLLMの真の推論能力をより厳密に測定し、自己修正を促すことが可能になります。
TL;DR(結論)
大規模言語モデル(LLM)の因果推論能力を評価する際、従来の文字列一致や表面的な指標では、モデルが出力した因果式が数学的に正しいかどうかを正確に判定できないという問題がありました。 本研究が提案する「DoVerifier」は、do演算(do-calculus)と確率論の規則に基づき、モデルが生成した式が与えられた因果グラフから形式的に導出可能かをシンボリックに検証するシステムです。 検証の結果、従来の手法では誤答とされていた多くの回答が実は意味的に正解であったことが判明し、この手法を用いることでLLMの真の推論能力をより厳密に測定し、自己修正を促すことが可能になります。
なぜこの問題か
大規模言語モデルは、科学、医療、政策決定といった高度な判断が求められる分野での活用が期待されており、単なるパターンの認識を超えた因果推論能力が不可欠となっています。因果推論は、相関と因果を区別し、介入による影響を予測し、仮定のシナリオ下での結果を説明するために重要な役割を果たします。しかし、既存の因果推論ベンチマークであるCLadderやCausalBenchなどは、モデルの回答が正解の文字列と一致するか、あるいは単純なシナリオで正しい数値を出せるかといった表面的な評価に依存しているのが現状です。このような評価指標には、モデルが論理的に正しい因果式を生成しているにもかかわらず、表記の揺れや形式の違いによって不当に低い評価を受けてしまうという欠点があります。 例えば、因果推論において「P(Y|do(X), Z)」と「P(Y|Z, do(X))」は意味的に等価ですが、単純な文字列一致ではこれらを別物とみなしてしまいます。また、BLEUスコアやBERTScoreといった自然言語処理で一般的な指標も、因果的な意味の正確さを捉えるようには設計されていません。…
核心:何を提案したのか
本研究は、LLMが生成した因果式の意味的な正しさを判定するためのシンボリック検証フレームワーク「DoVerifier」を提案しました。このシステムは、モデルの出力を単なるテキストとして扱うのではなく、因果グラフと数学的な規則に基づいた形式的な証明の対象として扱います。具体的には、与えられた因果グラフの構造において、モデルが生成した式がターゲットとなる正解の式から論理的に導き出せるかどうかを、シンボリックな証明探索を通じて確認します。DoVerifierの核心は、因果推論の標準的な枠組みであるdo演算(do-calculus)と確率論の基本規則を実装している点にあります。 これにより、モデルが生成した複雑な介入を含む式が、グラフ上の条件付き独立性や介入の性質を正しく反映しているかを厳密にチェックできます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related