MGSM-Pro: 堅牢な多言語数学的推論評価のためのシンプルな戦略
大規模言語モデルの多言語における数学的推論能力を正確に評価するため、既存のMGSMを拡張し、数値や名前の変更、無関係な文脈の挿入を施した5つのバリエーションを持つ新データセット「MGSM-Pro」を提案し、モデルが特定の数値パターンを記憶している可能性を排除した。
TL;DR(結論)
大規模言語モデルの多言語における数学的推論能力を正確に評価するため、既存のMGSMを拡張し、数値や名前の変更、無関係な文脈の挿入を施した5つのバリエーションを持つ新データセット「MGSM-Pro」を提案し、モデルが特定の数値パターンを記憶している可能性を排除した。 検証の結果、多くのモデルが数値のわずかな変更に対して脆弱であり、特に低リソース言語において性能が大幅に低下すること、また従来の単一問題による評価ではモデルの真の実力やランキングを正確に反映できず、特定のモデルが過大評価されている実態が明らかになった。 モデルの数学的推論における真の頑健性を測定するためには、同一の問題に対して数値を変化させた少なくとも5つのバリエーションを用いて平均精度を算出する「Avg-5」評価手法が不可欠であることを本研究は提唱し、より現実的で信頼性の高い評価基準の確立を目指している。
なぜこの問題か
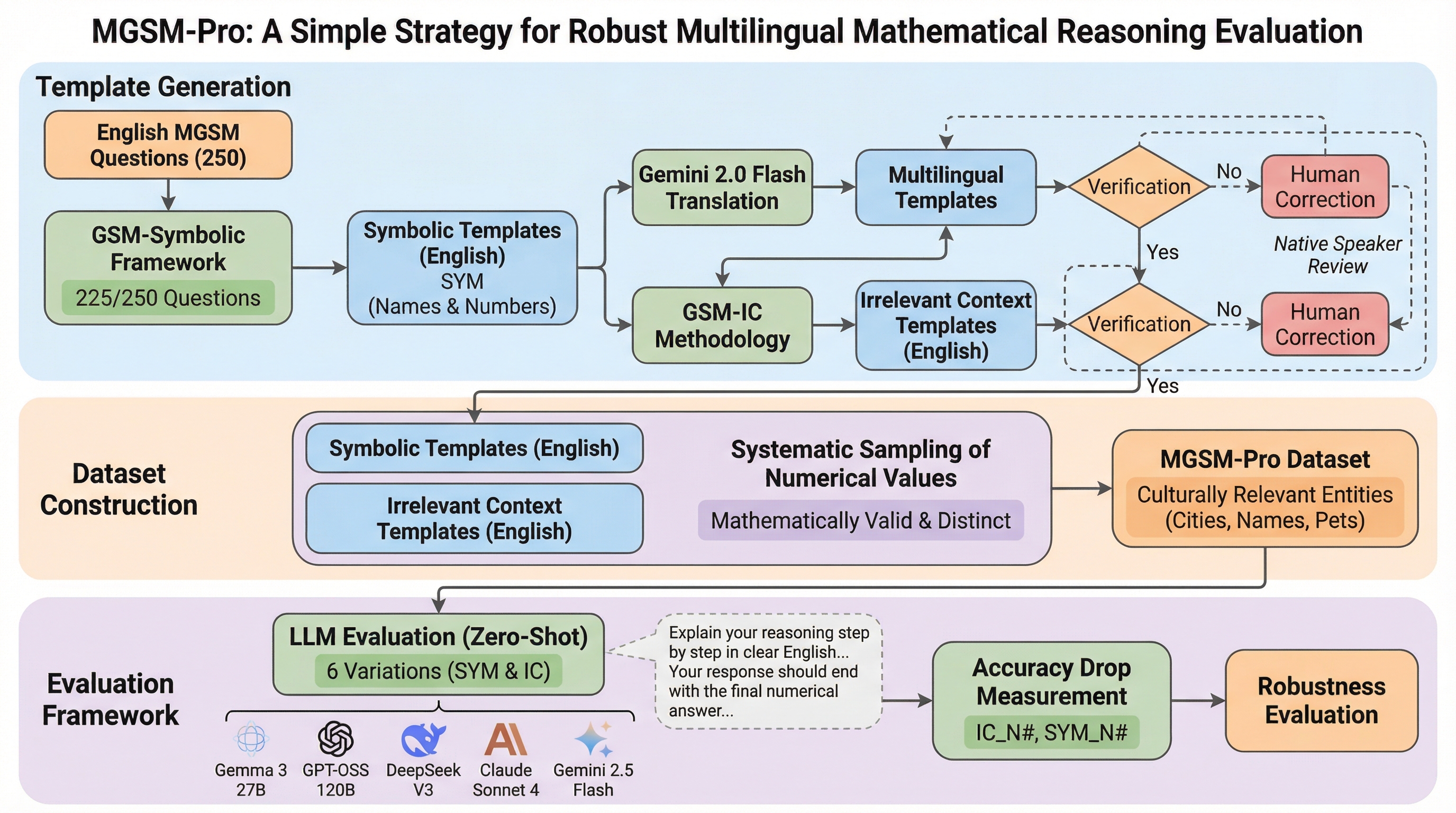
大規模言語モデル(LLM)は、知識集約的なタスクや複雑な推論タスクにおいて目覚ましい進歩を遂げており、オープンモデルと商用モデルの差も縮まりつつあるが、多言語設定における数学的推論の評価ベンチマークの開発は、英語と比較して難易度や更新頻度の面で大きく遅れているのが現状である。既存の多言語ベンチマークは、すでに性能が飽和状態にあるか、あるいはモデルがテストセットを暗記したり、特定のデータに対して過剰に最適化されたりしている可能性が極めて高い。先行研究であるGSM-Symbolicでは、英語の設定において、同一の問題であっても数値や名前などの具体的な設定(インスタンス化)を変更するだけで、モデルの回答精度に大きなばらつきが生じることが示されているが、この調査は英語のみに限定されており、多言語環境での実態は不明であった。多言語設定においても、既存のベンチマークの多くは英語のベンチマークをそのまま翻訳しただけであり、数値や文脈の変更が行われていないため、モデルが同様の構造を持つ他の問題に汎化できているのか、あるいは単に特定の数値を記憶しているだけなのかが不明確であった。…
核心:何を提案したのか
本研究では、多言語数学推論ベンチマークであるMGSMを拡張した「MGSM-Pro」を提案しており、これは英語で提案されたGSM-Symbolicの手法を多言語設定に適用した画期的なデータセットである。MGSM-Proは、MGSMに含まれる250問のうち、厳格な検証を通過した225問をベースに構築されており、各問題に対して名前、数値、および無関係な文脈を変化させた5つの異なるインスタンス(バリエーション)を提供している点が最大の特徴である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related