TSRBench: 汎用モデルのための包括的なマルチタスク・マルチモーダル時系列推論ベンチマーク
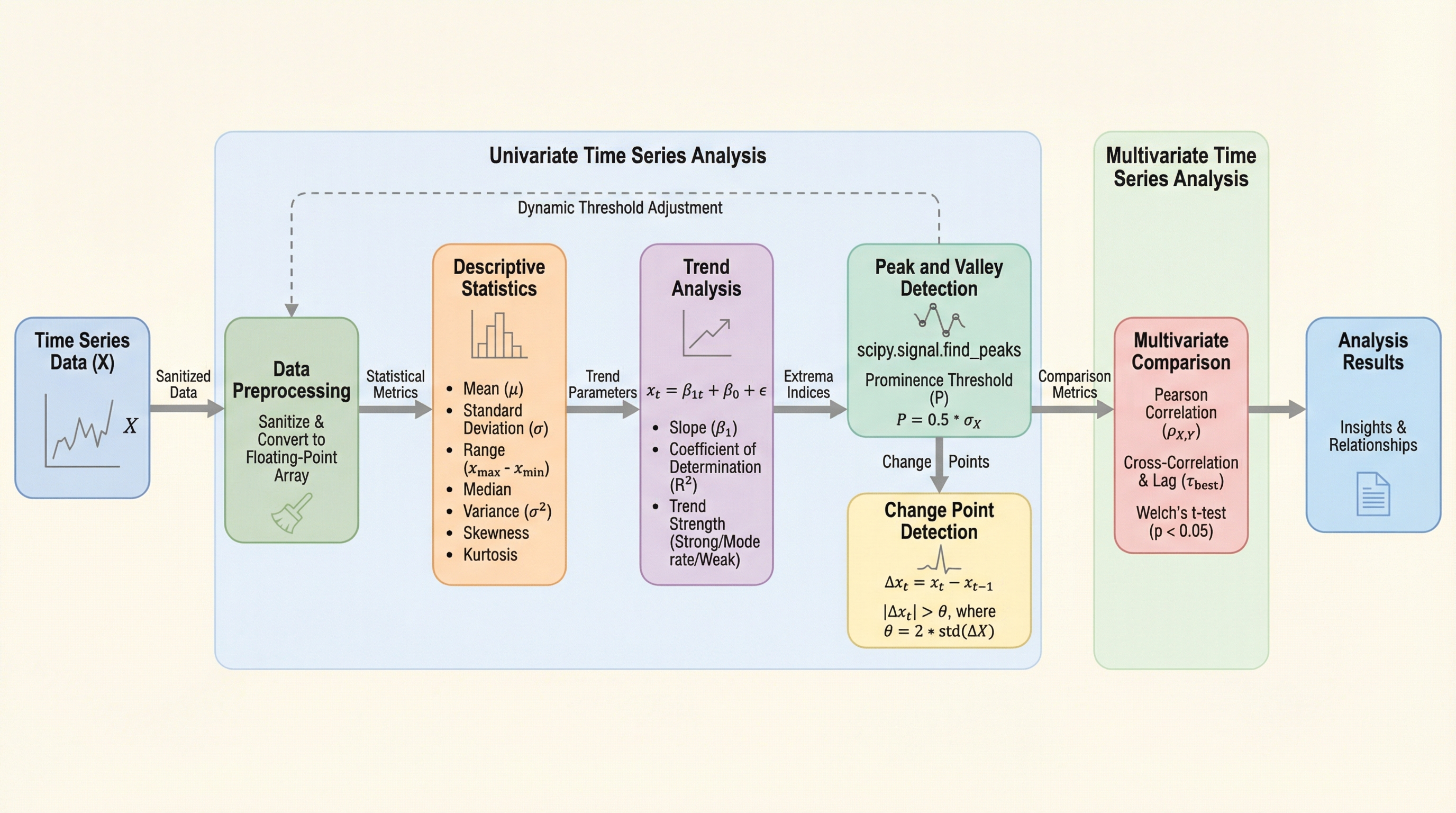
時系列データは現実世界の意思決定において不可欠ですが、従来の評価手法は単純な数値予測に偏り、文脈や因果関係を考慮した高度な推論能力を測定できていませんでした。本研究が提案する「TSRBench」は、14のドメインから収集された4125個の問題を含み、認識、推論、予測、意思決定の4つの次元と15のタスクを通じて、汎用モデルの時系列処理能力を多角的に評価する初の包括的なマルチモーダルベンチマークです。30以上の主要モデルを検証した結果、モデル規模の拡大は認識や論理推論には有効であるものの予測精度には必ずしも直結せず、また現在のマルチモーダルモデルはテキストと視覚情報の統合において相乗効果を生み出せていないという重要な課題が明らかになりました。