Wikipedia Glottosetを用いた242言語にわたるサブワードベースの比較言語学
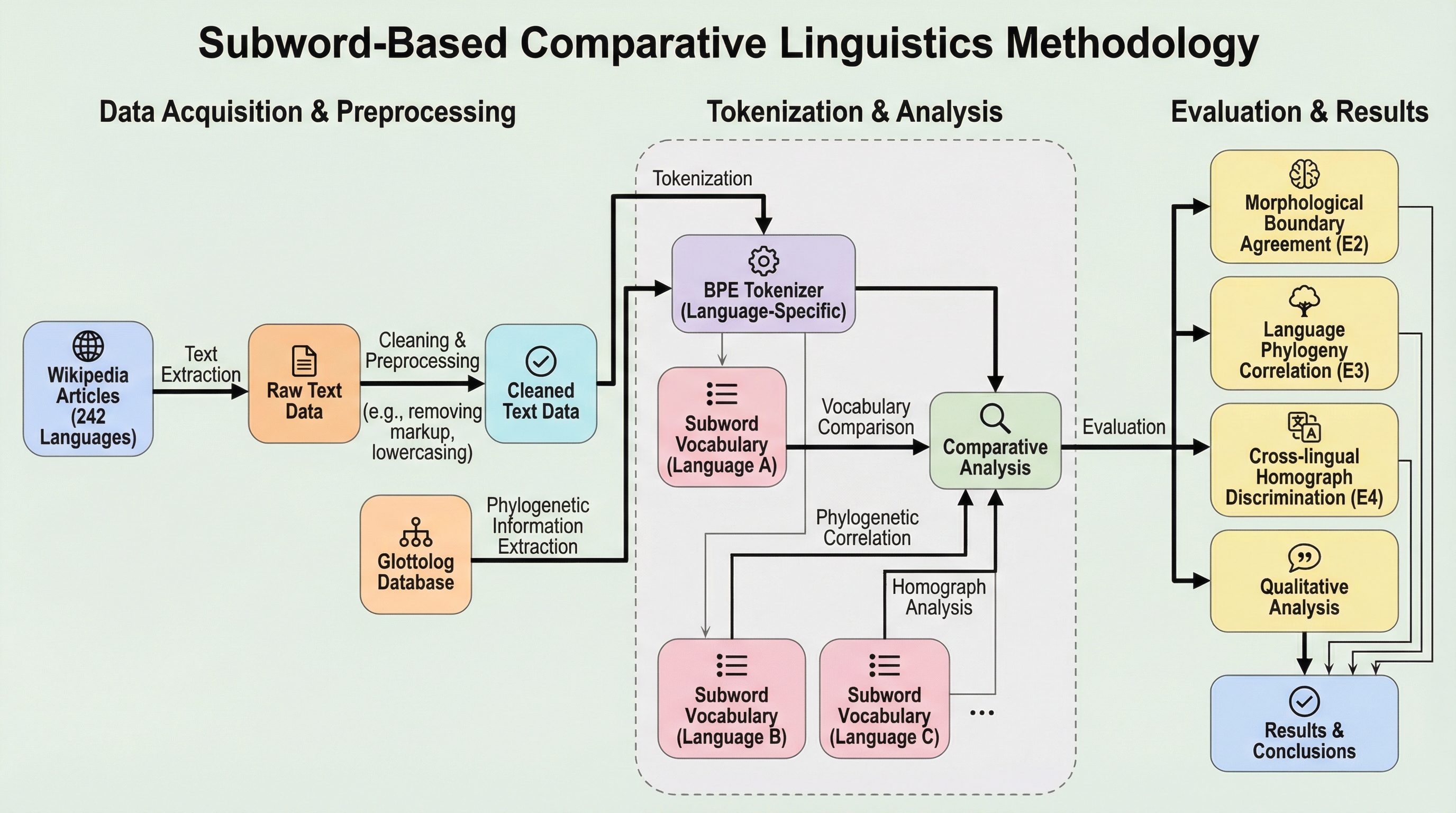
本研究は、Wikipediaの語彙データから構築した「glottoset」を活用し、ラテン文字とキリル文字を使用する242言語を対象に、Byte-Pair Encoding(BPE)を用いた大規模な比較言語学のフレームワークを提案した。
TL;DR(結論)
本研究は、Wikipediaの語彙データから構築した「glottoset」を活用し、ラテン文字とキリル文字を使用する242言語を対象に、Byte-Pair Encoding(BPE)を用いた大規模な比較言語学のフレームワークを提案した。 BPEによるサブワード分割は、ランダムな基準と比較して形態素境界を95%正確に捉えることが確認され、語彙の類似性が言語の系統的な関連性(マンテル検定による相関係数0.329)と有意に相関することを実証した。 26,939語の同形異義語を解析した結果、関連言語間でも48.7%が異なる分割パターンを示しており、サブワード単位の解析が伝統的な手法を超えて言語間の微細な構造的差異を定量化できる強力な手段であることを示した。
なぜこの問題か
伝統的な比較言語学は、歴史的な再構築や類型論的な洞察を通じて言語の進化を解明してきたが、現代のデジタル空間に存在する膨大なテキストデータを処理するためのスケーラビリティが不足しているという深刻な課題に直面している。専門家による手動の言語調整や精密な注釈作業は、高い信頼性を誇る一方で、数千もの言語を網羅的に分析するには膨大な時間とコストがかかり、特に絶滅の危機に瀕した言語やデジタルリソースの少ない言語が研究の対象から取り残されやすいという不均衡が生じている。近年の自然言語処理(NLP)の進展は、データ駆動型の大規模な研究を可能にし、音声学や語彙意味論における普遍的な傾向を明らかにしてきたが、依然として多くの研究は特定の言語家族や高リソース言語に限定されており、文字体系を共有する広範な言語群を横断的に分析する視点が欠落していた。 本研究が取り組むのは、この「規模の壁」と「リソースの偏り」を打破することである。…
核心:何を提案したのか
本研究の核心的な提案は、Wikipediaの語彙集から構築された「glottoset」という概念を導入し、Byte-Pair Encoding(BPE)を利用して242言語を同時に比較・分析する新しいマクロ言語学的フレームワークである。このフレームワークは、個別の言語を孤立して扱うのではなく、ラテン文字(205言語)とキリル文字(37言語)という文字体系レベルで言語を統合し、大規模なサブワードベースの解析を行う点に最大の特徴がある。BPEは本来、機械翻訳などのタスクで未知語を処理するために開発された手法だが、本研究ではこれを言語間の形態論的な類似性や系統的な距離を測定するための「定規」として再定義している。 具体的には、Wikipediaのダンプデータから抽出されたクリーンなテキストを用いて、各言語固有の語彙セット(glottoset)を構築し、そこに単語の出現頻度(TF)や文書頻度(DF)といった統計情報を付与した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related