文埋め込みを用いたカーネル変化点検出による教師なしテキストセグメンテーション
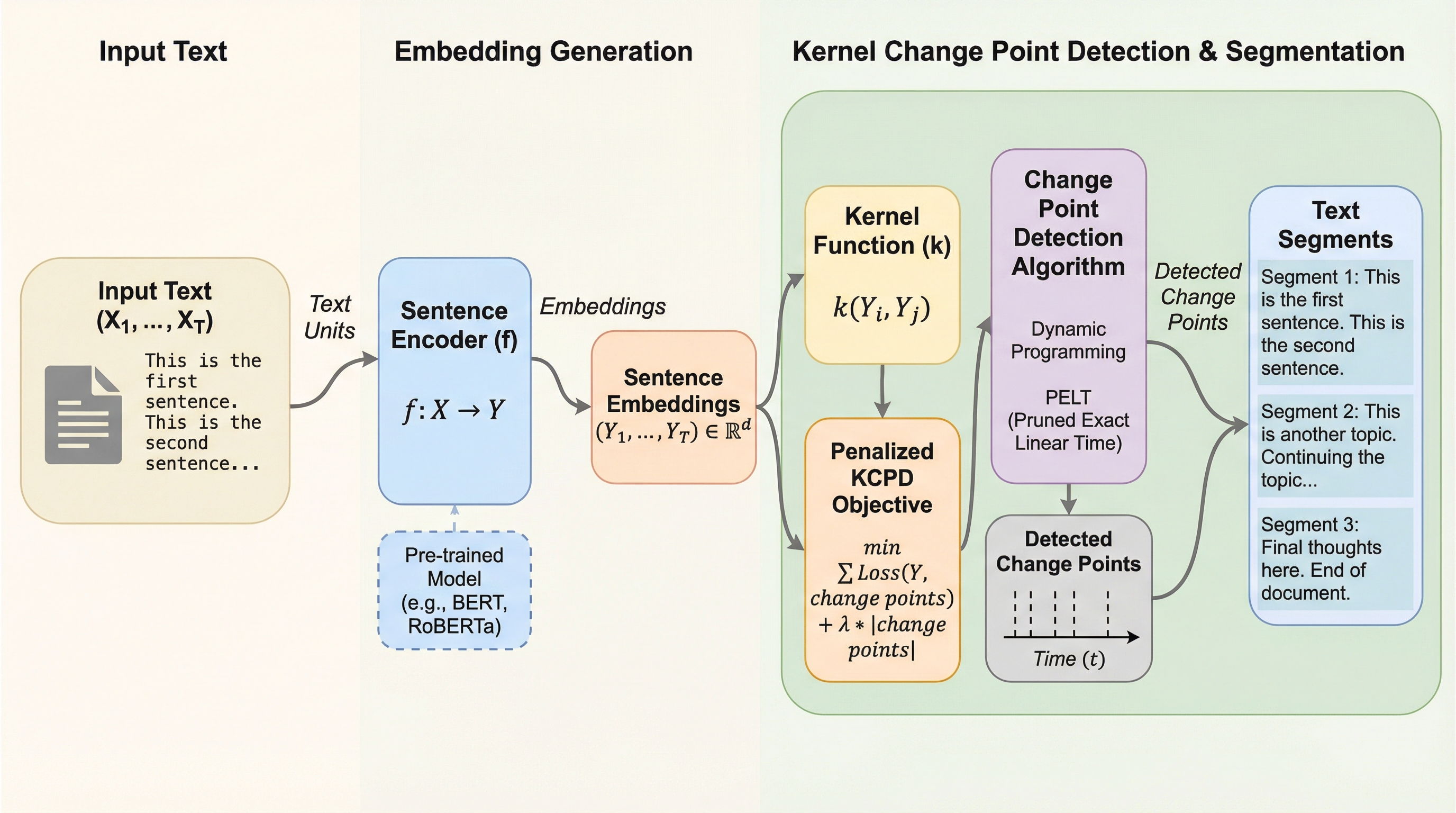
テキストセグメンテーションにおける境界ラベルの付与コストや主観性の問題を解決するため、事前学習済みの文埋め込みとカーネル変化点検出(KCPD)を組み合わせた、学習不要で汎用性の高い教師なし手法「Embed-KCPD」が提案されました。
TL;DR(結論)
テキストセグメンテーションにおける境界ラベルの付与コストや主観性の問題を解決するため、事前学習済みの文埋め込みとカーネル変化点検出(KCPD)を組み合わせた、学習不要で汎用性の高い教師なし手法「Embed-KCPD」が提案されました。 言語データ特有の短距離依存関係を考慮した「m-依存シーケンス」に基づく初の統計的理論を構築し、真の変化点が特定の窓内で正確に回収されるという位置特定保証と、母集団のリスクに対するオラクル不等式を数学的に証明しています。 GPT-4.1を用いたシミュレーションや標準ベンチマーク、実データの解析において、既存の強力な教師なし手法を上回る精度を達成し、理論通りのスケーリング挙動と実用的な有効性が多角的な検証によって裏付けられました。
なぜこの問題か
文書を意味的に一貫したトピック単位に分割するテキストセグメンテーションは、情報検索、要約、質問応答、談話分析といった多くの自然言語処理(NLP)システムの基盤となる重要な工程です。しかし、このタスクを教師あり学習で解決しようとすると、いくつかの深刻な問題に直面します。まず、境界ラベルの付与には多大なコストがかかるだけでなく、何をもって「正しい境界」とするかは下流のタスクや求められる粒度、注釈プロトコルによって大きく異なり、主観性を完全に排除することができません。そのため、特定のデータセットで学習したモデルを他のドメインや異なる基準のタスクに転移させることが困難であるという課題があります。このような背景から、ラベルなしで動作し、多様なデータセットに対して頑健な教師なし手法の実用的な価値は極めて高いと言えます。 統計的な視点では、セグメンテーションはデータの生成分布が変化する指標を特定する「変化点検出(CPD)」として捉えることができます。従来の変化点検出手法は強力な理論的保証を持ちますが、ガウス分布や独立性、等分散性といった制約の強い仮定に依存していることが多く、高次元のテキスト表現に対しては脆弱になる可能性があります。…
核心:何を提案したのか
本研究が提案する「Embed-KCPD」は、事前学習済みの文エンコーダとカーネル変化点検出を組み合わせた、モジュール化された学習不要の教師なしテキストセグメンテーション手法です。この手法の最大の特徴は、表現学習と統計的なセグメンテーションを完全に切り離している点にあります。これにより、文エンコーダの性能が向上すれば、セグメンタを再学習させることなく即座にその恩恵を享受できるという柔軟性を備えています。アルゴリズムの実装にとどまらず、本研究は言語データに特有の短距離依存関係をモデル化するための「m-依存シーケンス」という概念を導入し、この条件下でのKCPDに関する初の理論的保証を構築しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related