表現準同型はTransformer言語モデルにおける構成的汎化を予測し改善する
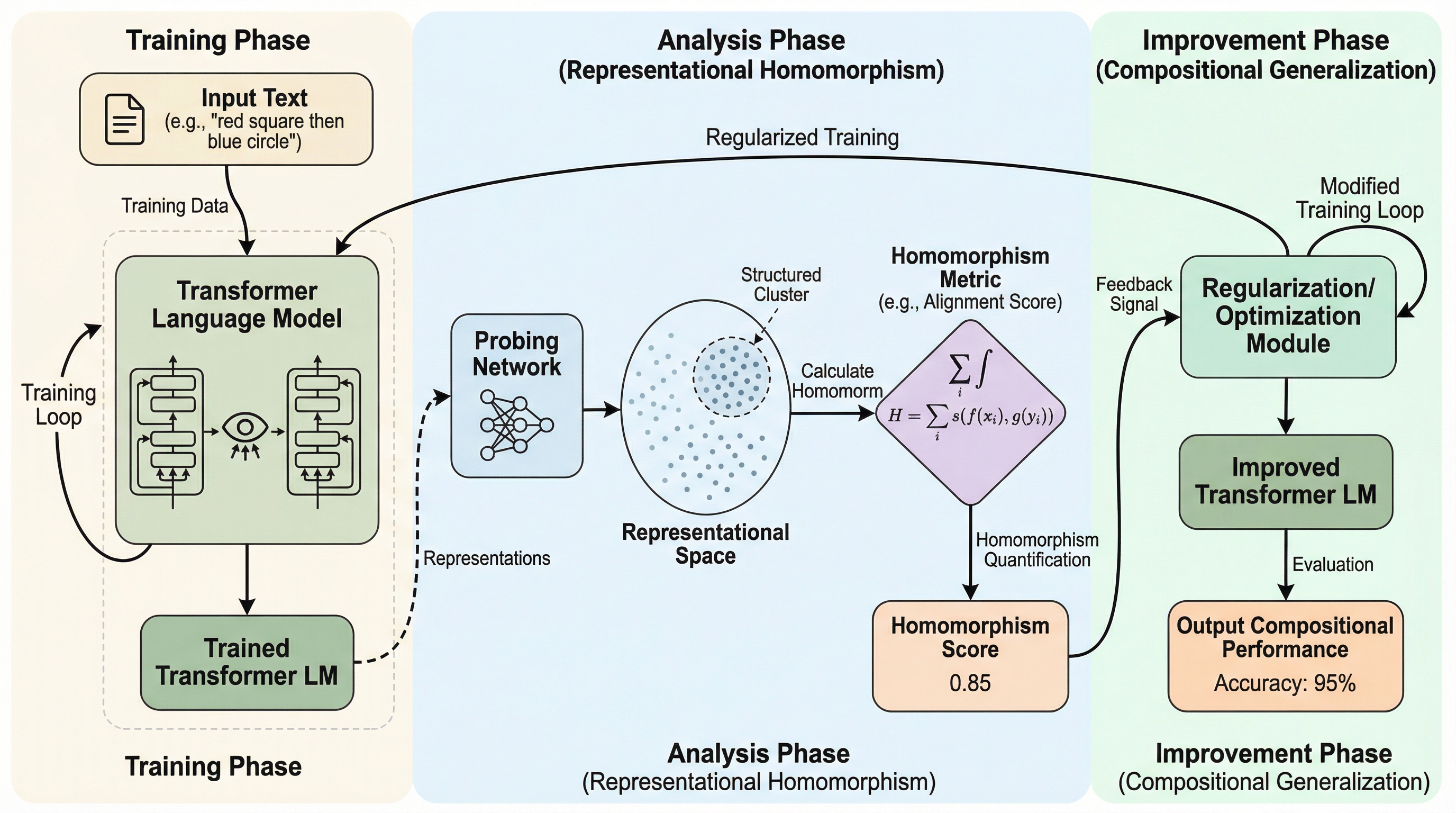
ニューラルネットワークが既知の要素を未知の組み合わせで理解する「構成的汎化」は長年の難題であり、本研究ではモデルの内部表現が代数的な構成構造をどの程度保持しているかを定量化する新指標「準同型誤差(HE)」を提案した。 実験の結果、この準同型誤差はノイズ環境下での分布外(OOD)への汎化性能と強い相関(決定係数0.
TL;DR(結論)
ニューラルネットワークが既知の要素を未知の組み合わせで理解する「構成的汎化」は長年の難題であり、本研究ではモデルの内部表現が代数的な構成構造をどの程度保持しているかを定量化する新指標「準同型誤差(HE)」を提案した。 実験の結果、この準同型誤差はノイズ環境下での分布外(OOD)への汎化性能と強い相関(決定係数0.73)を示し、モデルの層の深さよりも訓練データの網羅性やノイズの有無が内部構造の維持に決定的な影響を与えることを突き止めた。 さらに、学習過程でこの準同型誤差を直接最小化する正則化手法を導入したところ、内部表現の代数的構造が明示的に強化され、分布外タスクにおける正解率が統計的に有意なレベル(p=0.023)で向上することを確認し、HEが診断と改善の両面で有効であることを証明した。
なぜこの問題か
人間の言語理解における最大の特徴の一つは、体系的な構成性にある。これは、すでに知っている単語や概念を新しい方法で組み合わせることで、一度も聞いたことがない表現であっても即座にその意味を理解できる能力を指す。例えば、「2回ジャンプする」という表現と「回転する」という単語の意味を理解していれば、特別な訓練を受けなくても「2回回転する」という新しい組み合わせの意味を推論できる。このような代数的な性質により、人間は限られた経験から無限の表現空間へと適応することが可能となっている。しかし、現代の自然言語処理を牽引するニューラルネットワーク、特にトランスフォーマーモデルは、このような体系的な構成的汎化において依然として大きな困難に直面していることが多くの研究で指摘されている。 これまでの研究では、SCAN、COGS、CFQといったベンチマークデータセットを用いて、モデルの構成的汎化能力が厳密に評価されてきた。これらの調査により、現在のモデルは訓練データと同じ分布内では極めて高い精度を達成するものの、既知の要素を新しい組み合わせで提示される分布外(OOD)のテストセットでは、しばしば壊滅的な失敗を喫することが明らかになっている。…
核心:何を提案したのか
本研究の核心的な提案は、ニューラルネットワークの内部表現が構成的な操作をどの程度正確に保持しているかを定量化する構造的指標である「準同型誤差(Homomorphism Error, HE)」の導入である。この指標は、言語表現が持つ代数的な空間と、モデルの隠れ状態空間の間の「準同型性」からの逸脱を測定するものである。数学における準同型写像とは、ある集合の演算構造を別の集合へ移してもその構造が保たれる写像を指す。これを言語モデルに当てはめると、構成要素の表現を組み合わせたものが、構成された全体の表現と一致すべきであるという要請になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related