高速道路交通におけるトラックの効率的な戦術的意思決定のための多目的強化学習
高速道路を走行する大型トラックの自動運転において、安全性、時間効率、エネルギー効率という互いに相反する重要な目標を同時に最適化するため、多目的強化学習(MORL)を用いた新しい意思決定フレームワークを提案している。
TL;DR(結論)
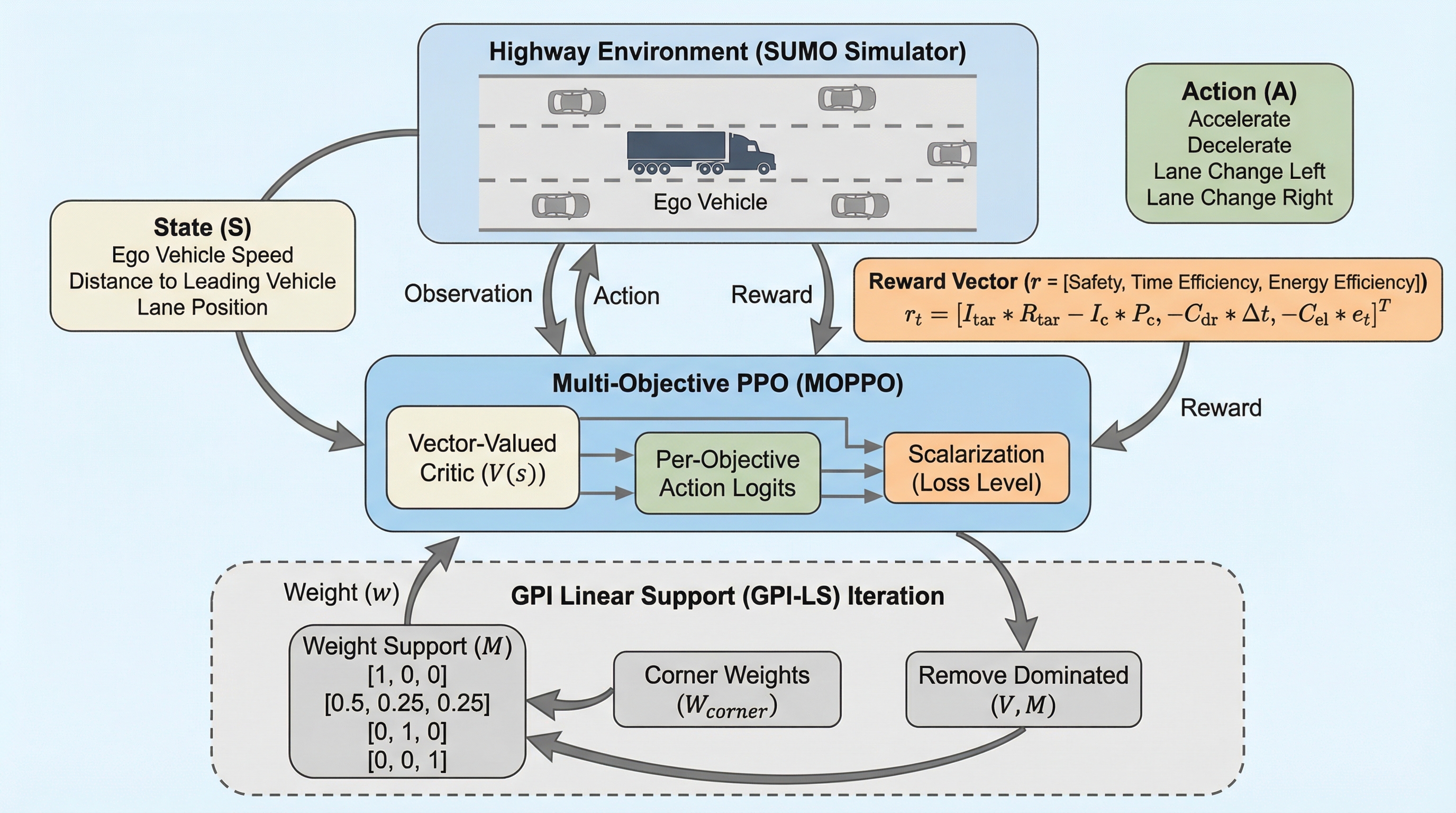
高速道路を走行する大型トラックの自動運転において、安全性、時間効率、エネルギー効率という互いに相反する重要な目標を同時に最適化するため、多目的強化学習(MORL)を用いた新しい意思決定フレームワークを提案している。 従来の単一報酬設計では困難だった目標間の複雑なトレードオフを、近接方策最適化(PPO)を多目的に拡張した「MOPPO」と、パレート最適解を効率的に探索する「GPILS」アルゴリズムを組み合わせることで、明示的かつ連続的な方策集合として表現することに成功した。 高精度な交通シミュレーターを用いた検証の結果、再学習を行うことなくユーザーの好みに応じて「燃費優先」や「時間優先」といった運転スタイルを即座に切り替えることが可能であり、商用トラックの運用における柔軟性と安全性の両立を実証した。
なぜこの問題か
高速道路における大型トラックの自動運転は、単に目的地に到達するだけでなく、安全性、運行効率、そして運用コストの極めて繊細なバランスを取らなければならない非常に困難な意思決定問題である。大型トラックは乗用車と比較して、その巨大な車体サイズ、高い燃料消費量、そして長い制動距離という物理的な特性を持っており、わずかな制御ミスや判断の遅れが深刻な事故や莫大な経済的損失を招く可能性がある。そのため、交通状況に応じて「密集地では安全を最優先し、開けた道では燃費を優先する」といった適応的な管理が不可欠となる。しかし、従来の強化学習アプローチの多くは、安全性や快適性、エネルギー効率といった複数の異なる目標を、単一のスカラ値である報酬関数に統合して学習を行っている。このように目標を一つにまとめてしまうと、それぞれの目標間の複雑なトレードオフ構造がブラックボックス化し、特定の状況下でどの要素をどの程度優先すべきかという柔軟な調整が困難になるという課題があった。…
核心:何を提案したのか
本研究では、大型トラックの戦術的意思決定のために特別に設計された、新しい多目的強化学習(MORL)フレームワークを提案している。このフレームワークの核心は、広く用いられている近接方策最適化(PPO)を多目的環境に拡張した「Multi-Objective PPO(MOPPO)」と、線形支援を用いた一般化方策改善(GPILS)を組み合わせた点にある。提案手法は、安全性(衝突回避と目標到達)、時間効率(ドライバーコスト)、エネルギー効率(エネルギー消費コスト)という3つの相反する目標間のトレードオフを明示的に表現する、連続的なパレート最適方策の集合を学習する。具体的には、ベクトル値の報酬関数を採用し、各目標の構造を学習過程で維持することで、ユーザーの好みに応じた重み付け(プリファレンス)に基づいた柔軟な意思決定を可能にしている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related