発見するための学習:忘却のないラーガ識別のための一般化フレームワーク
インド古典音楽のラーガ識別において、既知のラーガを正確に分類する能力を維持しながら、訓練データに含まれない未知のラーガを自動的に発見・構造化する「一般化カテゴリー発見(GCD)」フレームワークを提案した。
TL;DR(結論)
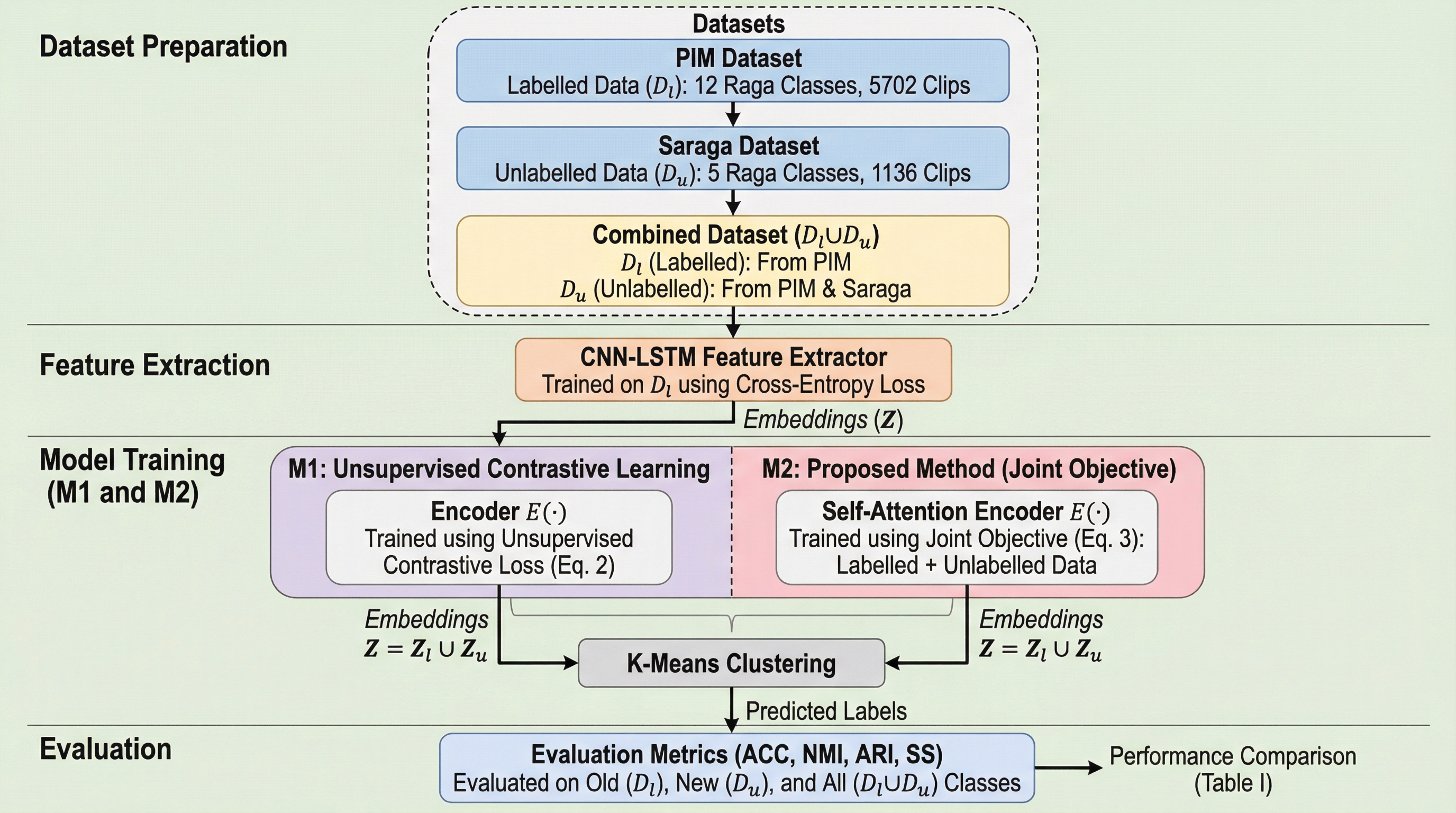
インド古典音楽のラーガ識別において、既知のラーガを正確に分類する能力を維持しながら、訓練データに含まれない未知のラーガを自動的に発見・構造化する「一般化カテゴリー発見(GCD)」フレームワークを提案した。 従来の「新規クラス発見(NCD)」手法で問題となっていた、新しい知識を学習する際に既存の知識を失ってしまう「致命的な忘却」を、ラベル付きデータとラベルなしデータを統合した対照学習によって克服している。 検証の結果、既知クラスの識別精度を91.16%に向上させつつ、未知クラスの発見精度も大幅に改善し、音楽的に類似したラーガ間の誤分類を解消するなど、大規模な音楽アーカイブの自動整理に道を開く成果を上げた。
なぜこの問題か
インド古典音楽(IAM)の根幹をなす「ラーガ」は、単なる音階の定義に留まらず、特定の旋律の動き、装飾(ガマカ)、時間的な変化、そして即興的な軌跡によって定義される非常に複雑な音楽的枠組みである。このため、同じラーガであっても演奏者やスタイルによって多様な表現がなされる一方で、異なるラーガ同士が共通の音構成を持ちながら、旋律のニュアンスやフレーズの強調の仕方がわずかに異なるだけというケースも少なくない。このような本質的な複雑さに加え、実世界の音楽アーカイブや教育現場、コミュニティ主導のデータベースには、既存の訓練データには含まれていない「未知のラーガ」や「演奏機会の少ない希少なラーガ」が数多く存在している。 従来のラーガ識別システムは、あらかじめ定義された既知のカテゴリーのみを分類対象とする「クローズドセット」の設定を前提としていた。そのため、モデルが一度も学習したことのない新しいラーガに遭遇した際、それを適切に認識したり、意味のあるグループとして整理したりすることができないという実用上の大きな限界があった。…
核心:何を提案したのか
本研究では、インド古典音楽のラーガ識別における「致命的な忘却」を回避し、既知と未知の両方のクラスを同時に処理できる「一般化カテゴリー発見(GCD)」フレームワークを提案した。この提案手法の核心は、ラベル付きデータとラベルなしデータの両方を単一の共有埋め込み空間内で共同学習させる統合的な学習戦略にある。従来のNCD手法がラベルなしデータのみを切り離して学習していたのに対し、本フレームワークでは、ラベル付きデータを用いた教師あり学習の知見を維持しつつ、ラベルなしデータから新たな音楽的構造を抽出する「共同最適化」を実現している。 具体的には、事前訓練された特徴抽出器の上に、自己注意機構(セルフアテンション)を備えたエンコーダーを配置し、これを「教師あり対照学習」と「教師なし対照学習」を組み合わせた独自の目的関数で訓練する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related