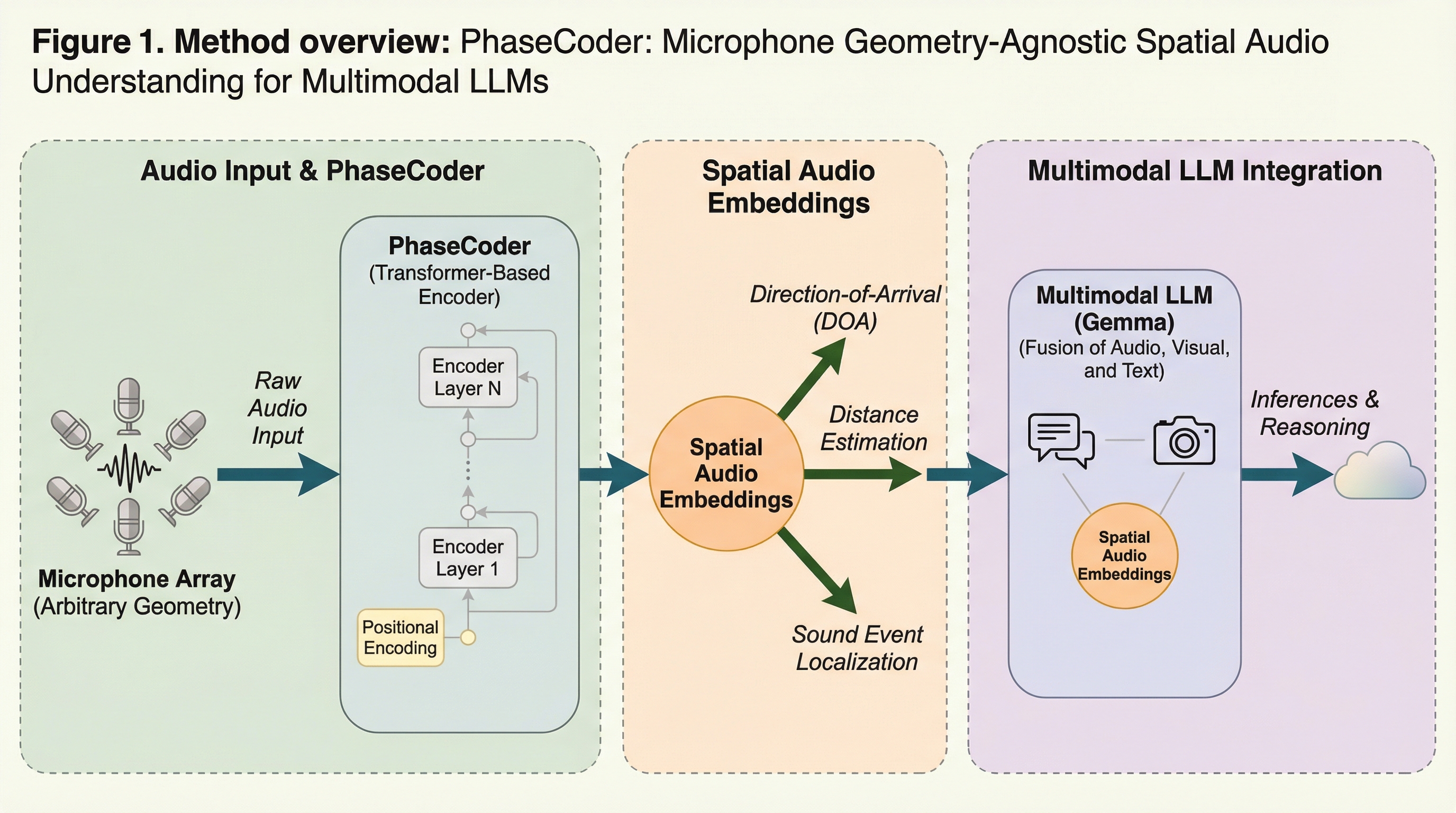
PhaseCoder:マルチモーダルLLMのためのマイク配置に依存しない空間オーディオ理解
PhaseCoderは、マイクの個数や配置といった幾何学的な条件に依存することなく、多チャンネルの音声データから豊かな空間情報を抽出することが可能な、トランスフォーマーのみで構成された画期的な空間オーディオエンコーダである。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
PhaseCoderは、マイクの個数や配置といった幾何学的な条件に依存することなく、多チャンネルの音声データから豊かな空間情報を抽出することが可能な、トランスフォーマーのみで構成された画期的な空間オーディオエンコーダである。
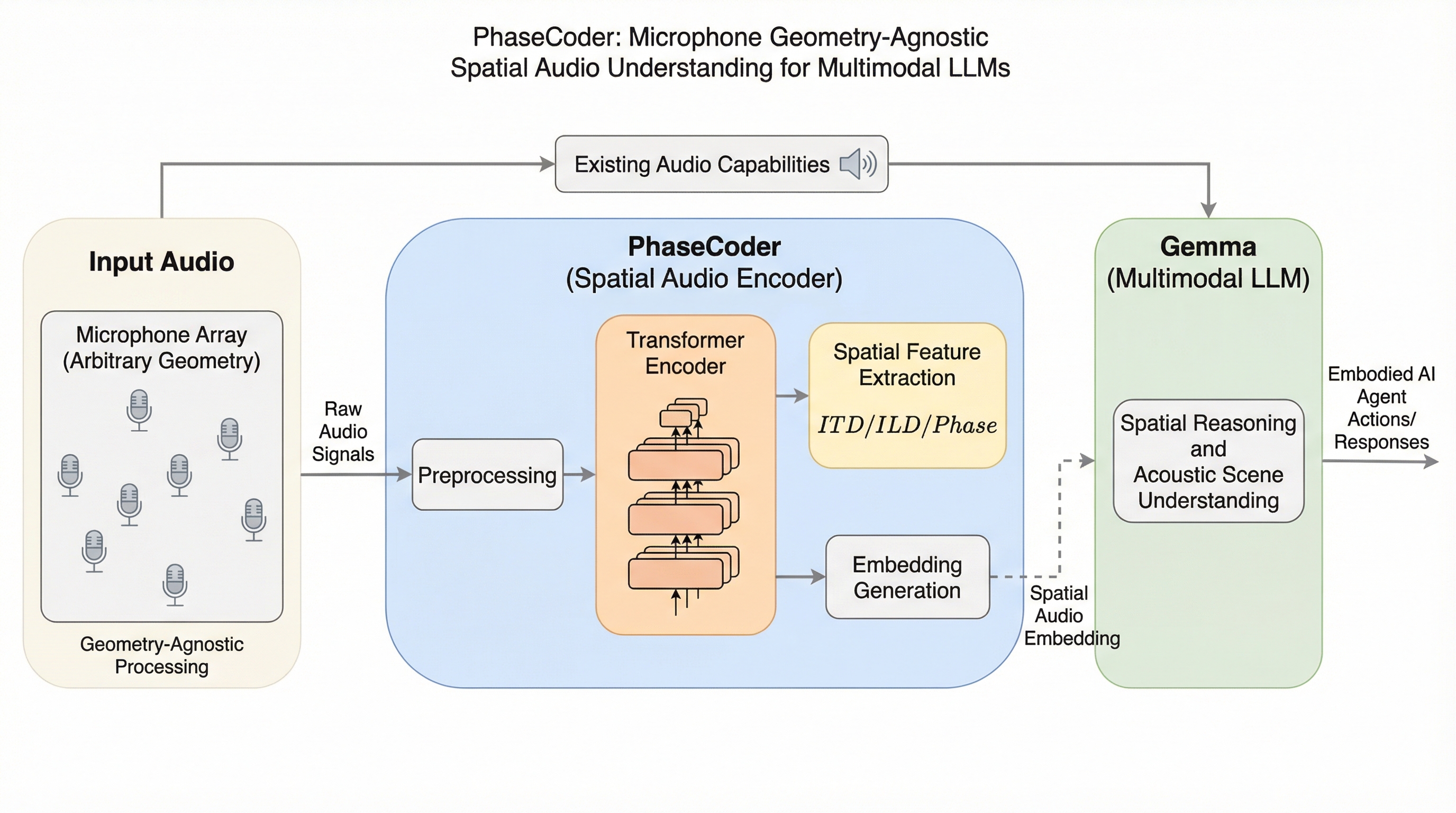
PhaseCoderは、マイクの数や配置に縛られず、多チャンネルの生音声とマイクの3次元座標から直接空間情報を抽出できる、トランスフォーマーのみで構成された革新的な空間オーディオエンコーダーである。
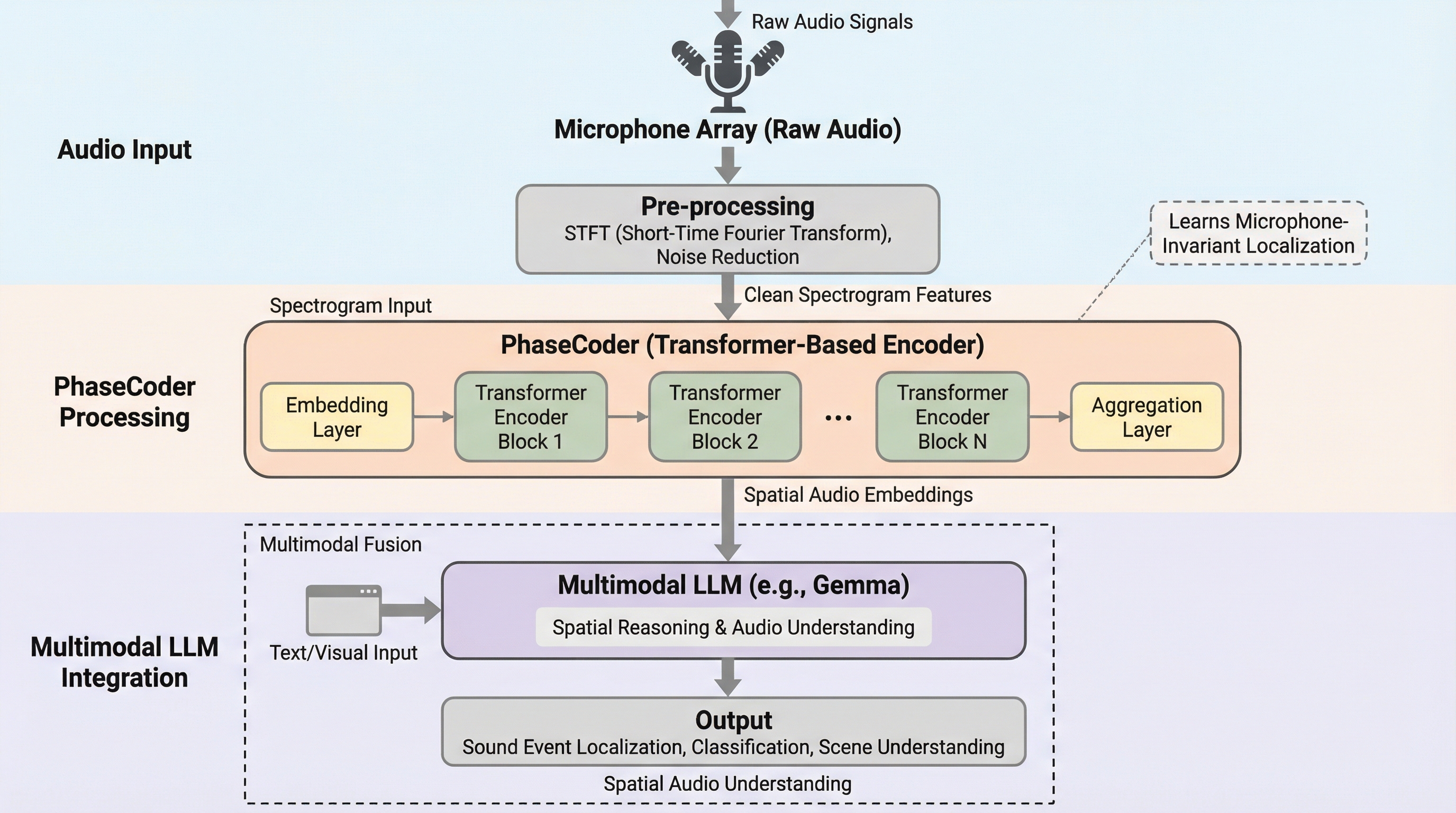
現在のマルチモーダル大規模言語モデル(LLM)は音声をモノラルとして処理しており、音の方向や距離といった空間情報の活用が困難であったが、本研究ではマイクの数や幾何学的配置に依存せず、あらゆるデバイスで利用可能な空間オーディオエンコーダ「PhaseCoder」を提案した。
現在の手話翻訳(SLT)データセットは、一つの手話に対して一つの書き言葉しか対応していないため、翻訳の多様性を評価できないという課題がありました。本研究では、大規模言語モデル(LLM)を用いて書き言葉のパラフレーズ(言い換え)を自動生成し、複数の正解候補(参照訳)として活用する手法を提案しました。
現在の手話翻訳データセットは、一つの手話表現に対して一つの書き言葉の翻訳しか紐付けられていないことが多く、手話と書き言葉の非同型な関係性を十分に捉えきれていないという課題がある。 本研究では、大規模言語モデル(LLM)を活用して翻訳文の言い換え(パラフレーズ)を自動生成し、これを合成的な代替参照文として用いることで、手話翻訳モデルの学習と評価の両面に与える影響を詳細に調査した。 検証の結果、言い換えを単純に学習に組み込むだけでは性能向上に繋がらない一方で、評価指標に複数の言い換えを取り入れた「BLEUpara」は、標準的な指標よりも人間の主観評価と強く相関することが明らかになった。
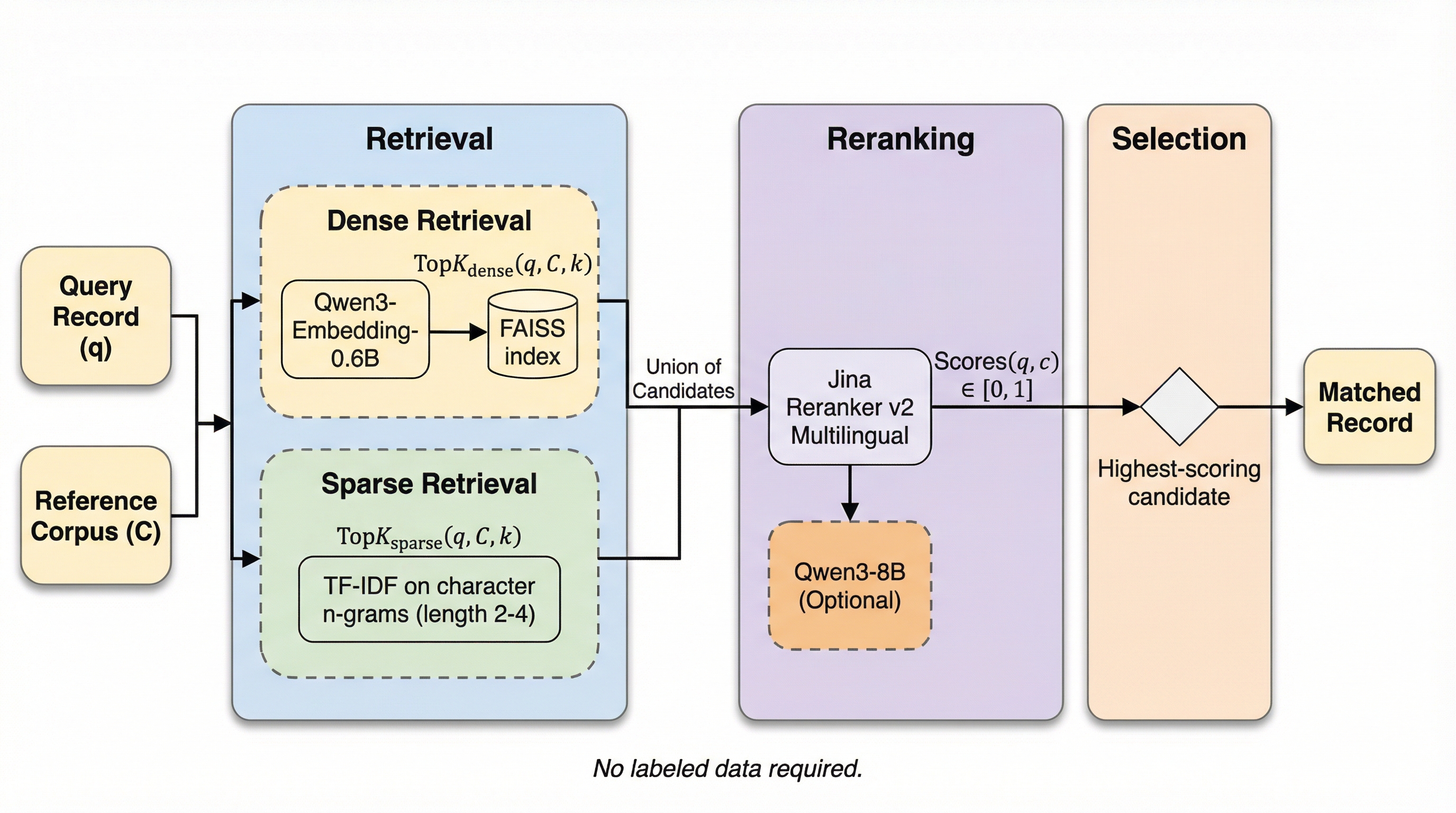
異なるデータセット間で同一の主体を特定するレコードリンケージにおいて、教師データを一切必要とせずに高い精度を達成する新手法「EnsembleLink」が提案されました。この手法は大規模なテキストコーパスで事前学習された言語モデルが持つ意味的な関係性の理解力を活用しており、都市名や人名、組織名、多言語の政党名といった多様なベンチマークにおいて、大量のラベルを必要とする既存の教師あり学習手法と同等、あるいはそれ以上の性能を記録しています。ローカル環境のオープンソースモデルのみで動作するため外部APIへの依存がなく、一般的な消費者向けハードウェアでも数分で処理を完了できる実用性を備えており、これまでアドホックな規則に頼っていたデータ統合プロセスの精度と信頼性を大幅に向上させることが期待されます。
レコードリンケージは、異なるデータセット間で同一のエンティティを指すレコードを照合するプロセスであり、社会科学において不可欠ですが、現在は場当たり的なルールが適用されるなど手法として未発達な側面があります。
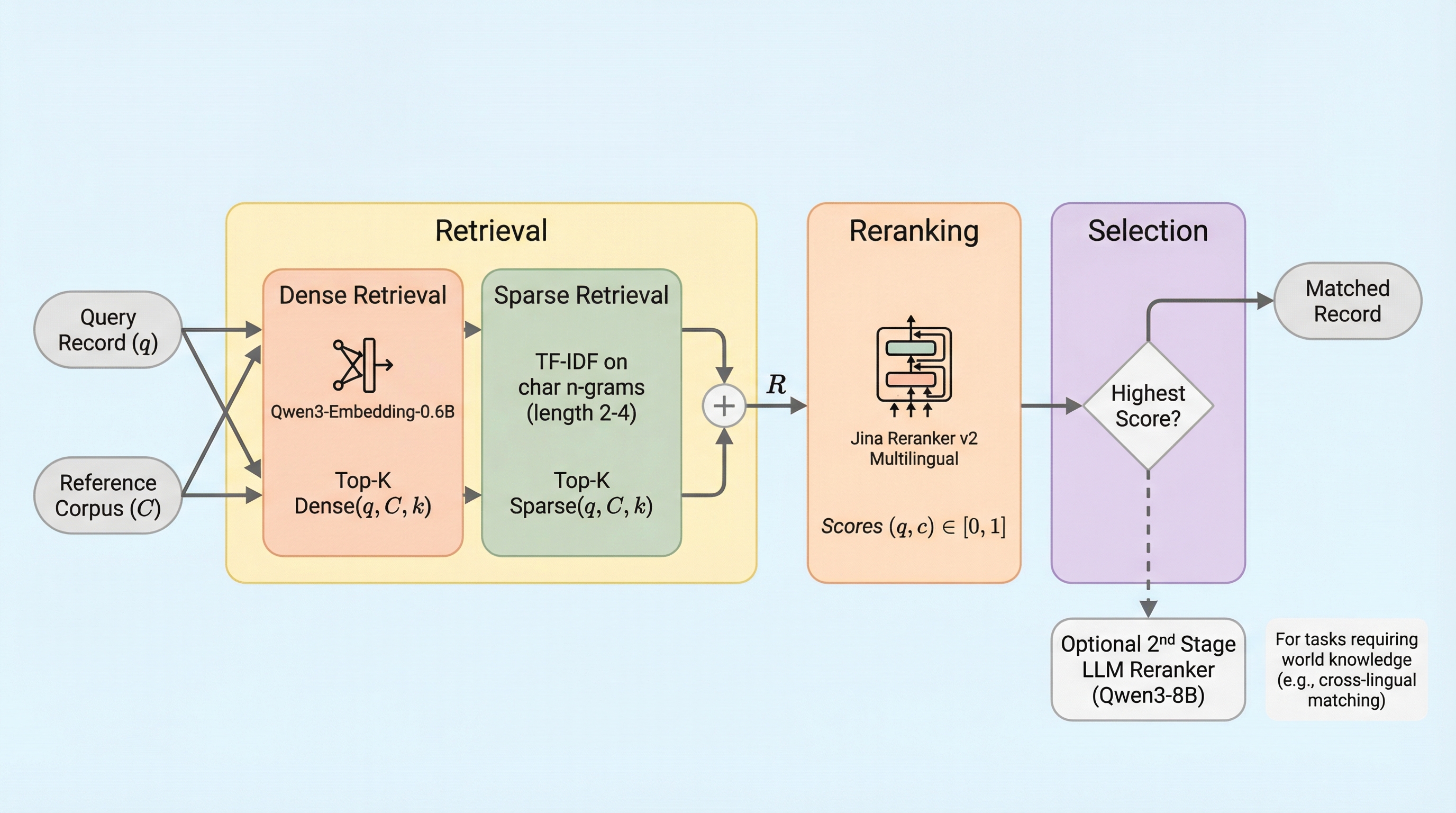
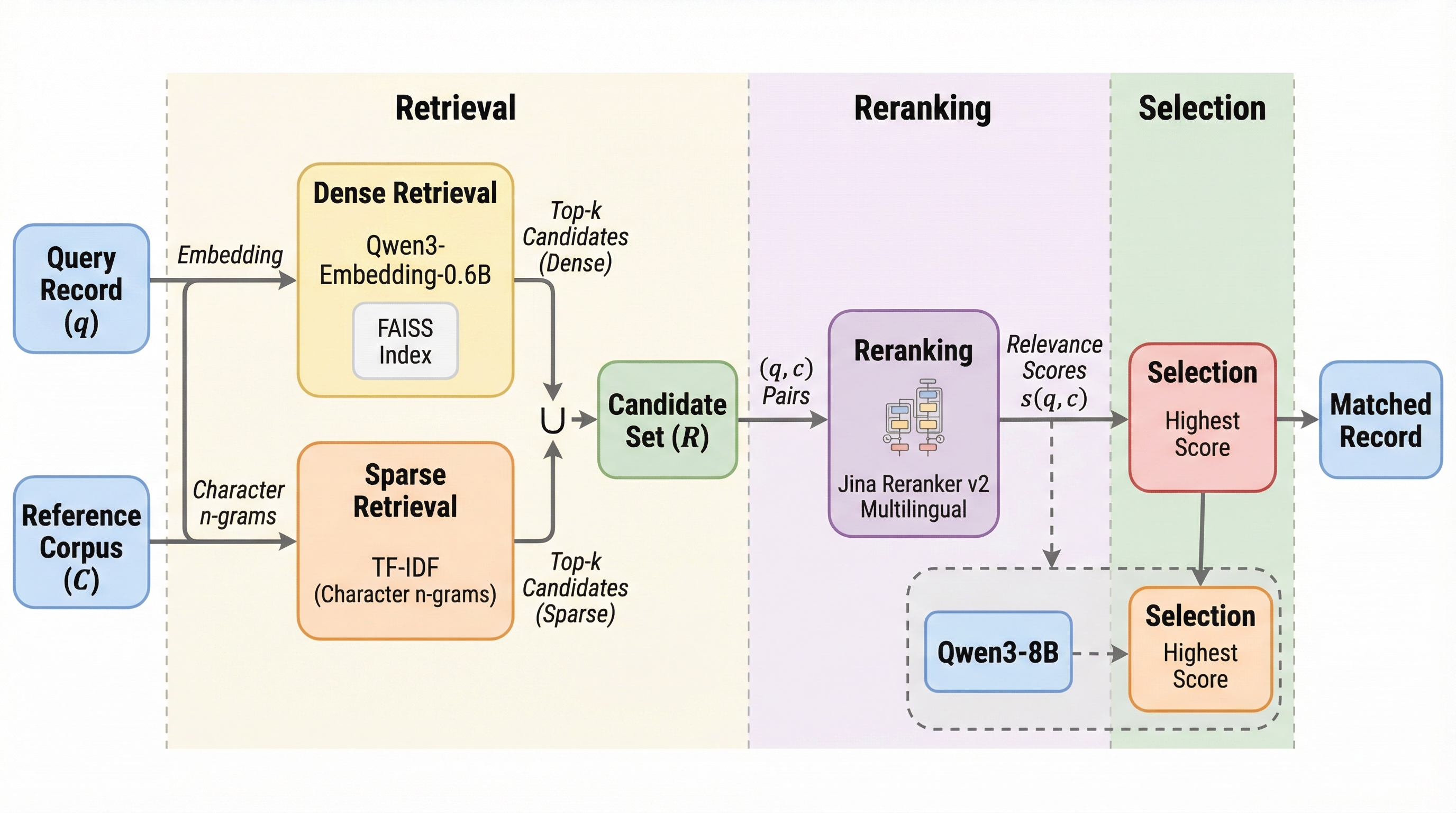
レコードリンケージは異なるデータセット間で同一の対象を照合する重要な工程だが、従来は場当たり的な規則や大量の学習データに依存しており、誤差の定量化も不十分であった。本論文が提案する「EnsembleLink」は、事前学習済み言語モデルのセマンティックな理解力を活用することで、学習データを一切使わずに、都市名や人名、組織名、多言語の政党名などの照合において教師あり学習手法と同等以上の高精度を達成した。 この手法は、密なベクトル検索と文字単位の疎な検索を組み合わせた候補抽出、およびクロスエンコーダによる高精度な再ランク付けという3段階のパイプラインで構成されており、オープンソースの軽量モデルを用いてローカル環境で実行できる。検証の結果、ニックネームや略称、非直訳の多言語対応など、従来のファジーマッチングでは困難だった複雑な照合を数分で完了させることが可能であり、社会科学などの実証研究におけるデータ統合の信頼性を大きく向上させる。 利用者は外部APIを呼び出すことなく、民生用ハードウェア上でプライバシーを保ちながら高速に処理を行うことができ、さらにモデルの重みが固定されているため結果の再現性も保証される。本手法は、都市名照合で90%、有権者照合で99%という極めて高い精度を記録しており、数千のラベルを必要とする既存の最先端手法に匹敵する性能をゼロショットで提供する画期的なツールである。
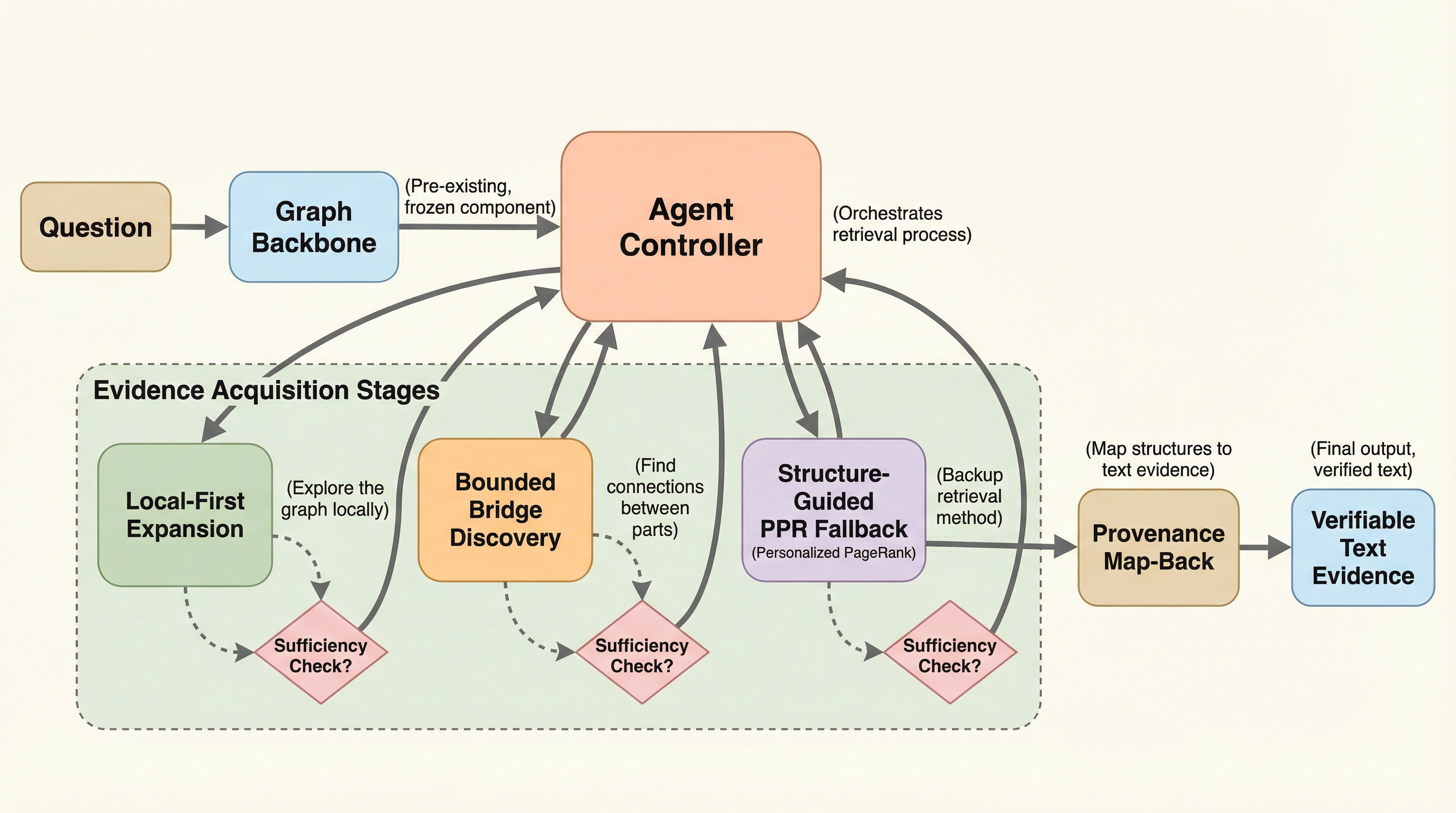
A2RAGは、従来のグラフRAGが抱えていた「一律の検索によるコストの浪費」と「グラフ化の際の細かな情報の欠落(抽出ロス)」という2つの課題を解決するために提案された、適応型かつエージェント型の新しい検索フレームワークである。
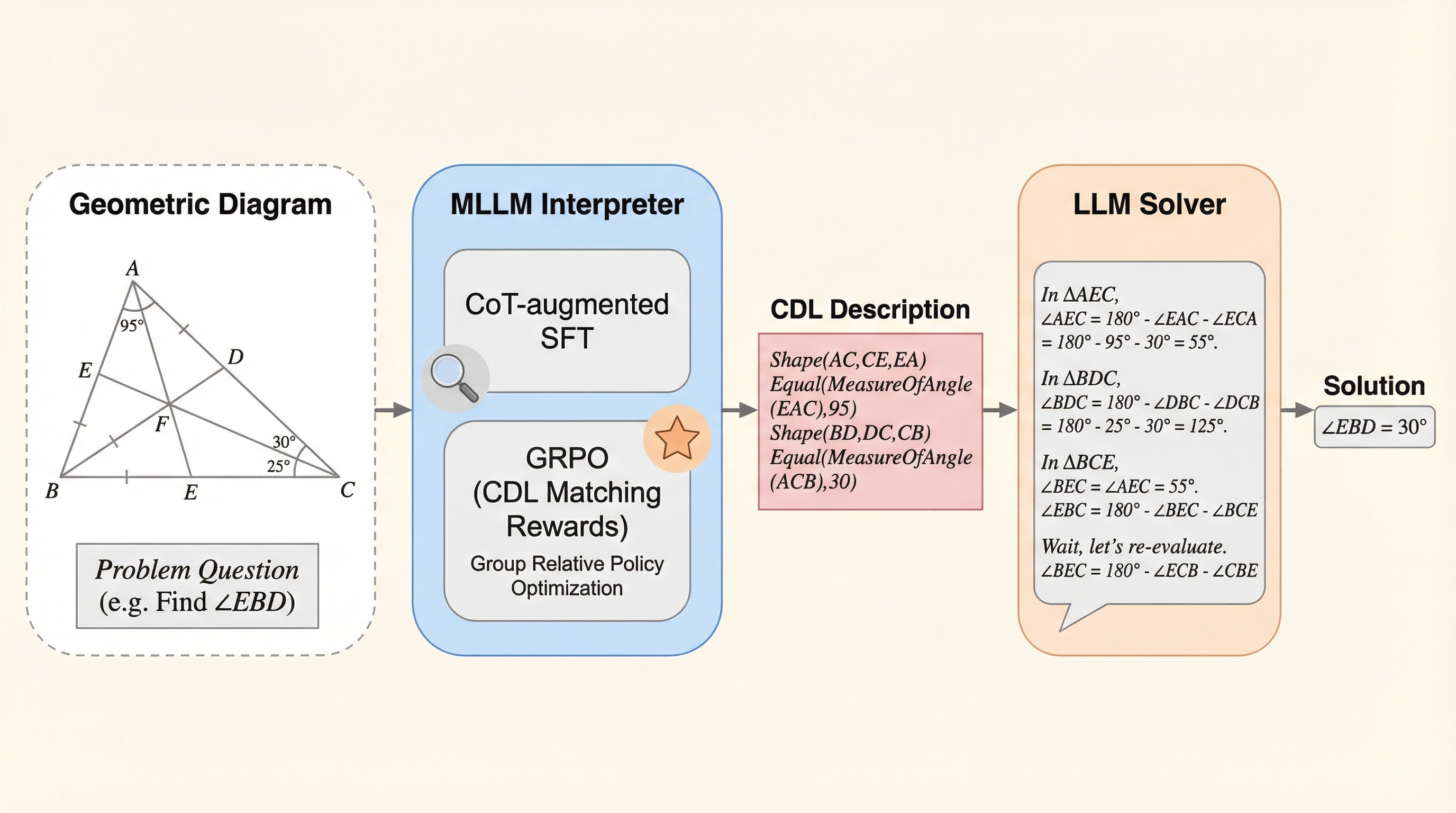
平面幾何問題(PGPS)において、マルチモーダルLLM(MLLM)が抱える視覚的誤認や推論能力の低下という課題を解決するため、幾何学図形を「条件宣言言語(CDL)」という簡潔なテキスト記述に変換し、それを既存の強力なLLMに読み込ませて解かせるという新しい推論パラダイムを提案しました。